Transforme insights em ação: observabilidade, automação e garantia impulsionadas por IA
No cenário empresarial dinâmico de hoje, as operações de TI devem evoluir da resolução reativa de problemas para insights proativos. À medida que nuvens híbridas, microsserviços e arquiteturas distribuídas redefinem a infraestrutura moderna, a entrega de experiências digitais perfeitas agora depende de uma observabilidade profunda e inteligente.
No entanto, as ferramentas de monitoramento convencionais muitas vezes ficam aquém. Elas fornecem visões isoladas, têm dificuldade para escalar ou sobrecarregam as equipes com alertas desconexos que mascaram a causa raiz. O que as empresas precisam é de uma plataforma de observabilidade unificada — que ofereça visibilidade contextual em todas as camadas do ecossistema de TI, conecte sinais a insights de maneira inteligente e permita respostas automatizadas e baseadas em dados quando for mais importante.
Com uma solução de observabilidade completa, você pode:
Obtenha visibilidade abrangente
Simplifique a análise da causa raiz
Garanta um desempenho confiável
Acelere a detecção e resolução de incidentes
Reduza os custos indiretos
Melhore a colaboração entre equipes
A observabilidade redefine a forma como as empresas compreendem e gerenciam ambientes de TI complexos, capacitando as equipes a passar do simples monitoramento do que aconteceu para descobrir por que isso aconteceu e prevenir proativamente que isso se repita.

Nosso reconhecimento no IDC MarketScape 2025
Temos o orgulho de compartilhar que a Zoho Corp. (ManageEngine) foi reconhecida como uma das principais empresas no IDC MarketScape: Avaliação de fornecedores de plataformas de observabilidade mundiais 2025 (doc. nº US53004325, novembro de 2025). Acreditamos que este é um reconhecimento significativo do nosso investimento e sucesso em levar práticas de observabilidade baseadas em IA para empresas em todo o mundo.
