Từ Insight đến Action:
Observability, automation và assurance cùng AI
Trong bối cảnh doanh nghiệp đầy biến động, vận hành CNTT phải chuyển mình từ xử lý sự cố bị động sang khai thác insight chủ động. Khi hybrid cloud, microservices và distributed architectures (kiến trúc phân tán) đang tái định nghĩa lại hạ tầng hiện đại thì việc mang đến trải nghiệm số liền mạch sẽ phụ thuộc vào khả năng quan sát (observability) chuyên sâu và thông minh.
Tuy nhiên, các công cụ giám sát truyền thống thường không đáp ứng được yêu cầu vì chỉ cung cấp góc nhìn rời rạc, khó mở rộng hoặc tạo ra quá nhiều cảnh báo không liên quan, che lấp nguyên nhân gốc rễ. Điều mà doanh nghiệp cần là một nền tảng observability hợp nhất — cung cấp khả năng quan sát theo ngữ cảnh trên mọi lớp của hệ sinh thái CNTT, kết nối tín hiệu với insight một cách thông minh, kích hoạt phản hồi tự động dựa trên dữ liệu vào đúng thời điểm.
Với một giải pháp observability toàn diện, bạn có thể:
Quan sát tổng thể
Phân tích nguyên nhân gốc rễ nhanh chóng
Đảm bảo hiệu suất ổn định
Rút ngắn thời gian phát hiện
và xử lý sự cố
Tiết kiệm chi phí vận hành
Tăng cường cộng tác
giữa các team
Observability đang tái định nghĩa cách doanh nghiệp hiểu và quản lý các môi trường CNTT phức tạp — giúp đội ngũ chuyển từ việc chỉ giám sát “sự cố gì đã xảy ra” sang khám phá “vì sao sự cố này xảy ra”, để chủ động chòng chống trước khi sự cố này tái diễn.

Sự ghi nhận trong
IDC MarketScape 2025
Chúng tôi tự hào thông báo rằng Zoho Corp. (ManageEngine) được công nhận là Major Player trong báo cáo IDC MarketScape: Worldwide Observability Platforms 2025 Vendor Assessment (Tài liệu #US53004325, Tháng 11/2025). Đây là sự ghi nhận quan trọng cho những nỗ lực đầu tư và thành quả của chúng tôi trong hành trình mang các ứng dụng observability phát triển dựa trên AI đến các doanh nghiệp trên toàn thế giới.
Báo cáo IDC MarketScape đã đề cập ManageEngine qua những điểm vượt trội các khía cạnh như:
- Observability end-to-end, tương quan sự kiện trên môi trường hybrid và cloud-native
- Phát hiện bất thường, phân tích nguyên nhân gốc rễ và dự đoán bằng AI/ML
- Điều phối workflow và tự động khắc phục sự cố (autonomous remediation)
- Khả năng mở rộng, đa phiên (multi-tenancy) và cloud-readiness, phù hợp với quy mô vận hành doanh nghiệp lớn
- Nâng cao trải nghiệm người dùng và vận hành đồng bộ nhằm giảm thiểu tác động đến hoạt động kinh doanh
Bây giờ, hãy cùng điểm qua một số tính năng cốt lõi về AIOps và Observability của chúng tôi.
Những tính năng observability cốt lõi
của chúng tôi
- Phát hiện bất thường
- Phân tích dự đoán dựa trên AI/ML
- Insight dựa trên Gen AI
- Tính năng nền tảng
Hiểu được rằng, doanh nghiệp hiện đại cần vận hành theo hướng chủ động. ManageEngine ứng dụng công nghệ AI-powered anomaly detection để nhận diện những hoạt động bất thường trước khi chúng leo thang thành sự cố nghiêm trọng. Ứng dụng các thuật toán ML tinh vi - ManageEngine liên tục phân tích hành vi hệ thống, máy chủ và ứng dụng để phát hiện các sai lệch so với hiệu suất tiêu chuẩn.
