
Was ist ein Netzwerk-Desaster-Wiederherstellungsplan?
A Netzwerk-Desaster-Wiederherstellungsplan (NDRP) ist ein strukturiertes, wiederholbares Rahmenwerk, das beschreibt, wie eine Organisation ihre Netzwerkgeräte, Verbindungsebenen und Konfigurationszustände nach einer unerwarteten Störung wiederherstellt. Im Gegensatz zu traditionellen Desaster-Recovery-Ansätzen, die sich hauptsächlich auf Server oder Anwendungsdaten konzentrieren, ist ein NDRP speziell darauf ausgelegt, Router, Switches, Firewalls, Wireless-Controller, VPN-Gateways und die gesamte Konfigurationslogik, die ein Netzwerk funktionsfähig hält, zu schützen.
Es beschreibt, wie Netzwerkteams Ausfälle erkennen, welche Maßnahmen sie ergreifen, um die Funktionalität wiederherzustellen, und welche Prozesse sicherstellen, dass Konfigurationen innerhalb akzeptabler Zeitlimits in einen bekannten guten Zustand zurückkehren.
Ein moderner NDRP stellt sicher, dass unabhängig vom Vorfall, sei es durch menschliches Versagen, Ransomware-Infektion, Hardware-Fehler oder großflächige Umweltschäden, Ihr Netzwerk schnell, konsistent und sicher wiederhergestellt werden kann.
Warum Netzwerk-Desaster-Wiederherstellung heute wichtig ist
Netzwerke sind zum Rückgrat moderner digitaler Abläufe geworden. Mit hybriden Arbeitsmodellen, verteilten Rechenzentren, SaaS-Adoption, SD-WAN, IoT und Cloud-first-Architekturen ist das Netzwerk komplexer denn je. Diese Komplexität erhöht direkt das Risiko von Ausfällen.
Die meisten Netzwerk-Ausfälle heute werden nicht durch massive Katastrophen verursacht; sie resultieren aus Fehlkonfigurationen, überstürzten Updates, unautorisierten Änderungen, veralteter Firmware und Ransomware-Angriffen auf die Netzwerkinfrastruktur. Diese Fehler können sofort die Konnektivität für Tausende von Benutzern und Anwendungen unterbrechen.
Die Kosten von Ausfallzeiten gehen über Produktivitätsverluste hinaus. Sie beeinflussen die Kundenzufriedenheit, Serviceverfügbarkeit, SLAs, Compliance und sogar den Markenruf. Führungskräfte erwarten heute Wiederherstellungsprozesse, die schnell, automatisiert und überprüfbar sind. Die Realität ist einfach: Server können nur dann wiederhergestellt werden, wenn das Netzwerk funktioniert. Ohne einen Netzwerk-Desaster-Wiederherstellungsplan fällt sogar die stärkste Desaster-Wiederherstellungsstrategie zusammen.
Kernkomponenten eines modernen Netzwerk-Desaster-Wiederherstellungsplans
Ein starker Netzwerk-Desaster-Wiederherstellungsplan geht über das einfache Backup von Konfigurationen hinaus. Er bringt Struktur, Klarheit und Schnelligkeit in jede Phase der Wiederherstellung, sodass Teams die Konnektivität mit minimalen Unterbrechungen wiederherstellen können. Dies sind die Kernkomponenten, die einen modernen, zuverlässigen NDRP formen:
1. Netzwerkgerät- & Konfigurationsinventar
Ein robustes NDRP beginnt mit einem zentralisierten, genauen Inventar jedes Netzwerkgeräts in Ihrer Umgebung. Dazu gehören Core-Switches, Verteilrouter, Firewalls, Wireless-Controller, Load Balancer und an Zweigstellen verteilte Edge-Geräte.
Über eine reine Auflistung der Geräte hinaus muss das Inventar jede Version von laufenden und Startkonfigurationen, Firmware-Details, Schnittstellen-Zuordnungen, Seriennummern und Versionshistorie erfassen. Wenn ein Ausfall eintritt, verlassen sich Teams auf historische Konfigurationsversionen, um zu erkennen, was sich wann geändert hat und welche Version sie wiederherstellen müssen. Ein umfassendes Inventar eliminiert Vermutungen und beschleunigt die Wiederherstellung.
2. RTO, RPO & Wiederherstellungspriorisierung
Jede Organisation arbeitet mit unterschiedlichen Erwartungen an akzeptable Ausfallzeiten. Deshalb ist die Definition von Recovery Time Objective (RTO) und Recovery Point Objective (RPO) entscheidend.