Acreditamos que a inclusão no IDC MarketScape destaca os pontos fortes da ManageEngine em áreas como:
- Observabilidade de ponta a ponta e correlação de eventos em ambientes híbridos e nativos da nuvem
- Detecção de anomalias, análise de causa raiz e insights preditivos baseados em IA/ML
- Orquestração de fluxo de trabalho e correção autônoma
- Escalabilidade, multilocação e preparação para nuvem sob medida para operações de grandes empresas
- Alinhamento da experiência do usuário e das operações para reduzir o impacto nos negócios
Vamos agora dar uma olhada em alguns dos nossos principais recursos de AIOps/observabilidade.
Nossos principais recursos de observabilidade
- Detecção de anomalias
- Análise preditiva baseada em IA/ML
- Insights baseados em IA generativa
- Recursos de plataforma
As empresas modernas não podem se dar ao luxo de operar de forma reativa. A ManageEngine utiliza a detecção de anomalias com tecnologia de IA para identificar padrões irregulares no desempenho de TI antes que eles se transformem em falhas críticas. Usando algoritmos avançados de ML, a ManageEngine analisa continuamente o comportamento da rede, do servidor e das aplicações para detectar desvios em relação às linhas de base de desempenho normais.
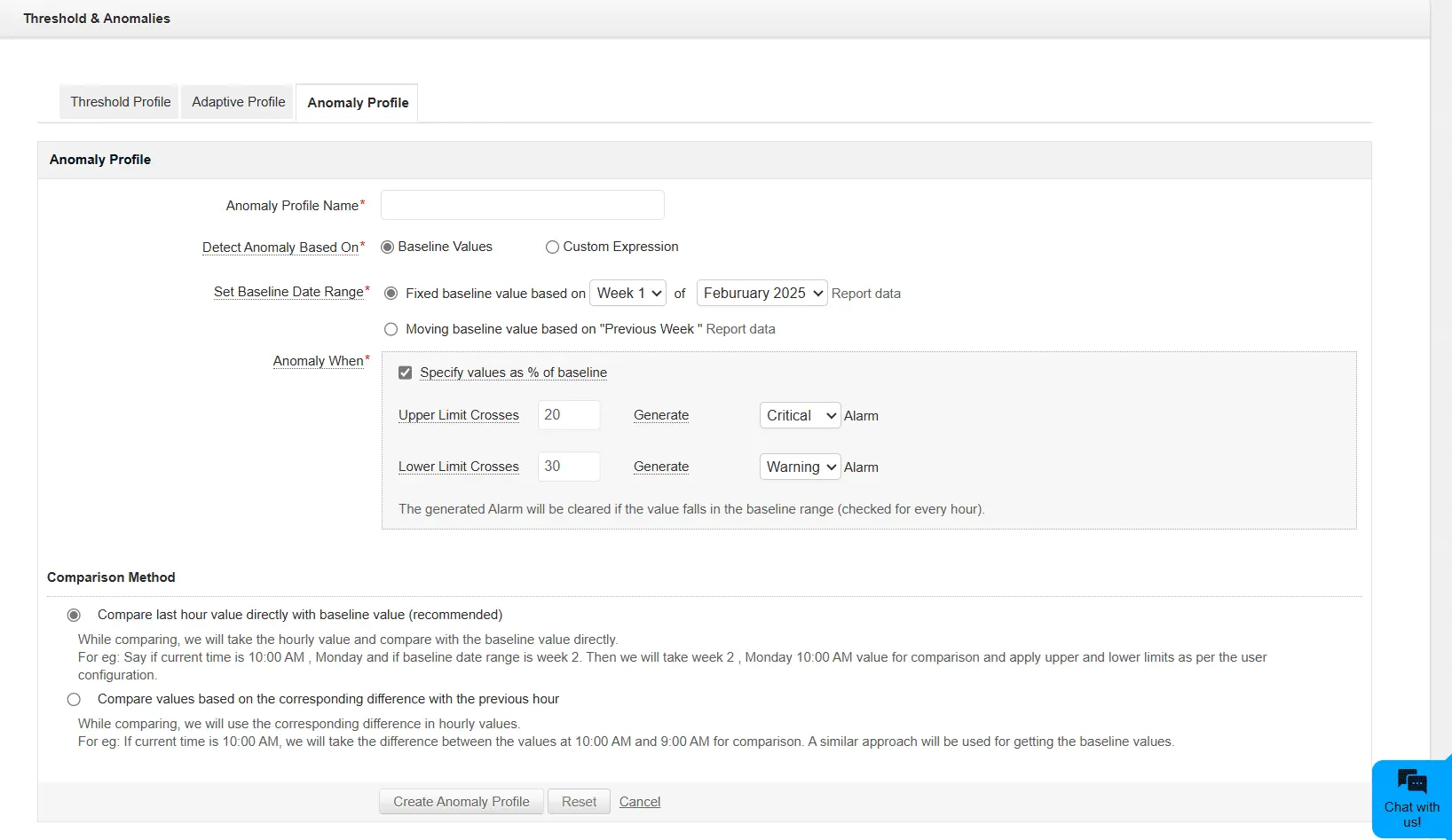
Monitoramento proativo
O sistema identifica valores atípicos em métricas como utilização da CPU, consumo de memória e tempos de resposta, ajudando as equipes de TI a resolver possíveis problemas antes que eles afetem as operações comerciais.
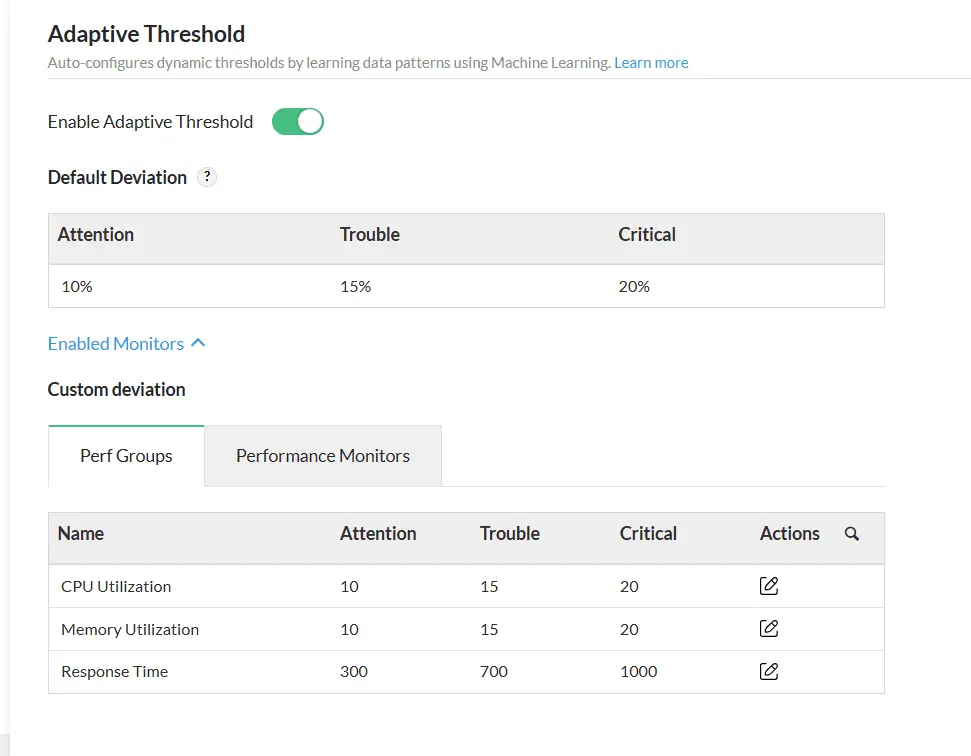
Thresholds dinâmicos
Ao contrário dos thresholds manuais tradicionais, os thresholds adaptativos da ManageEngine se ajustam dinamicamente, analisando os padrões de uso históricos e em tempo real da sua infraestrutura, garantindo que seu mecanismo de monitoramento seja sensível ao contexto.
