INCIDENT CONTROL & OWNERSHIP
Take ownership of alarms from detection to resolution
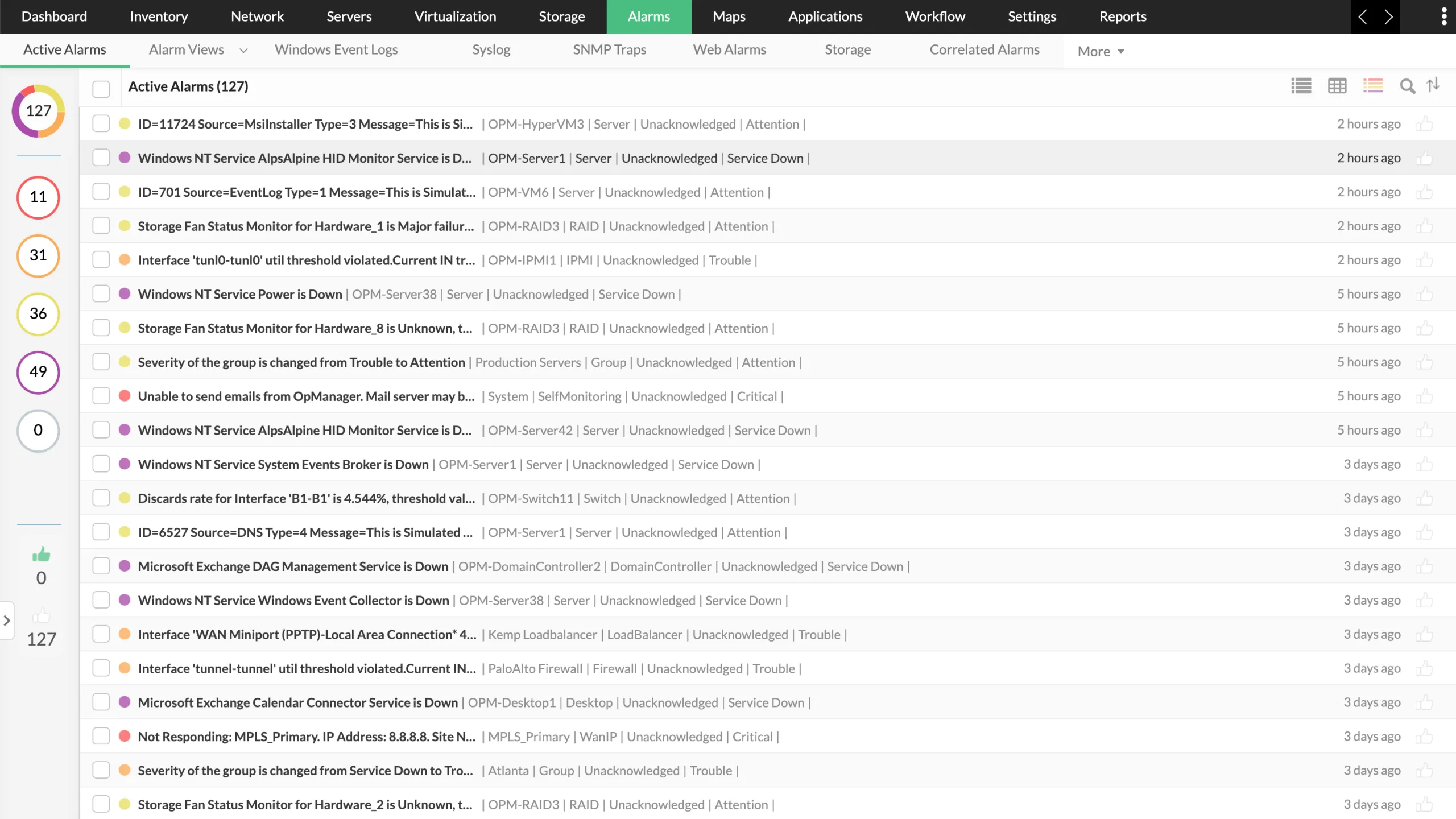
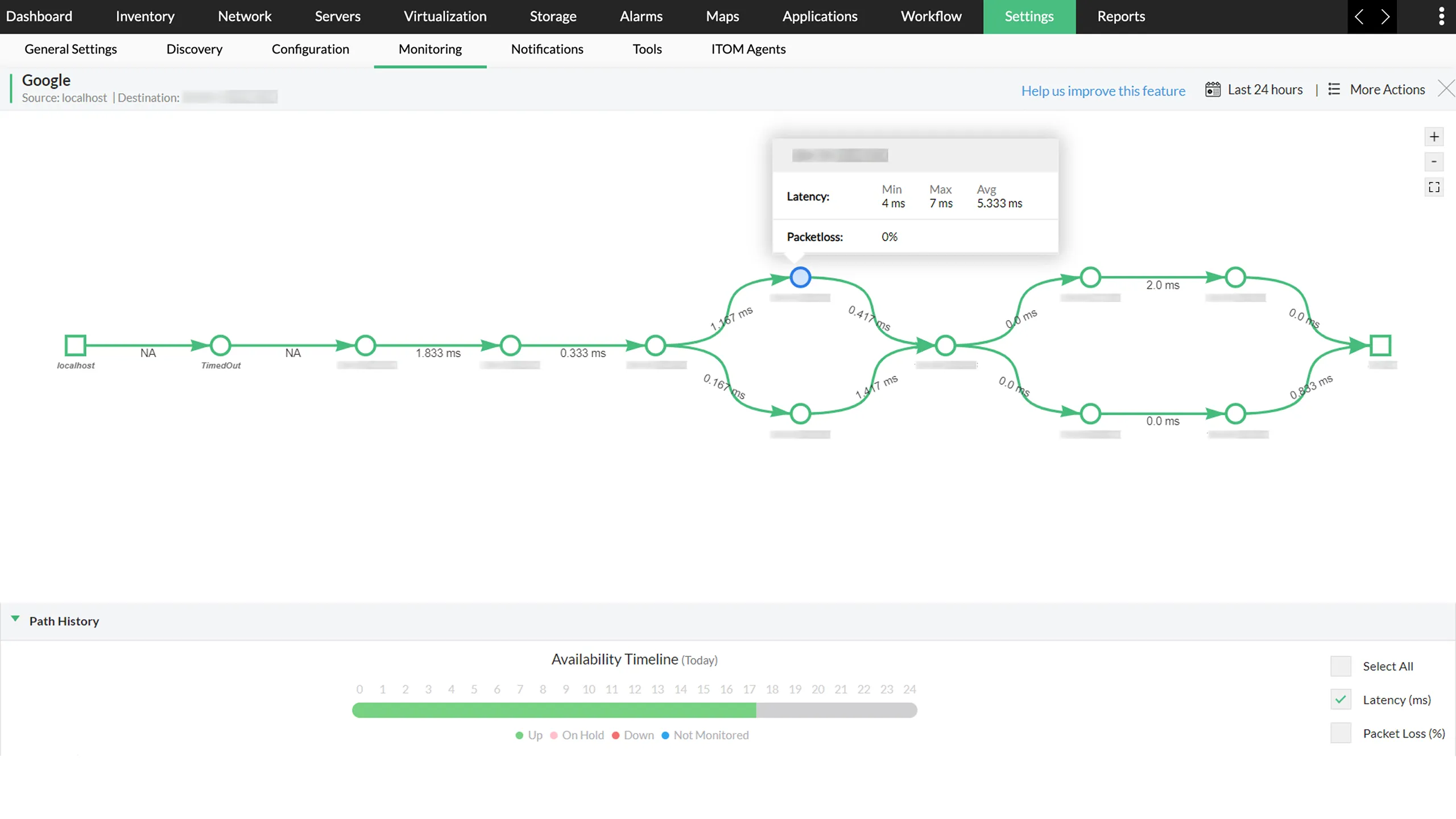
In large networks, NOC dashboards can get overwhelmed with alerts during outages. Without clear ownership, engineers might investigate the same issue multiple times or, worse, miss a critical fault entirely.