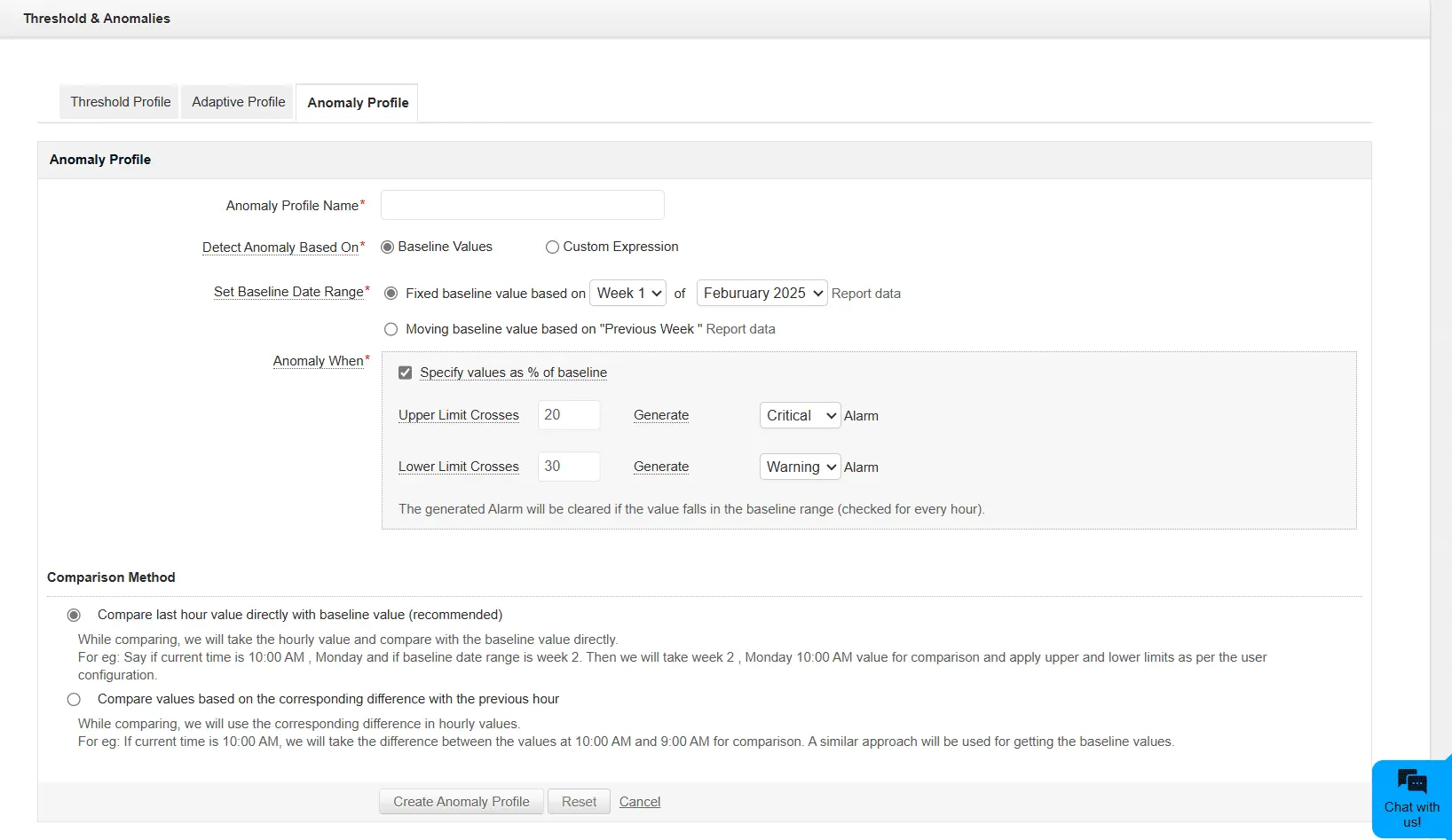
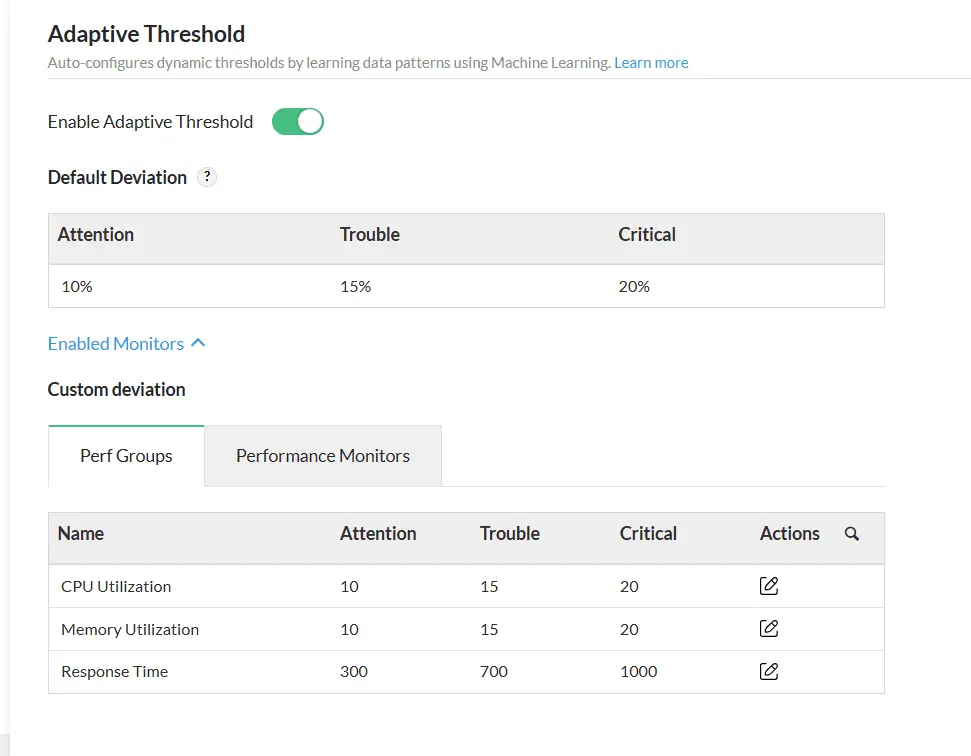
Giám sát chủ động
Hệ thống xác định các chỉ số bất thường của mức sử dụng CPU, mức tiêu thụ bộ nhớ và thời gian phản hồi - giúp đội ngũ CNTT xử lý các vấn đề tiềm ẩn trước khi gây ảnh hưởng đến hoạt động kinh doanh.