Resposta aprimorada a incidentes
Ao detectar anomalias antecipadamente, as equipes de TI podem mitigar riscos de forma proativa, minimizar o tempo de inatividade e aumentar a confiabilidade geral do serviço.
A ManageEngine utiliza análises preditivas para ajudar os administradores de TI a antecipar falhas na infraestrutura, degradação do desempenho e restrições de recursos. Seus algoritmos internos de ML analisam continuamente o comportamento da infraestrutura ao longo do tempo, identificando padrões para prever possíveis problemas. Essas informações preditivas permitem a detecção proativa de falhas, permitindo que os administradores resolvam gargalos de recursos e anomalias de desempenho de forma preventiva. Além disso, a ManageEngine recomenda ações corretivas para mitigar riscos e garantir o desempenho ideal da infraestrutura.
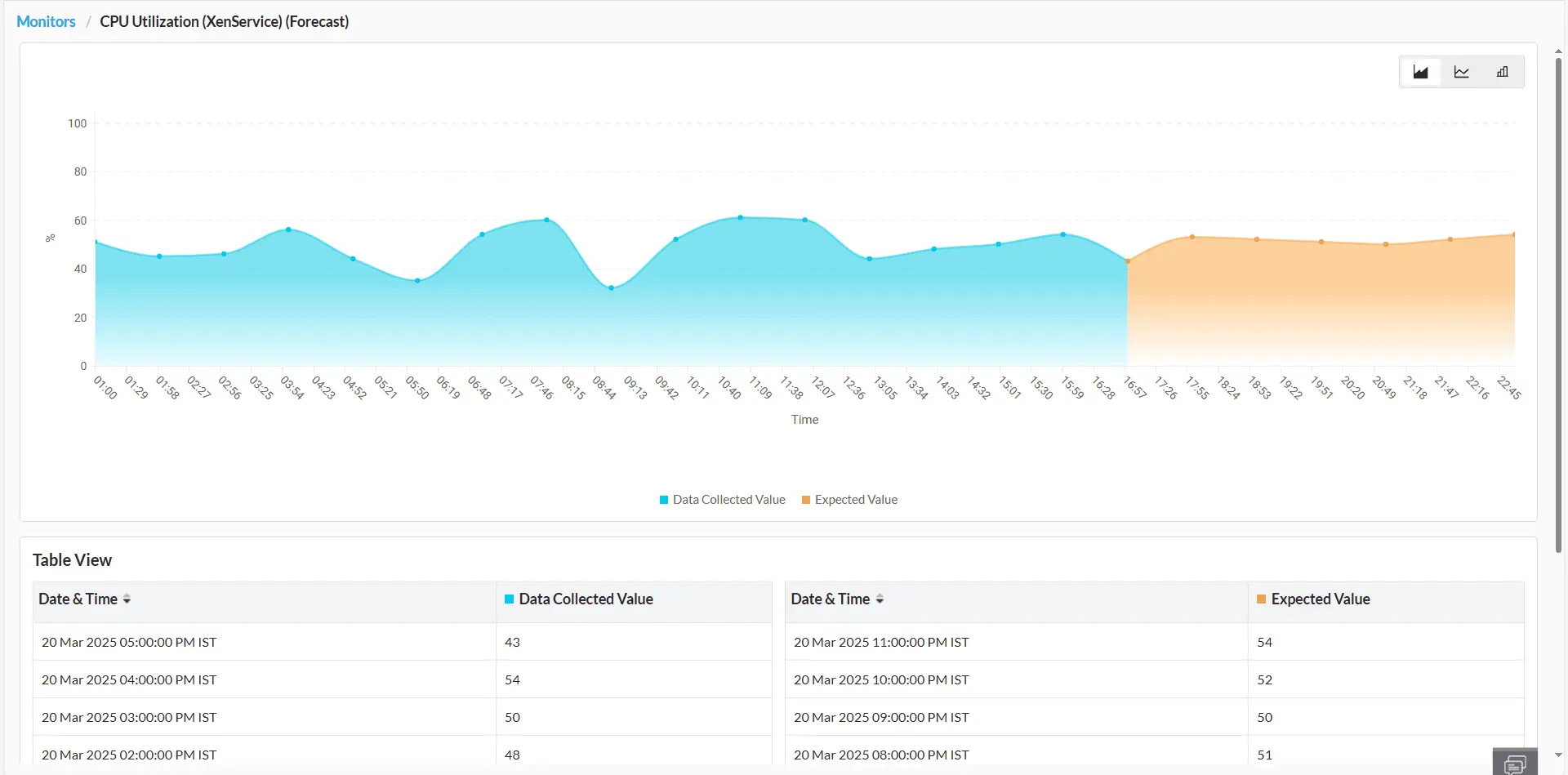
Previsão de tendências de desempenho
Utilize algoritmos baseados em IA para prever com precisão as tendências futuras de desempenho da infraestrutura, permitindo medidas proativas para se alinhar às demandas em evolução do seu ambiente de TI. Saiba mais.
