Analistas de segurança monitoram todas as atividades de rede, geralmente contando com soluções de SIEM. No entanto, nem todos os SIEMs são iguais; suas capacidades e configurações determinam o volume de alertas que os analistas enfrentam. Uma solução de SIEM com capacidades de UEBA ode ajudar a maximizar alertas legítimos e reduzir falsos positivos, especialmente se for oferecida com a funcionalidade de análise de grupo de pares Vamos revisar rapidamente o que é agrupamento de pares antes de nos aprofundarmos em como a análise de grupos de pares funciona.
Análise de grupo de pares: Definição e tipos
A análise de grupo de pares é uma técnica alimentada por algoritmos de machine learning, onde usuários e hosts que compartilham características similares são categorizados como um grupo. Isso nos ajuda a entender o contexto por trás do comportamento de um usuário e o grau de risco representado por ele. Ao comparar o comportamento de um usuário com o de seus pares e entender o contexto, você obtém insights melhores do que quando o analisa como um evento isolado. Então, essencialmente, você consegue aumentar a precisão da pontuação de risco dos usuários por causa da visão holística fornecida pelo agrupamento de pares.
Pode haver dois tipos de agrupamento de pares: estático e dinâmico. Enquanto o agrupamento estático de pares funciona com base em atributos comuns (como localização, designação e gerente de relatórios) compartilhados pelos usuários, o agrupamento dinâmico de pares funciona com base na similaridade comportamental entre os usuários. Algoritmos de machine learning são utilizados para agrupamento dinâmico de pares, conforme o padrão comportamental dos usuários é estudado ao longo do tempo para determinar a qual grupo de pares um usuário deve pertencer. Isto levanta várias questões: Como exatamente o agrupamento de pares é realizado? Como o algoritmo determina de qual grupo um usuário deve fazer parte? Como isso afeta a pontuação de risco?
Como o agrupamento de pares é realizado?
A análise de grupo de pares pode ser realizada utilizando soluções de SIEM de diferentes maneiras, dependendo do algoritmo que ela utiliza. Diferentes fornecedores de SIEM têm algoritmos distintos, mas uma maneira eficaz de agrupar usuários em grupos de pares é usar um algoritmo de clusterização como o ConStream. Algoritmos de clusterização funcionam com base no princípio de agrupar usuários em grupos com base em um índice de similaridade. O algoritmo de machine learning aprende o padrão comportamental dos usuários ao longo do tempo e identifica quais usuários têm um padrão de comportamento similar para poder atribuir uma pontuação de similaridade (SS) a eles. O fato de um usuário pertencer ou não a um cluster será decidido com base em se a sua SS é maior ou menor que o threshold pré-definido. Para entender melhor, vamos começar do zero.
Para realizar a análise de grupo de pares, seu mecanismo de detecção de anomalias primeiramente analisará as análises de segurança geradas a partir da ingestão dos registros dos dispositivos de rede. Cada conjunto de análises gerado pela sua solução de SIEM é único e será associado a um modelo diferente. Por exemplo, análises baseadas em horários de login do usuário constituirão um modelo, enquanto as análises baseadas em consultas SQL serão outro modelo. Um modelo é como um depósito que armazena os clusters associados a um tipo específico de atividade. O número de clusters em um modelo vai variar dependendo do algoritmo utilizado.
Considere um modelo, M1, que está associado às atividades de login dos usuários. Suponha que M1 possa hospedar 1000 clusters, chamados C1, C2,..., C1000. Mesmo que os clusters como C1 e C2 se enquadrem na categoria ampla de "logins de usuário", eles ainda são diferentes em termos dos eventos que consideram para análise. Por exemplo, C1 agrupará eventos de usuários que exibem determinados tipos de comportamento de login e C2 agrupará eventos de usuários que exibem outro conjunto de comportamento de login, que é marcadamente diferente do comportamento geral dos usuários em C1. Você pode classificar ainda mais os eventos do usuário em clusters com base em outros comportamentos de login (C3, C4 e assim por diante). Essencialmente, M1 poderia ter um máximo de 1000 clusters e cada cluster pode ter um número "n" de eventos adicionados a ele.
Como o algoritmo determina de qual grupo um usuário deve fazer parte?
Com tantos clusters disponíveis, determinar de qual cluster um evento deve fazer parte depende da pontuação de similaridade. Sempre que um evento de login é registrado, a SS será calculada entre o evento e clusters já disponíveis, e ela será então comparada ao valor do threshold. O valor do threshold é o valor definitivo pvara determinar em qual cluster um evento do usuário deve fazer parte. Por exemplo, vamos supor que para um evento, E1, ser adicionado ao cluster C1, sua SS deve ser maior ou igual ao valor do threshold, digamos 0,6. Se não for, então E1 fará parte de um noo cluster chamado C2. A figura abaixo dá uma ideia de como os algoritmos de ML calculam a SS e adicionam eventos aos clusters.