OpManager helps teams bring clarity and accountability to every incident:
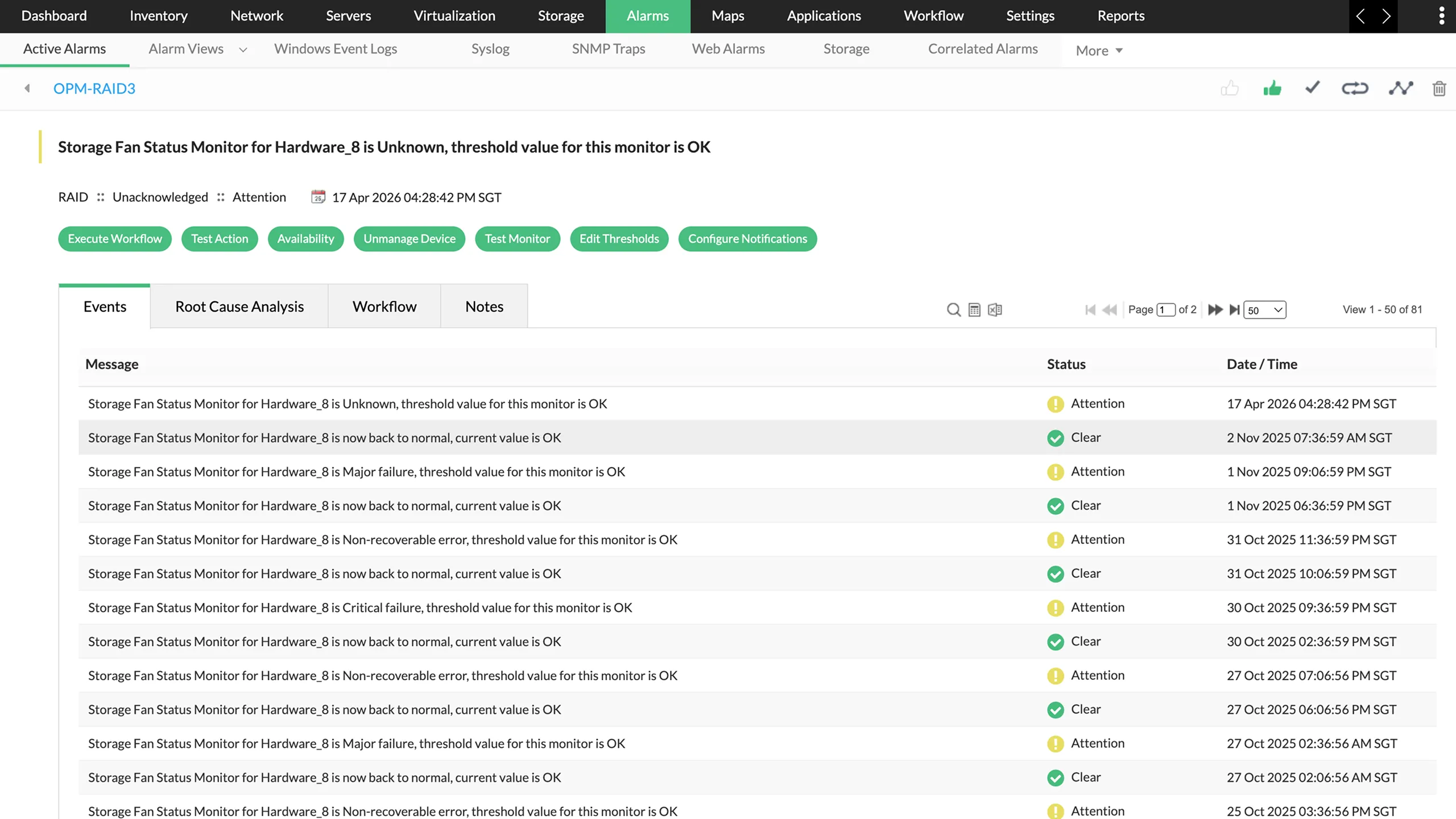