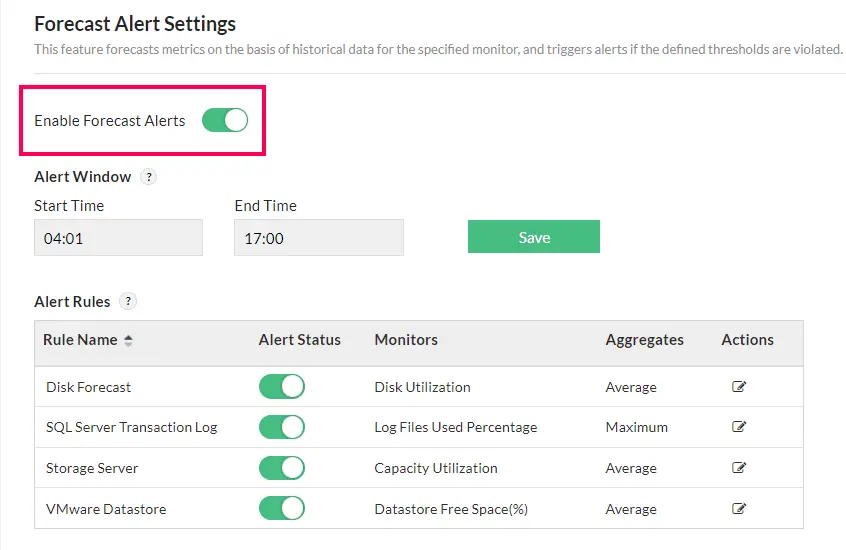
Alertas de previsão
Fique à frente do esgotamento de recursos, prevendo o tempo estimado até que os recursos de rede atinjam thresholds críticos. Essa previsão é derivada da observação contínua dos padrões de uso de recursos ao longo do tempo e analisada por meio de um mecanismo de previsão avançado. Com base nessas previsões, alertas proativos são acionados, permitindo que os administradores de rede mitiguem riscos e implementem estratégias eficazes de planejamento de capacidade. Saiba mais.
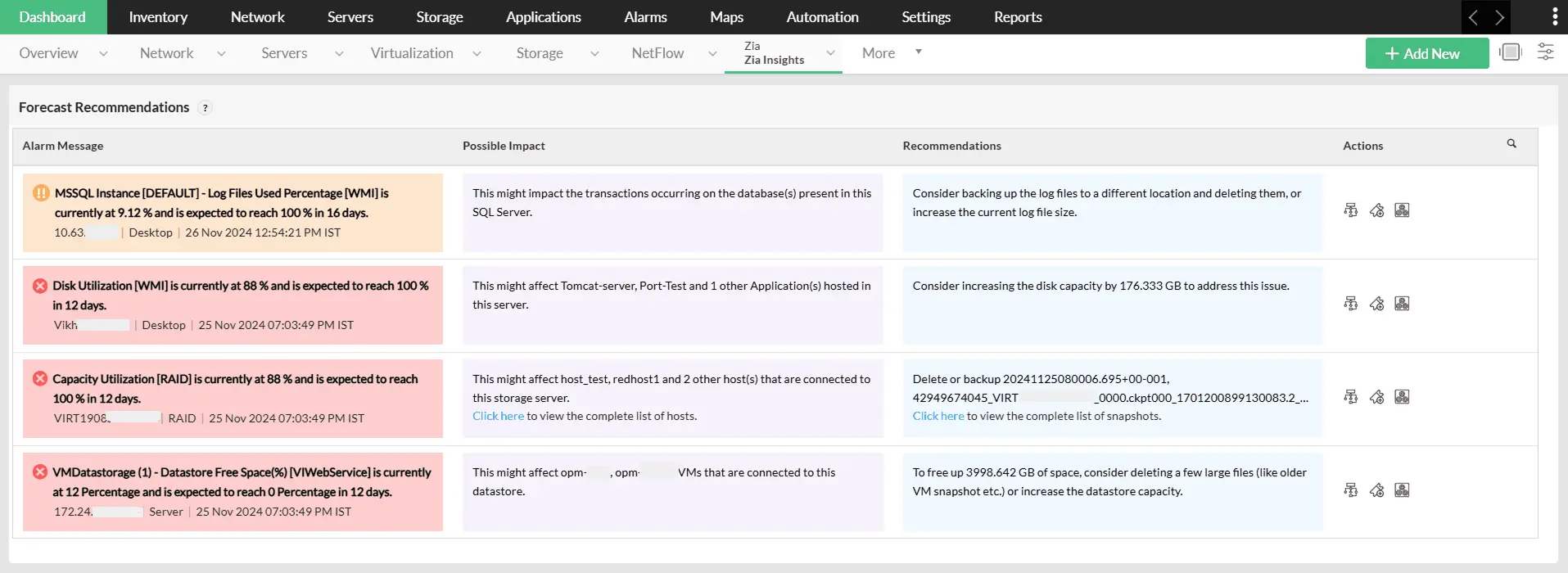
Dashboards da Zia Insights
Transforme os gargalos previstos em insights acionáveis com os dashboards da Zia Insights. Receba recomendações baseadas em IA sobre falhas previstas na infraestrutura e fique à frente da curva, capacitando suas equipes de TI a agir de forma proativa e mitigar falhas antes mesmo que elas ocorram. Saiba mais.