RTO legt fest, wie schnell ein Gerät wiederhergestellt sein muss, bevor Geschäftsprozesse betroffen sind. RPO definiert, wie aktuell das Backup der Konfiguration sein muss, um Datenverlust oder Konfigurationsabweichungen zu vermeiden.
Basierend auf diesen Werten sollten Geräte in Kategorien eingeteilt werden; Kernfirewalls und WAN-Router fallen typischerweise in die kritische Kategorie, während Access-Switches sekundär sein können. Diese Priorisierung stellt sicher, dass sich die Wiederherstellungsbemühungen immer zuerst auf die Systeme konzentrieren, die die Rückgrat-Konnektivität aufrechterhalten.
3. Backup-Strategie für Netzwerkgeräte
Backups bilden die Grundlage für die Desaster-Wiederherstellung. Ohne vollständige, aktuelle und verifizierte Konfigurationsbackups ist die Wiederherstellung eines Netzwerks nahezu unmöglich.
Ein NDRP muss automatisierte Konfigurationsbackups enthalten, sowohl zeitbasierte als auch änderungsbasierte, um sicherzustellen, dass keine Updates unbemerkt bleiben. Firmware-Versionen sollten ebenfalls häufig erfasst werden, da Firmware-Inkompatibilitäten verhindern können, dass Geräte booten oder Konfigurationen akzeptieren.
Backups sollten sicher gespeichert werden (vorzugsweise verschlüsselt und an externen Standorten repliziert) mit strengen Aufbewahrungsrichtlinien, die eine Rollback-Unterstützung über Monate oder sogar Jahre gewährleisten. Ebenso wichtig ist die Überprüfung der Backup-Integrität, die bestätigt, ob die gespeicherte Konfiguration vollständig, fehlerfrei und für den Einsatz im Notfall bereit ist.
4. Wiederherstellungs- und Rücksetzverfahren
Ein Desaster-Wiederherstellungsplan muss klare, schrittweise Wiederherstellungsabläufe enthalten. Diese Abläufe beschreiben, wie Teams einzelne Geräte, ganze Zweigstellen oder Standorte nach Störungen wiederherstellen.
Gerätebezogene Wiederherstellungen ermöglichen es Ingenieuren, die exakt benötigte Konfigurationsversion zur Funktionserholung einzuspielen. Standortbezogene Wiederherstellungen unterstützen die Massenverteilung, wenn ein Ausfall auf Zweigstellenebene oder ein Umweltereignis mehrere Geräte betrifft.
Fehlkonfigurationen sind eine der häufigsten Ursachen für Ausfälle und müssen durch Konfigurations-Rollbacks behandelt werden, die Teams helfen, sofort zur stabilsten Baseline zurückzukehren. Eine gut gepflegte Baseline-Version wird zum Ankerpunkt aller Wiederherstellungsaktionen und sorgt für vorhersehbares Verhalten nach der Wiederherstellung.
5. Netzwerkautomatisierung für schnellere Wiederherstellung
Automatisierung verbessert die Geschwindigkeit und Konsistenz der Desaster-Wiederherstellung erheblich. Automatisierte Backup-Zeitplanung, automatisierte Konfigurationsausspielung und Echtzeit-Überwachung von Änderungen reduzieren die Abhängigkeit vom Menschen und eliminieren manuelle Fehler.
Im Notfall können Automatisierungstools standardisierte Templates gleichzeitig an mehrere Geräte verteilen, Abweichungen erkennen, Compliance durchsetzen und unautorisierte Änderungen zurücksetzen.
Automatisierung ist nicht nur eine Bequemlichkeit; sie ist eine kritische Voraussetzung für moderne Desaster-Wiederherstellungspläne, bei denen die Reaktionszeit direkt die Geschäftskontinuität beeinflusst.
Wie man einen effektiven Netzwerk-Desaster-Wiederherstellungsplan erstellt (Schritt für Schritt)
Ein solider NDRP gibt Ihrem Team die Klarheit, schnell zu reagieren, Stabilität wiederherzustellen und kritische Konnektivität mit Zuversicht online zu bringen. Die unten stehenden Schritte skizzieren einen praktischen, modernen Workflow, der Ihnen hilft, sich auf unerwartete Ausfälle vorzubereiten und diese ohne Verzögerung zu beheben:
1. Identifizieren Sie geschäftskritische Netzwerkkomponenten
Beginnen Sie mit der Kartierung der Geräte, die direkt die Konnektivität, Sicherheit und Servicebereitstellung beeinflussen. Dazu gehören Edge-Router, Core-Switches, VPN-Konzentratoren, Domain-Firewalls und SD-WAN-Controller. Jedes Gerät, dessen Ausfall den Geschäftsbetrieb beeinträchtigt, sollte in der kritischen Wiederherstellungsstufe eingestuft werden.