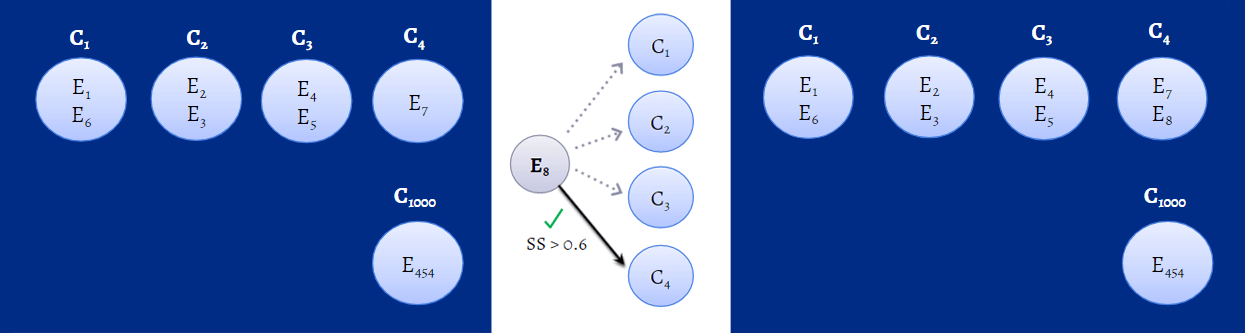
Figura 1: Algoritmo de machine learning que calculam a SS em segundo plano para identificar a qual cluster um evento deve pertencer.
Como o agrupamento de pares afeta a pontuação de risco?
Uma vez que um usuário se torna parte de um grupo ou cluster, seu comportamento será comparado com o de seus pares, para identificar se sua atividade foi realmente anômala ou se é a norma para os pares desse grupo. Considere uma organização chamada Anthem, que tem controle de presença baseado em biometria no local para seus funcionários. Você precisa colocar a sua impressão digital toda vez que entrar ou sair da organização, e é assim que suas horas de trabalho são registradas. No entanto, para acomodar os usuários remotos, eles têm um portal separado onde você pode usar suas credenciais para marcar sua presença. Um associado de marketing, Mark, que normalmente trabalha no escritório todos os dias, começou a efetuar o login remotamente em dias alternados e acessar o banco de dados de marketing. No curso geral dos eventos, sua ação seria considerada arriscada e sua pontuação de risco aumentaria. No entanto, se essa ação for comparada com a de seus pares, que também seguem o modelo de trabalho híbrido, o nível de confiança calculado será reajustado e sua pontuação de risco diminuirá imediatamente, normalizando-se ao longo do tempo. O nível de confiança é um valor calculado pelo seu algoritmo de machine learning para lhe dar uma ideia do nível de risco de um evento.
Com o agrupamento de pares, a precisão da sua avaliação e pontuação de risco aumenta, e muitos alertas falsos podem ser reduzidos. No entanto, deve-se observar que, embora o agrupamento de pares tenha um impacto positivo na precisão da pontuação de risco, ele não é o único fator decisivo quando se trata da pontuação de risco total de um usuário. Isso dependerá de vários fatores, como o peso atribuído ao tipo de ameaça, fator de decaimento do tempo e sazonalidade. Para obter mais informações, leia: Como a pontuação de risco funciona na detecção de anomalias?
Indo mais fundo
gora, você já deve ter um bom entendimento de como o agrupamento de pares funciona. Porém, provavelmente, você ainda tem algumas perguntas em mente, como:
- Um usuário pode estar em mais de um grupo?
- O que acontece quando há um evento que não pode ser categorizado em nenhum dos clusters existentes, e o modelo já está hospedando 1000 clusters?
Para responder à primeira pergunta, vamos considerar dois usuários: Mike e Harvey. Mike efetua o login remotamente às 8:00 (E1), enquanto Harvey efetua o login no escritório às 11:00 (E2). Agora, se você considerar esses eventos, observará que tanto Mike quanto Harvey se encaixam em dois clusters cada, um baseado na sua forma de login (Mike no C1 e Harvey no C2) e o outro baseado no seu horário de login (Mike fará parte do C3 e Harvey, do C4), conforme mostrado na figura abaixo. Portanto, sim, um usuário pode pertencer a mais de um cluster.
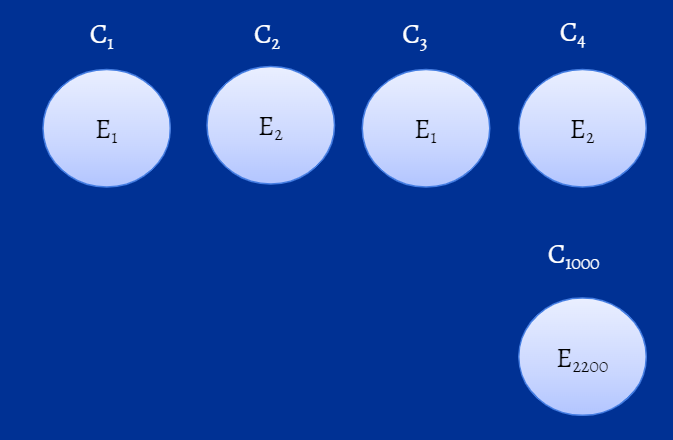
Figura 2: Representação dos clusters do modelo, M1.
Agora, passando para a segunda pergunta, caso uma situação como essa surgisse, ocorreria a morte do cluster. A morte do cluster refere-se à remoção de um cluster desatualizado do modelo para acomodar a inclusão de um novo. Um cluster desatualizado é aquele no qual nenhum novo evento foi adicionado por um longo período. Uma vez que não há sentido em ter eventos desatualizados, ocorrerá a morte do cluster. Um novo cluster é criado, no qual o novo evento será adicionado, e esse ciclo continua.
O Log360 da ManageEngine é uma solução de SIEM unificada com capacidades integradas de UEBA. O produto permite que você configure funcionalidades de agrupamento de pares estáticos e dinâmicos. Ele também fornece uma pontuação de risco contextual, pontuação de risco personalizada e fatores de sazonalidade e mapeamento de identidade de usuários para melhorar a precisão da pontuação de risco. Como melhorar a pontuação de riscos e a detecção de ameaças com a UEBA, leia este e-book. Para entender como o agrupamento de pares funciona no Log360, inscreva-se para uma demonstração personalizada.