Thresholds tự động
Khác với ngưỡng thủ công truyền thống, ngưỡng thích ứng của ManageEngine sẽ tự động điều chỉnh dựa theo kết quả phân tích dữ liệu sử dụng theo thời gian thực và lịch sử, giúp cơ chế giám sát trở nên nhạy theo ngữ cảnh hơn.
Cải thiện khả năng phản hồi sự cố
Khi phát hiện bất thường sớm, đội ngũ CNTT có thể chủ động giảm thiểu rủi ro, hạn chế downtime và nâng cao độ tin cậy của dịch vụ.
ManageEngine khai thác predictive analytics để giúp admin IT chủ động dự đoán các lỗi hạ tầng, tình trạng suy giảm hiệu suất và giới hạn tài nguyên. Các thuật toán ML được phát triển nội bộ liên tục sẽ phân tích hành vi hạ tầng theo thời gian, nhận diện các mô hình để dự báo những vấn đề tiềm ẩn.
Những insight dự đoán này cho phép phát hiện lỗi sớm, giúp quản trị viên chủ động xử lý các điểm nghẽn tài nguyên và bất thường hiệu suất. Bên cạnh đó, ManageEngine còn đề xuất các hành động khắc phục nhằm giảm thiểu rủi ro và đảm bảo hiệu suất hạ tầng tối ưu.