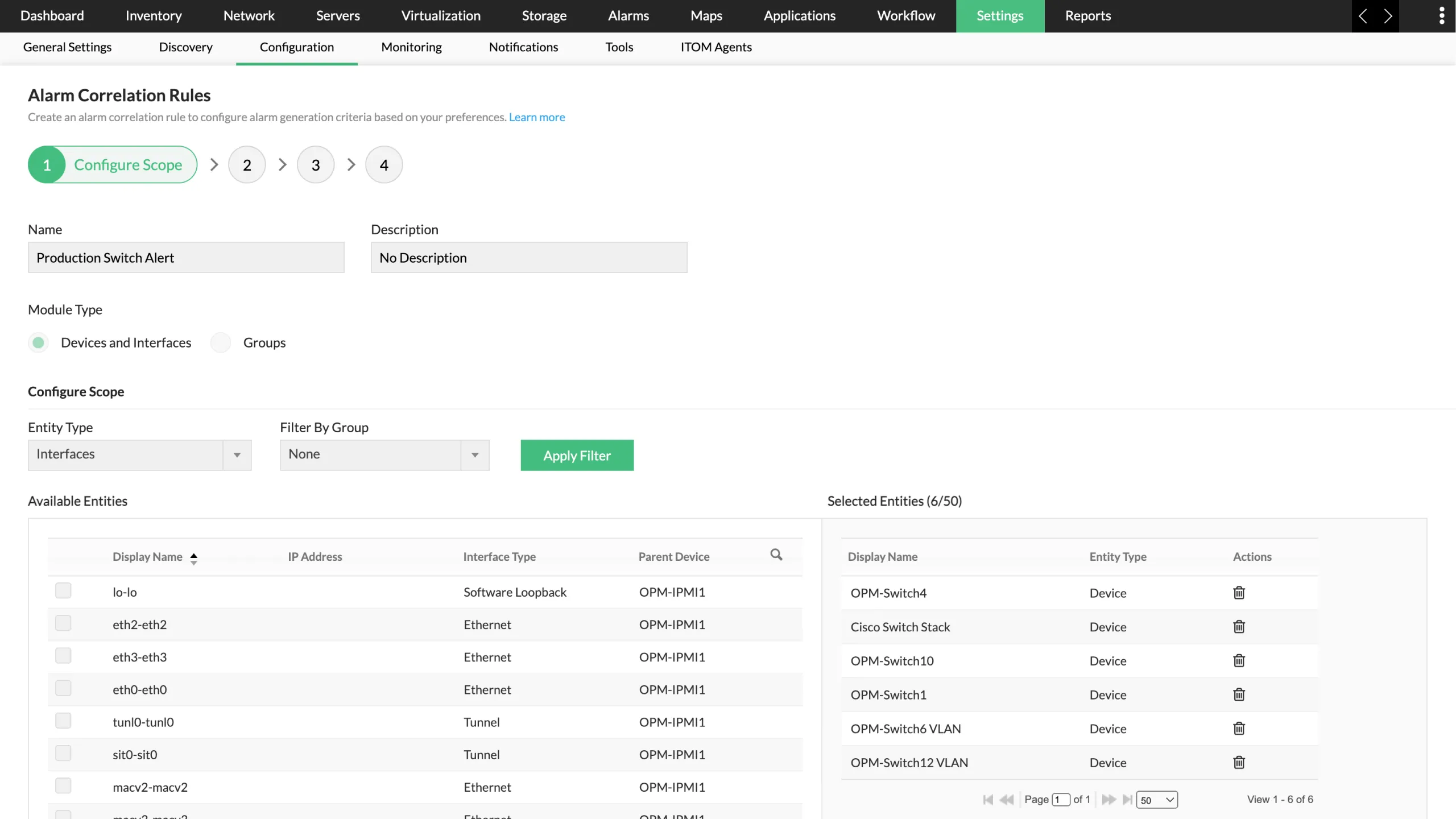
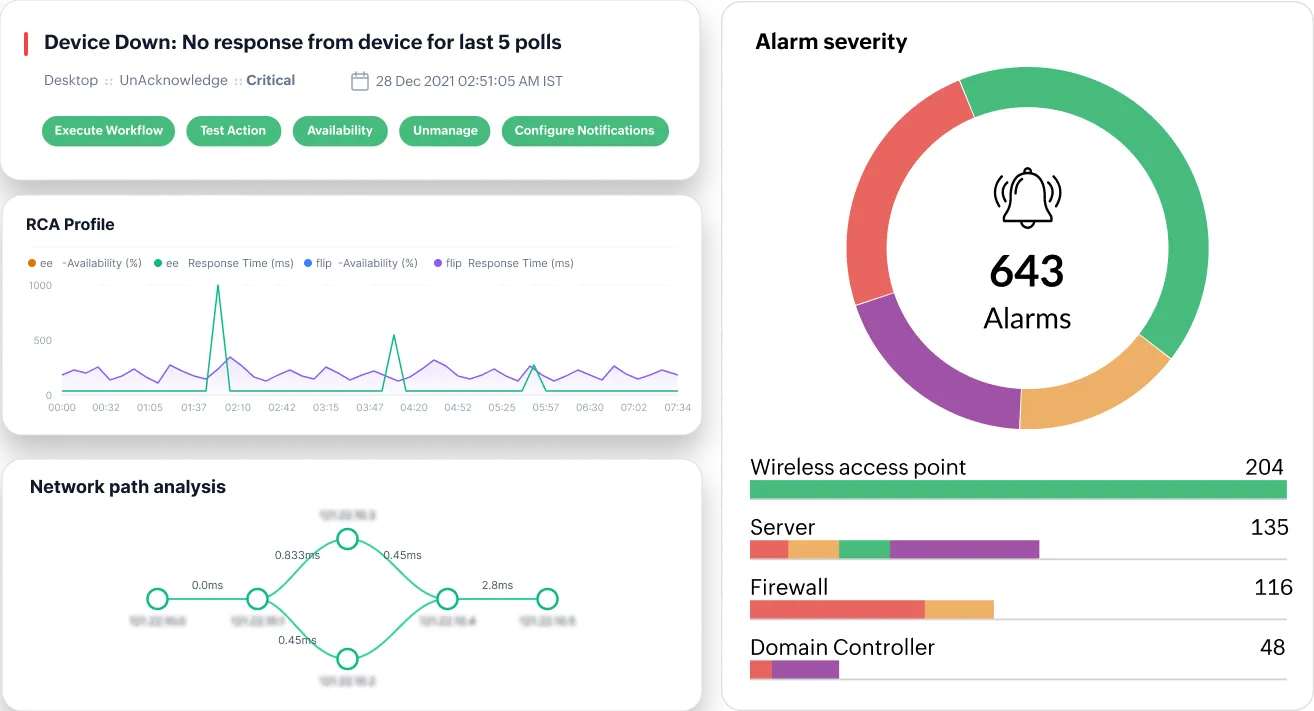
- Turn alerts into accountable incidents: Acknowledge alarms and assign them to the right engineer so every fault has someone responsible for resolution.