Aproveite o poder da IA generativa para transformar dados brutos de observabilidade em inteligência acionável. De recomendações preditivas a interfaces conversacionais, esses recursos ajudam as equipes a trabalhar de forma mais inteligente, sem esforço adicional.
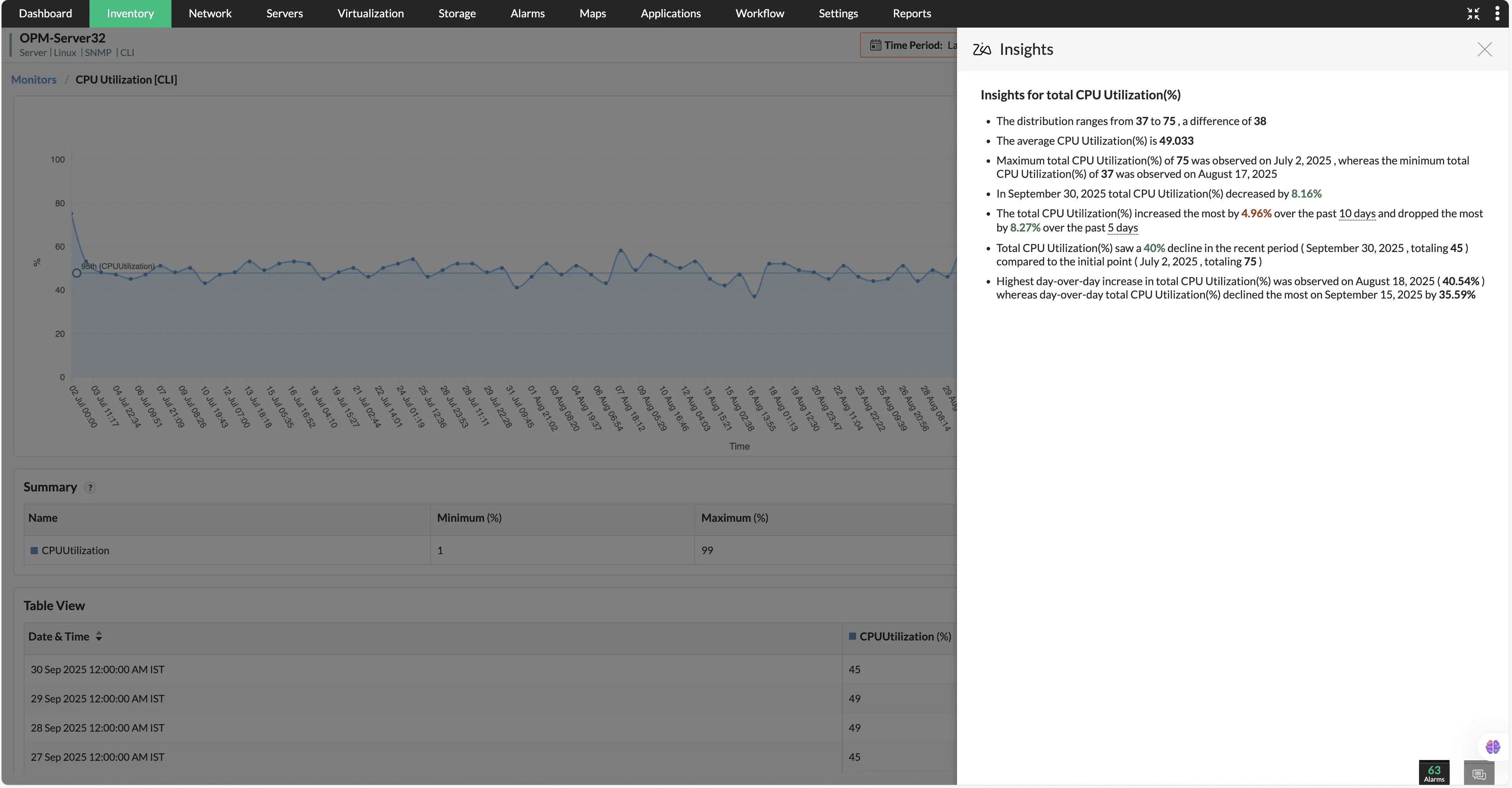
Zia Insights
Transforme facilmente dados brutos e complexos em insights claros e acionáveis. Com nosso modelo interno de IA, as equipes de TI podem analisar o desempenho dos dispositivos por meio de resumos concisos e legíveis, em vez de vasculhar gráficos e pontos de dados densos.