2. Dokumentieren Sie Geräte-Konfigurationen gründlich
Erstellen Sie ein detailliertes, zentrales Repository, das jede Konfigurationsaufnahme speichert, z. B. laufende Konfigurationen, Startkonfigurationen, Firmware-Details und Schnittstelleninformationen. Diese Dokumentation muss durch automatisierte Backups ständig aktualisiert werden, damit Teams jederzeit eine zuverlässige Baseline für die Wiederherstellung haben.
3. Definieren Sie praktikable RTO- und RPO-Werte
Gestalten Sie Ihren NDRP um realistische RTO- und RPO-Ziele. Eine Kernfirewall benötigt möglicherweise nahezu keine Ausfallzeit, während sekundäre Geräte etwas Flexibilität erlauben. Diese Werte steuern Backup-Zeitpläne, Dringlichkeit der Wiederherstellung und die Gesamtstrategie.
4. Automatisieren Sie Backup-Häufigkeit und Änderungsaufzeichnung
Um blinde Flecken zu vermeiden, planen Sie automatisierte Backups entsprechend Ihren RPO-Anforderungen. Fügen Sie änderungsbasierte Trigger hinzu, die Konfigurationserstellungen sofort erfassen. Automatisierte Backups verhindern, dass das Netzwerk mehr als wenige Minuten von der zuletzt bekannten guten Konfiguration abweicht.
5. Pflegen Sie versionierte Konfigurations-Repositories
Bewahren Sie ein vollständiges Archiv jeder Konfigurationsversion auf, angereichert mit Metadaten wie Zeitstempeln, Autoren, Änderungsnotizen, Compliance-Dokumenten und Gerätekontext. Diese Versionskontrolle hilft Teams, Probleme auf die genaue Konfiguration zurückzuführen, die eine Störung verursachte und ermöglicht schnelle, präzise Rollbacks.
Wichtige Netzwerk-Desaster-Wiederherstellungsmetriken
Die Verfolgung der richtigen Metriken hilft Ihnen zu verstehen, wie gut Ihre Desaster-Wiederherstellungsstrategie unter realen Bedingungen funktioniert – nicht nur auf dem Papier. Die untenstehenden KPIs zeigen, ob Ihr Netzwerk schnell, zuverlässig und mit minimalem Risiko wieder einsatzfähig ist.
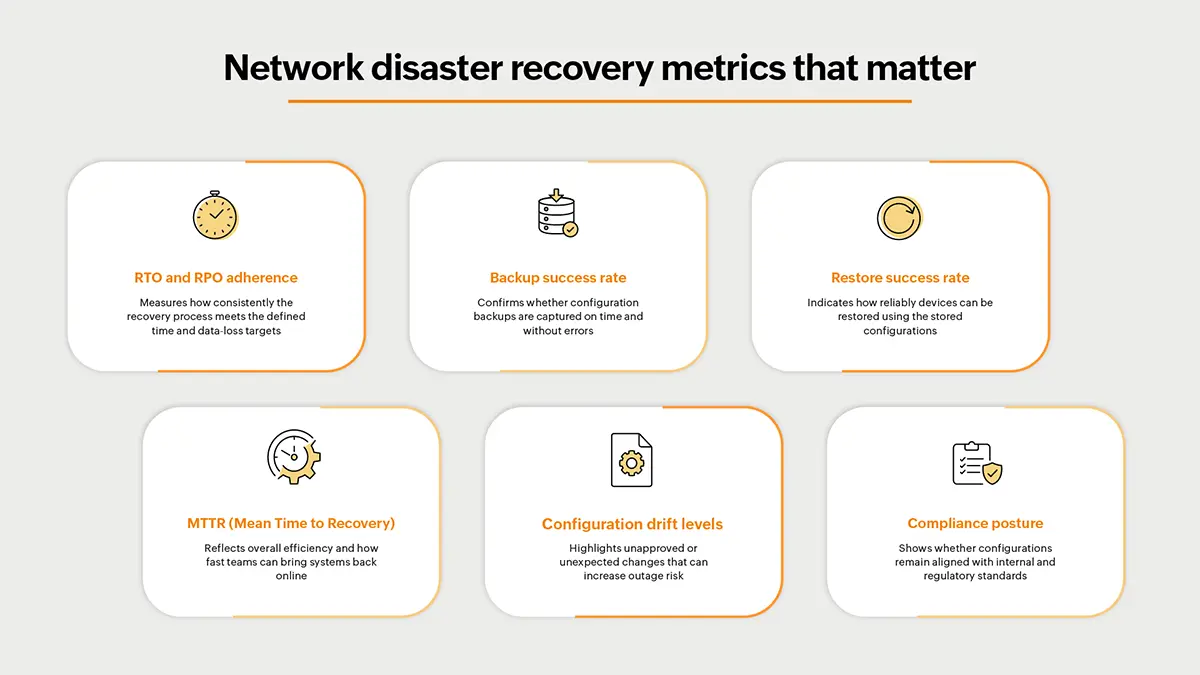
Diese Metriken ermöglichen es Teams, ihre Desaster-Wiederherstellungsbereitschaft kontinuierlich zu verbessern und die Resilienz im gesamten Netzwerk zu stärken.