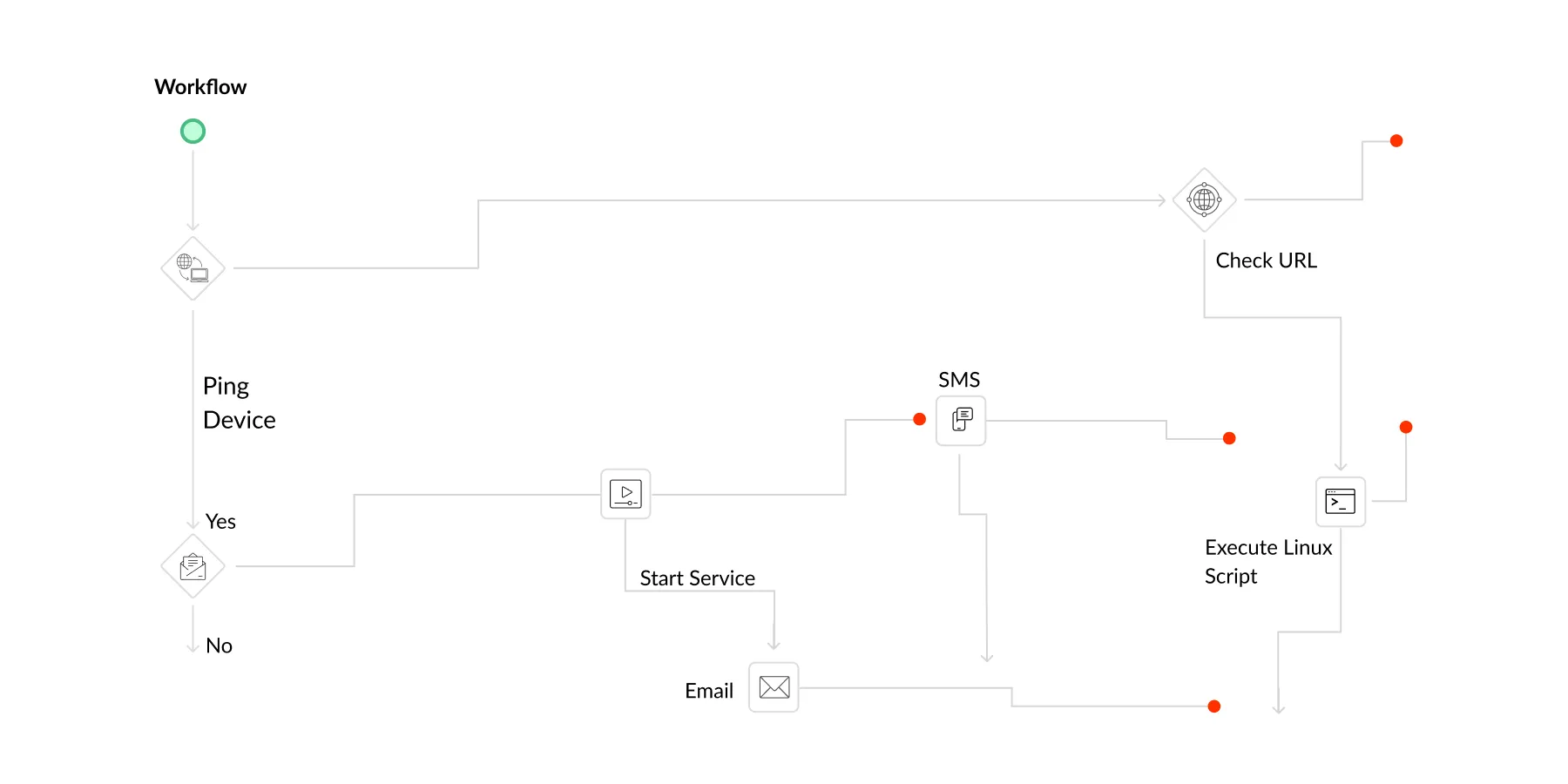
- Track the full incident lifecycle: Monitor issues from detection to acknowledgement, investigation, and closure, all within a single, unified workflow.
- Stay in control during alert storms: See at a glance which issues are active, who’s handling them, and which require immediate attention.