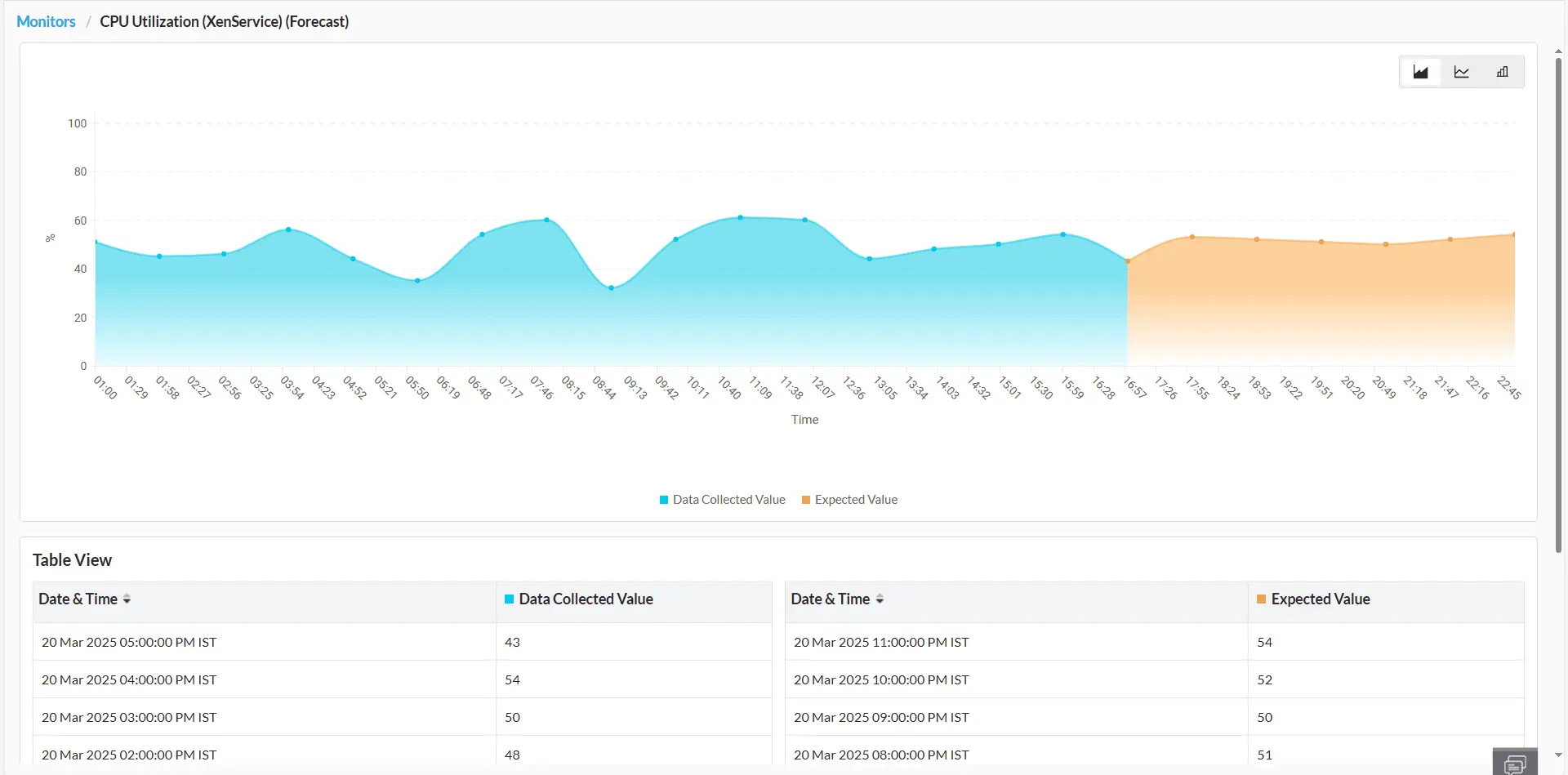
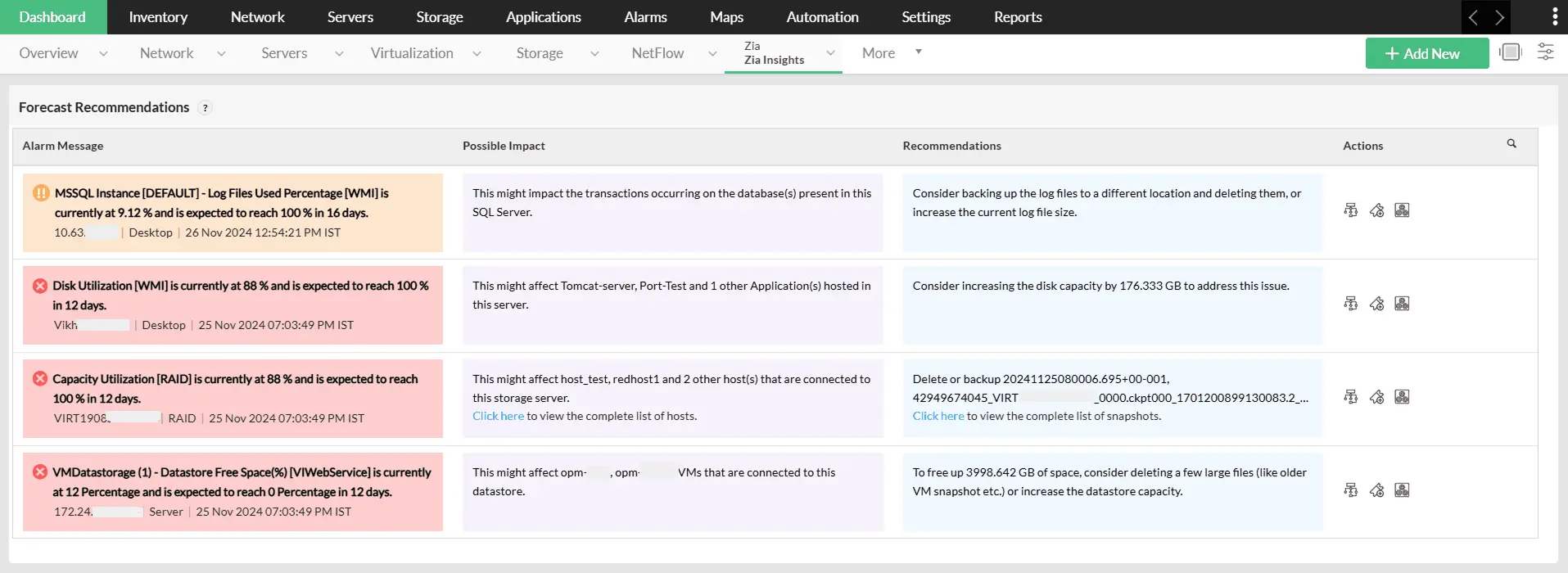
Dự báo performance trend
Sử dụng các thuật toán AI để dự đoán chính xác xu hướng hiệu suất của hạ tầng trong tương lai, giúp bạn triển khai các biện pháp chủ động phù hợp với nhu cầu CNTT đang thay đổi. Tìm hiểu thêm.
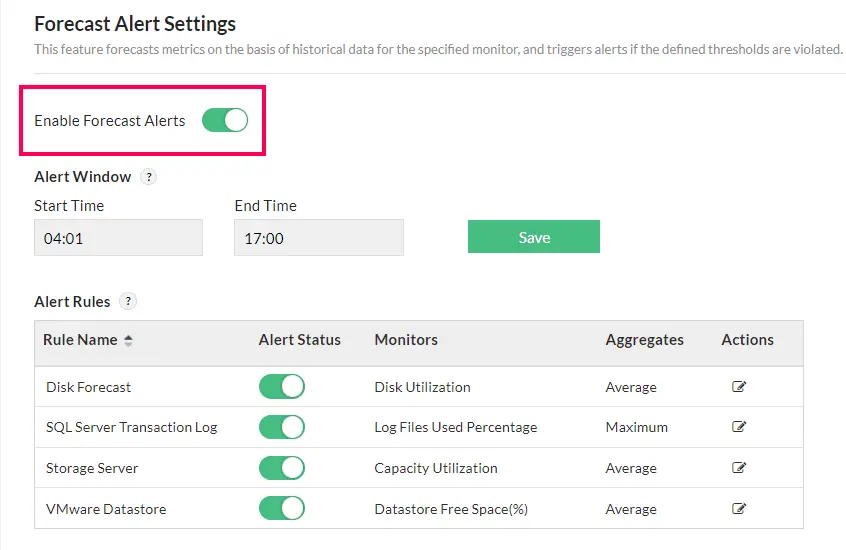
Cảnh báo dự báo (Forecast alerts)
Bạn sẽ luôn nắm rõ trạng thái tài nguyên qua tính năng dự đoán thời điểm mà các network resource sẽ đạt đến ngưỡng tới hạn. Dự báo này được tổng hợp từ quá trình quan sát liên tục mô hình sử dụng tài nguyên theo thời gian và phân tích bằng công cụ dự báo nâng cao. Dựa trên đó, hệ thống sẽ kích hoạt cảnh báo chủ động, giúp network admin giảm thiểu rủi ro và triển khai chiến lược quản lý dung lượng hiệu quả. Tìm hiểu thêm.