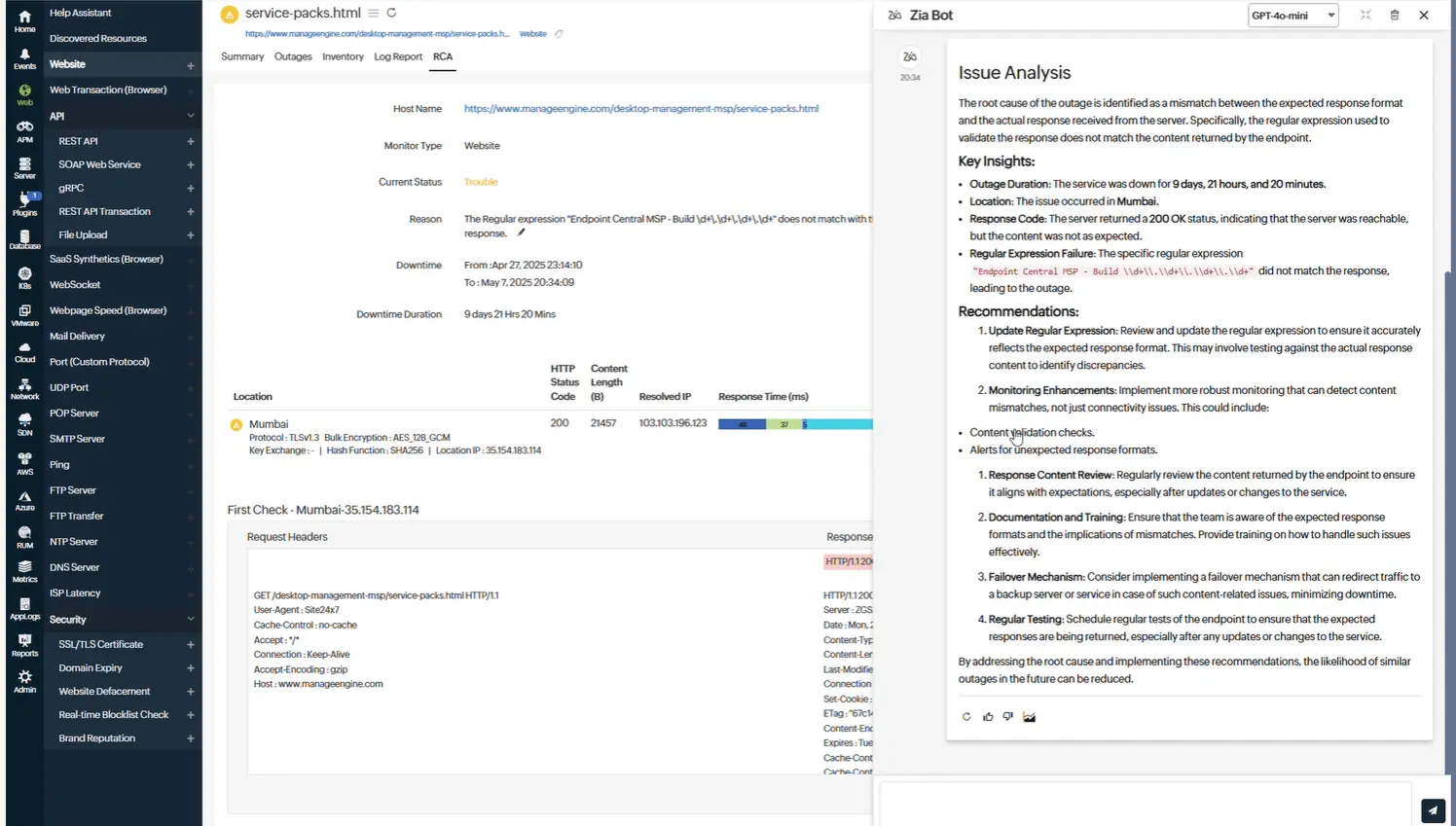
Análise automatizada da causa raiz (RCA)
Com tecnologia avançada de LLMs, a plataforma correlaciona automaticamente os dados de telemetria entre métricas, registros e rastreamentos para identificar as causas raiz mais prováveis. Isso acelera o isolamento de falhas e minimiza o tempo de inatividade, eliminando as suposições do processo de solução de problemas.