Zia Insights dashboards
Chuyển đổi các điểm nghẽn dự báo (forecast bottlenecks) thành insight với dashboard Zia Insights. Nhận các đề xuất dự đoán dựa trên AI về các lỗi hạ tầng để đội ngũ CNTT chủ động xử lý trước khi sự cố xảy ra. Tìm hiểu thêm.
Khai thác sức mạnh của generative AI để chuyển đổi dữ liệu raw observability thành các đề xuất khả thi. Từ các đề xuất dự đoán đến giao diện hội thoại, những khả năng này giúp đội ngũ làm việc thông minh hơn, thay vì làm việc nhiều hơn.
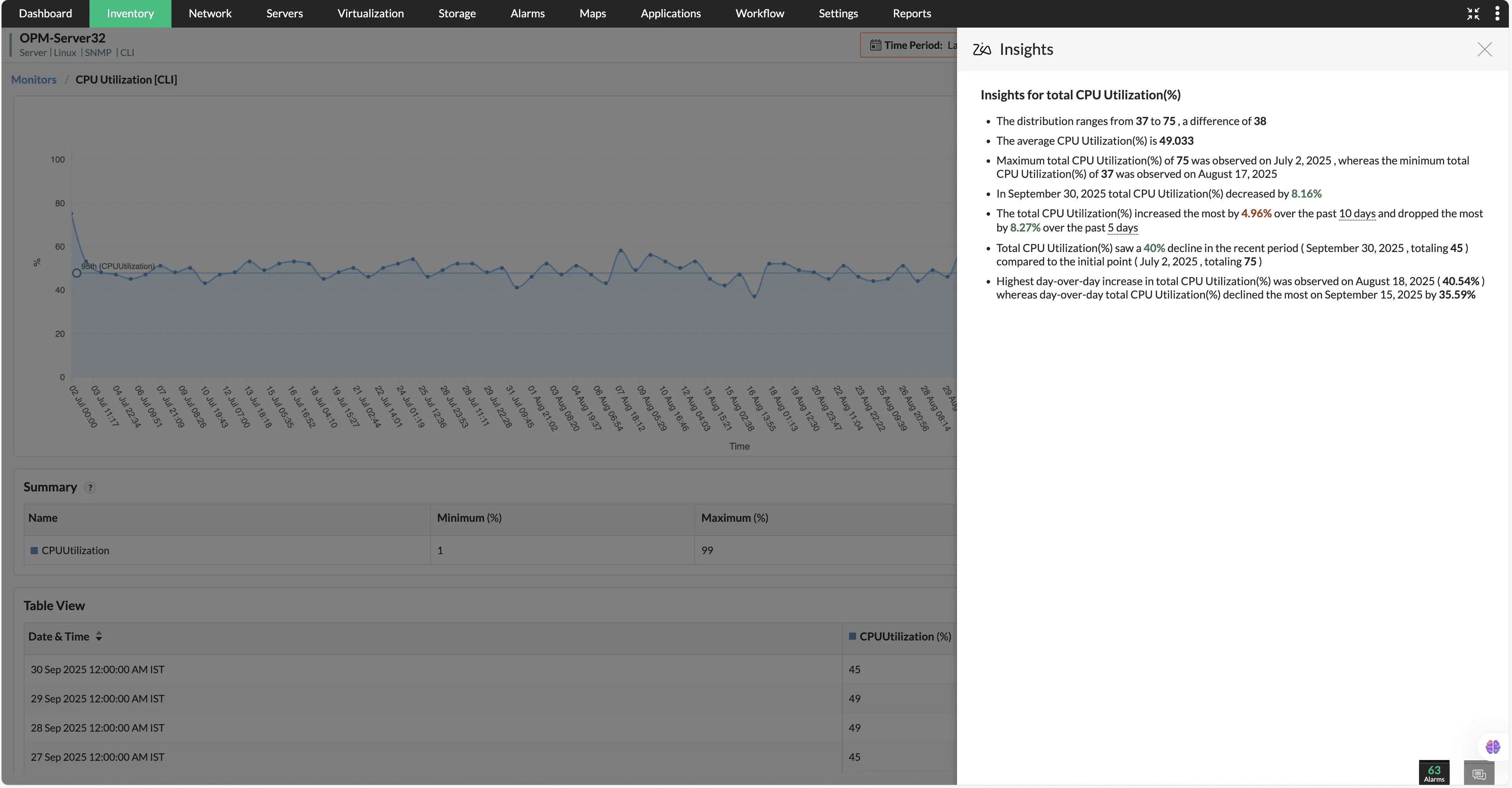
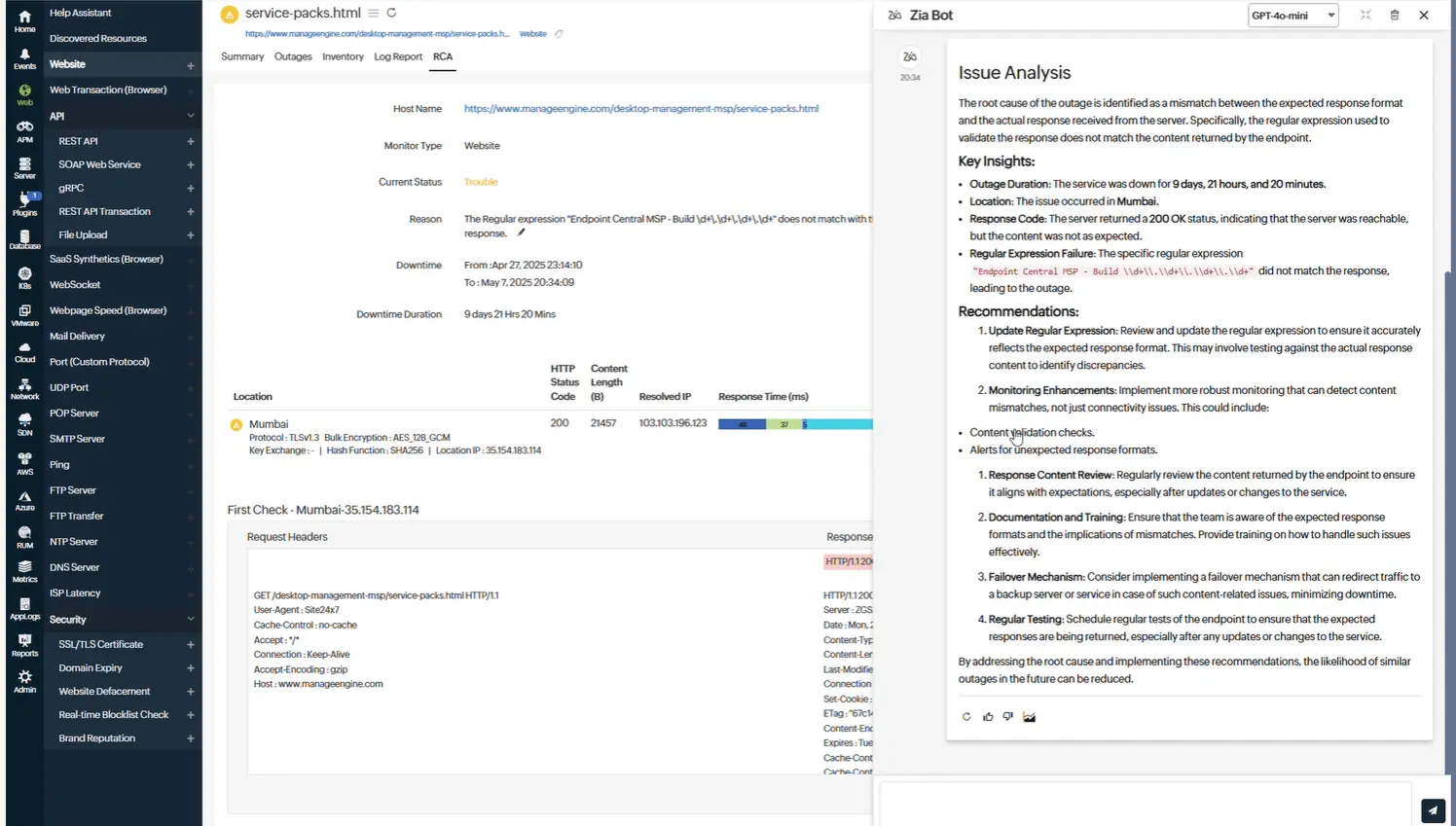
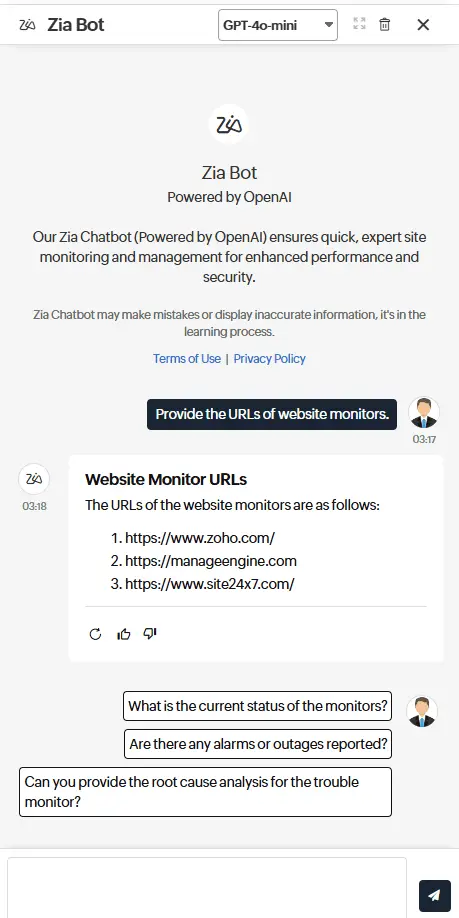
Zia Insights
Dễ dàng chuyển đổi dữ liệu thô và phức tạp thành các insight rõ ràng, có thể thực hiện. Với mô hình AI do chúng tôi tự phát triển, đội ngũ CNTT có thể phân tích hiệu suất thiết bị thông qua các bản tóm tắt ngắn gọn, dễ hiểu thay vì phải xử lý các biểu đồ và dữ liệu dày đặc.
Tự động phân tích nguyên nhân gốc rễ
Được hỗ trợ bởi các mô hình ngôn ngữ lớn (LLM) tiên tiến, nền tảng tự động phân tích tương quan dữ liệu telemetry trên metrics, logs và traces để xác định nguyên nhân gốc rễ có khả năng cao nhất. Điều này giúp tăng tốc fault isolation (cô lập lỗi), giảm downtime và loại bỏ guesswork trong quá trình xử lý sự cố.
Chatbot hội thoại
Tương tác với dữ liệu observability thông qua chatbot hội thoại. Chỉ cần sử dụng ngôn ngữ thông thường (plain language) để truy vấn logs, metrics và traces hoặc tạo các bản tóm tắt dễ hiểu về sự cố và bất thường — giúp đội ngũ nhanh chóng nắm bắt vấn đề và hành động kịp thời.
Nền tảng của chúng tôi trao quyền cho đội ngũ CNTT với khả năng observability end-to-end trên toàn bộ hạ tầng, ứng dụng và dịch vụ - cung cấp góc nhìn hợp nhất giúp loại bỏ các silo vận hành. Khi hợp nhất metrics, events và telemetry từ nhiều nguồn - nền tảng giúp tăng tốc đề xuất insight, giám sát chủ động và tối ưu vận hành. Điều này nhằm đảm bảo đội ngũ IT và DevOps có thể quản lý môi trường phức tạp một cách hiệu quả mà vẫn duy trì hiệu suất dịch vụ tối ưu.
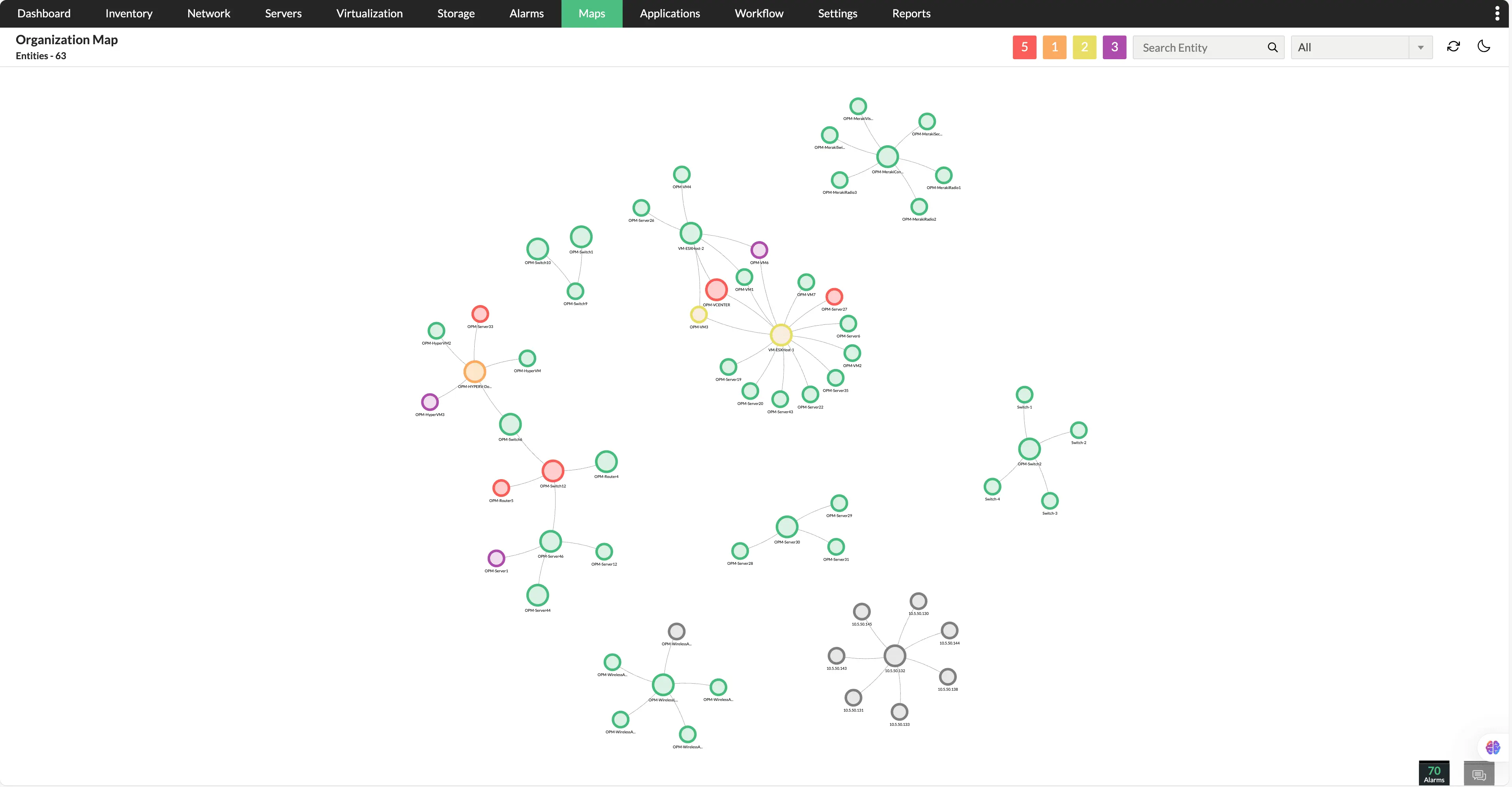

Quan sát topology full-stack
Quan sát topology thay đổi theo thời gian thực của toàn bộ hạ tầng thể hiện mối quan hệ giữa thiết bị, ứng dụng và dịch vụ. Thay vì phải điều hướng qua nhiều điểm dữ liệu rời rạc, đội ngũ CNTT có thể quan sát tất cả các dependency trong một giao diện - giúp nhanh chóng xác định khu vực gặp vấn đề, đánh giá mức độ ảnh hưởng tiềm ẩn và rút ngắn quá trình xử lý sự cố.