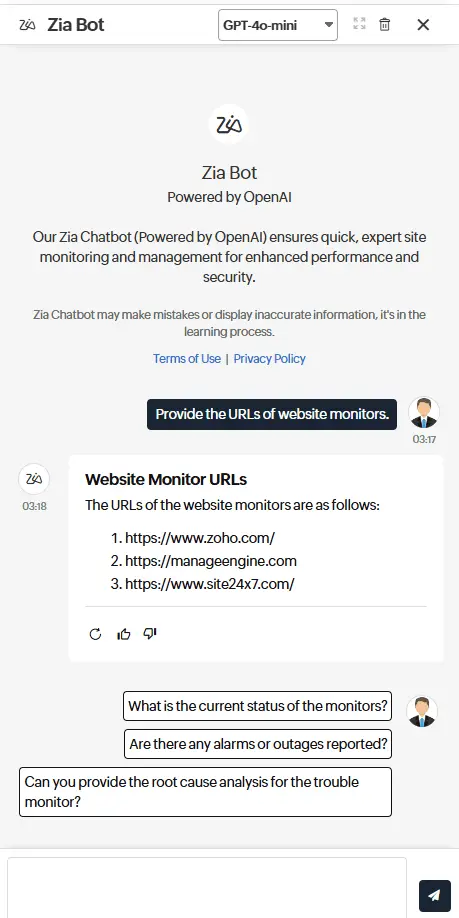
Interface de chat em linguagem natural
Interaja com seus dados de observabilidade por meio de um chatbot conversacional. Use linguagem simples para consultar logs, métricas e rastreamentos ou gerar resumos legíveis de incidentes e anomalias, facilitando a compreensão e a ação rápida das equipes.
Nossa plataforma capacita as equipes de TI com observabilidade de ponta a ponta em toda a infraestrutura, aplicações e serviços, fornecendo uma visão unificada que elimina os silos operacionais. Ao consolidar métricas, eventos e telemetria de várias fontes, ela permite insights mais rápidos, monitoramento proativo e operações simplificadas, garantindo que as equipes de TI e DevOps possam gerenciar ambientes complexos com eficiência e manter o desempenho ideal dos serviços.
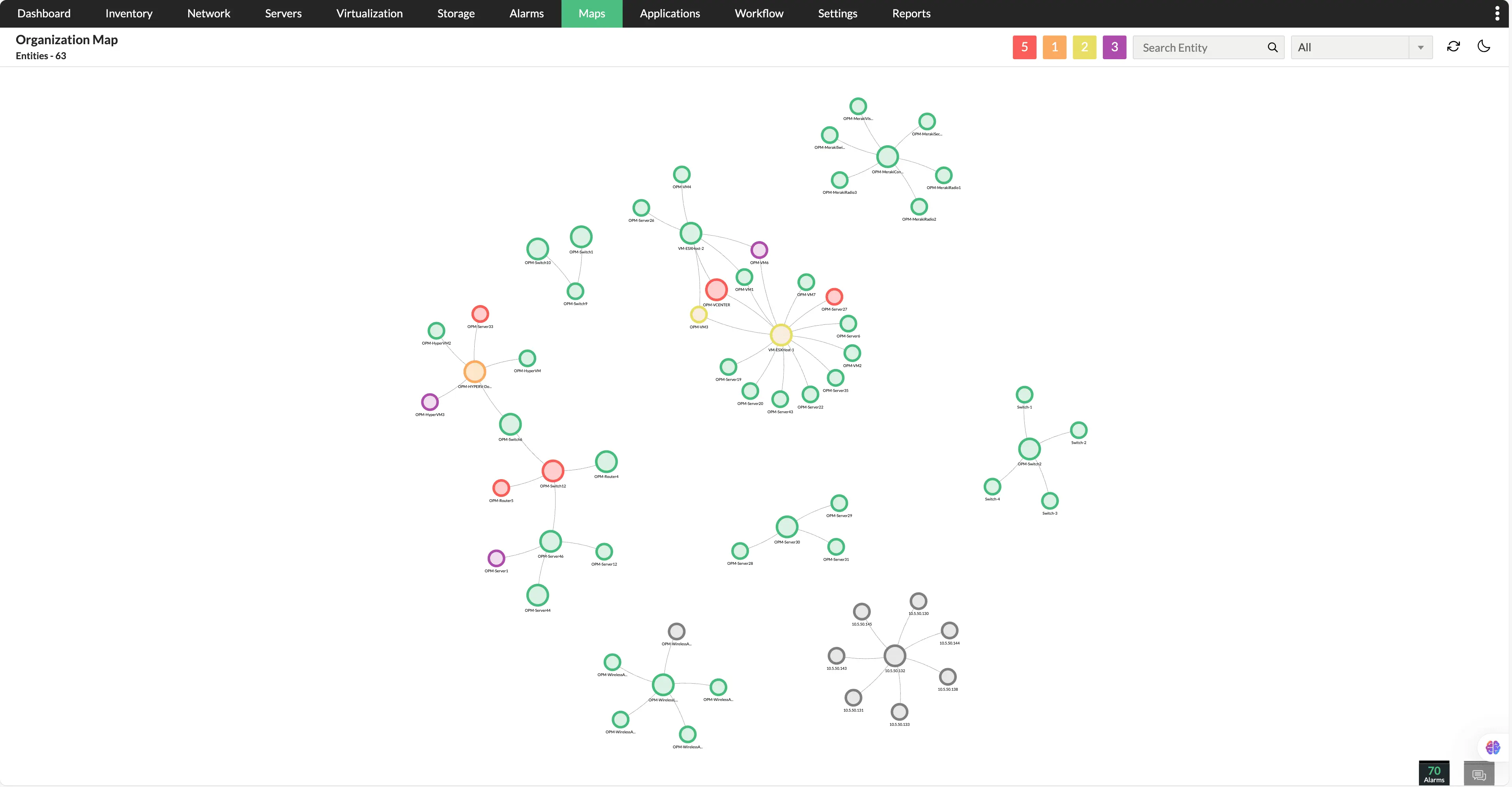

Visão full-stack da topologia
Obtenha uma visão dinâmica e em tempo real da topologia da sua infraestrutura, mostrando as relações entre dispositivos, aplicações e serviços. Em vez de navegar por pontos de dados dispersos, as equipes de TI podem ver as dependências rapidamente, o que as ajuda a identificar áreas problemáticas, compreender o impacto potencial e otimizar os esforços de solução de problemas.