Hệ sinh thái CNTT hợp nhất
Tích hợp liền mạch với các nền tảng ITSM, công cụ cộng tác và cloud service để giám sát và quản lý sự cố tập trung tại một nơi.
Integration tùy chỉnh và workflow tự động
Sử dụng integration, API hoặc webhook tùy chỉnh để cá nhân hóa quy trình xử lý sự cố. Ứng dụng workflow tự động theo trigger để triển khai các biện pháp khắc phục lỗi Level 1 nhanh chóng.
5 lý do doanh nghiệp trên toàn thế giới
lựa chọn ManageEngine

- Đáng tin cậy: Hơn 20 năm hoạt động trên thị trường
- Tiết kiệm chi phí: Nhiều tính năng vượt trội với mức giá cạnh tranh
- An toàn: Tuân thủ các tiêu chuẩn và quy định bảo mật hàng đầu
- Hiện đại: Tích hợp các tính năng giám sát và bảo mật mới nhất
- Tiện lợi: Tự động hóa nâng cao và giao diện trực quan
Hơn 1 triệu admin IT trên toàn thế giới
tin dùng ManageEngine
Các thương hiệu hàng đầu thế giới tin dùng ManageEngine
Khách hàng trên toàn thế giới tin chọn ManageEngine
![]()
“Triển khai dễ dàng, hỗ trợ tốt và chi phí thấp — Team Lead, Ngành IT Service”
Reviewer từ bộ phận: Infrastructure và Operations
Quy mô: 500 triệu — 1 tỷ USD
Chúng tôi đã sử dụng OpManager từ năm 2011 và trải nghiệm tổng thể rất tuyệt vời. Công cụ đóng vai trò quan trọng trong việc mang lại giá trị cho công ty của chúng tôi cũng như cho khách hàng mà chúng tôi hỗ trợ. Đội ngũ Support xuất sắc và luôn chịu trách nhiệm đến cùng trong việc xử lý sự cố. Các phiên bản mới cập nhật liên tục thể hiện tinh thần đổi mới không ngừng của ManageEngine.
![]()
"OpManager dẫn trước đối thủ 10 bước, chỉ còn 1 bước để trở thành vô đối — Network Services Manager, Tổ chức chính phủ”
Reviewer từ bộ phận: Infrastructure và Operations
Quy mô: 5.000 — 50.000 nhân viên
Tôi đã sử dụng ManageEngine trong khoảng thời gian dài. OpManager đôi khi thiếu một hoặc hai tính năng để trở thành công cụ tốt nhất trên thị trường, nhưng về tổng thể đây vẫn là giải pháp toàn diện và dễ sử dụng nhất hiện nay.
![]()
"Triển khai dễ dàng với danh mục tính năng phong phú, đội ngũ Support còn có thể cải thiện thêm — NOC Manager, Ngành IT Service"
Reviewer từ bộ phận: Program và Portfolio Management
Quy mô: 500 triệu — 1 tỷ USD
Nhà cung cấp đã hỗ trợ rất tốt trong giai đoạn triển khai và thử nghiệm POC, bao gồm việc cung cấp các giấy phép dùng thử. Những yêu cầu về tính năng và phản hồi đều được xử lý khá nhanh chóng. Trong suốt quá trình triển khai, chúng tôi nhận được đầy đủ sự hỗ trợ từ phía nhà cung cấp. Sau khi đưa vào vận hành, chất lượng hỗ trợ vẫn ở mức tốt, dù vẫn còn vài điểm có thể cải thiện thêm.
![]()
"Công cụ giám sát tuyệt vời — CIO, Ngành Tài chính"
Reviewer từ bộ phận: Tài chính
Quy mô: 1 — 3 tỷ USD
ManageEngine cung cấp một bộ công cụ giúp cải thiện đáng kể tính khả dụng của các ứng dụng nội bộ. Từ giám sát, quản lý đến cảnh báo - chúng tôi đã có thể tối ưu hiệu suất data center của mình.
![]()
"Triển khai đơn giản, dễ sử dụng, rất trực quan — Principle Engineer, Ngành IT Service"
Reviewer từ bộ phận:
Enterprise Architecture và Technology Innovation
Quy mô:
250 — 500 triệu USD
Đội ngũ Support của ManageEngine phản hồi nhanh cho tất cả câu hỏi của chúng tôi.

“OpManager giúp tôi giám sát mọi khía cạnh của Data Center và các thiết bị như server, switch và router. Công cụ nhanh, trực quan, tập trung — và bạn không cần phải là chuyên gia để sử dụng OpManager.”
Altaleb Alshenqiti
NGHA

“Donald Stewart, Quản lý CNTT tại Crest Industries, hài lòng với ManageEngine OpManager — phần mềm giám sát mạng end-to-end. Công cụ dễ sử dụng và cung cấp khả năng quản lý lỗi cũng như hiệu suất cho các router.”
Donald Stewart
IT Manager, Crest Industries

“John Rosser, Quản lý MIS tại Yale Chase, chia sẻ về khả năng chủ động của ManageEngine OpManager và cách công cụ mang lại giá trị cho tổ chức của ông.”
John Rosser
MIS Manager