Ecossistema de TI unificado
Integre-se perfeitamente com plataformas ITSM, ferramentas de colaboração e serviços em nuvem para centralizar o monitoramento e a resposta a incidentes.
Integrações personalizadas e fluxos de trabalho automatizados
Use integrações personalizadas, API ou webhook para personalizar o troubleshooting. Aproveite os fluxos de trabalho automatizados e baseados em gatilhos para implementar medidas de correção de falhas de nível 1.
5 razões pelas quais empresas em todo o mundo escolhem a ManageEngine

- Confiável: mais de 20 anos de presença no mercado
- Custo-benefício: melhores recursos por um preço menor
- Seguro: em conformidade com os principais padrões e regulamentações
- Modernizado: recursos de monitoramento e segurança de última geração
- Conveniente: automação avançada e interface intuitiva
Confiado por 1 milhão de administradores de TI em todo o mundo
As principais marcas globais confiam em nós para suas necessidades de TI
Amado pelos clientes em todo o mundo
“Ferramenta de fácil implementação, com excelente suporte e de baixo custo - Líder de equipe, setor de serviços de TI”
Função do avaliador: Infraestrutura e operações
Porte da empresa: 500M - 1B USD
Estamos usando o OpManager desde 2011 e, em geral, nossa experiência tem sido excelente. A ferramenta desempenha um papel fundamental no fornecimento de valor para nossa empresa e para nossos clientes. O suporte é excelente e a equipe assume total responsabilidade na resolução de problemas. A inovação nunca para e está claramente visível nas versões mais recentes.
“OpManager - 10 passos à frente da concorrência, a um passo de ser inigualável - Gerente de serviços de rede, organização governamental”
Função do avaliador: Infraestrutura e operações
Porte da empresa: 5.000 a 50.000 colaboradores
Tenho uma relação de longa data com a ManageEngine. Sempre faltou um ou dois recursos no OpManager que fariam dele a melhor ferramenta do mercado, mas, no geral, é o produto mais completo e fácil de usar do mercado.
“Fácil de implementar e com um catálogo cheio de recursos, o suporte ainda pode melhorar - Gerente de NOC, setor de serviços de TI”
Função do avaliador: Gerenciamento de programa e portfólio
Porte da empresa: 500M - 1B USD
O fornecedor tem dado suporte durante as fases de implementação e POC, fornecendo licenças de teste. As solicitações de recursos e feedbacks geralmente são atendidas rapidamente. Recebemos o suporte necessário do fornecedor durante a fase de implementação. Após a implementação, o suporte é mais que suficiente, mas o fornecedor poderia fazer algumas melhorias.
“Ótima ferramenta de monitoramento - CIO no setor financeiro”
Função do avaliador: CIO
Porte da empresa: 1B a 3B USD
A ManageEngine fornece um conjunto de ferramentas que fizeram melhorias na disponibilidade de nossas aplicações internas. Com o monitoramento, o gerenciamento e os alertas, conseguimos atingir o desempenho máximo em nosso data center.
“A implementação é simples, fácil de usar. Muito intuitivo. - Engenheiro principal em serviço de TI”
Função do avaliador: Arquitetura empresarial e inovação tecnológica
Porte da empresa: 250M - 500M USD
O suporte da ManageEngine respondeu a todas as nossas perguntas.

“O OpManager me ajuda a monitorar todos os aspectos do data center e equipamentos, como servidores, switches e roteadores. É rápido, intuitivo e centralizado e você não precisa ser um especialista para lidar com o OpManager.”
Altaleb Alshenqiti
NGHA

“Donald Stewart, gerente de TI da Crest Industries, está feliz com o OpManager da ManageEngine devido ao seu software de monitoramento de rede de ponta a ponta. Ele é fácil de usar e oferece gerenciamento de falhas e desempenho para o roteador.”
Donald Stewart
gerente de TI, Crest Industries

“John Rosser, gerente de MIS da Yale Chase, fala sobre a natureza proativa do OpManager da ManageEngine e como sua organização ganhou valor com ele.”
John Rosser
Gerente de MIS