Wie ManageEngine Network Configuration Manager bei der Netzwerk-Desaster-Wiederherstellung hilft
Wenn ein Netzausfall eintritt, bestimmen die Geschwindigkeit und Genauigkeit Ihres Wiederherstellungsprozesses, wie schnell die Geschäftsprozesse wieder anlaufen. ManageEngine Network Configuration Manager vereint alle wesentlichen Funktionen, darunter Backup-Automatisierung, Versionsinformationen, Compliance-Kontrolle und Massenwiederherstellung, um Teams bei der sicheren Wiederherstellung von Geräten und Diensten zu unterstützen.
-
Automatisierte Multi-Vendor-Konfigurations-Backups: ManageEngine Network Configuration Manager erfasst geplante und Echtzeit-Backups für Router, Switches, Firewalls und Controller. Jede Konfigurationsänderung wird sicher gespeichert, sodass Teams während der Wiederherstellung sofort auf neueste und ältere Versionen zugreifen können.
-
Tiefe Versionskontrolle mit Änderungsvergleich: Die Plattform führt vollständige Konfigurationshistorien und bietet einen Zeile-für-Zeile-Konfigurationsvergleich . So können Ingenieure schnell die genaue Änderung identifizieren, die einen Ausfall verursachte, und die stabilste Version ohne Verzögerung wiederherstellen.
-
Echtzeit-Erkennung von Konfigurationsabweichungen: ManageEngine Network Configuration Manager warnt Teams sofort, wenn eine unautorisierte oder versehentliche Änderung erfolgt. Diese Frühwarnung verhindert, dass fehlerhafte Konfigurationen sich im Netzwerk verbreiten.
-
Wiederherstellung mit einem Klick und schnelles Rollback: Bei Fehlkonfigurationen oder Ausfällen können Ingenieure sofort eine bekannte gute Konfiguration ausspielen . Diese Funktion reduziert die mittlere Wiederherstellungszeit erheblich und stellt kritische Dienste schnell wieder her.
-
Sichere Backup-Verschlüsselung und rollenbasierte Zugriffskontrolle: Alle Konfigurationsbackups sind verschlüsselt und der Zugriff wird streng durch rollenbasierte Berechtigungen gesteuert. Nur autorisiertes Personal darf sensible Netzwerk-Konfigurationsdaten einsehen, herunterladen oder ändern.
-
Compliance-Erkennung mit automatischer Behebung: ManageEngine Network Configuration Manager enthält integrierte und vollständig anpassbare Compliance-Richtlinien . Bei Verstößen können automatisierte Vorlagen Geräte sofort in konforme Zustände zurücksetzen.
-
Programmierbare Configlets und Massenaktionen nach einem Desaster:Configlets ermöglichen es Teams, komplexe Wiederherstellungsschritte auf mehreren Geräten zu automatisieren. Nach einem Desaster unterstützt die Massenbereitstellung die Wiederherstellung ganzer Zweigstellen oder großer Gerätegruppen mit minimalem manuellem Aufwand.
-
Compliance- und Backup-Berichte nach der Wiederherstellung: Die Plattform erzeugt prüfungsbereite Berichte , die bestätigen, dass jedes Gerät ordnungsgemäß wiederhergestellt, gesichert und nach der Wiederherstellung regelkonform ist.
Ein starker Netzwerk-Desaster-Wiederherstellungsplan ist keine Option mehr. Er ist unerlässlich für die Aufrechterhaltung der Betriebszeit, die Einhaltung von Vorschriften und den Schutz der Geschäftskontinuität in einer Umgebung, in der Ausfälle, Fehlkonfigurationen und Sicherheitsrisiken weiter zunehmen. Mit klaren Prozessen, automatisierten Backups und schnellen Wiederherstellungsabläufen können Organisationen Ausfallzeiten minimieren, Konfigurationsverluste verhindern und auch bei größeren Störungen schnell wiederherstellen.
Machen Sie den nächsten Schritt: Stärken Sie Ihre Desaster-Wiederherstellungsstrategie, indem Sie die 30-tägige kostenlose Testversion von ManageEngine Network Configuration Manager herunterladen oder eine kostenlose, personalisierte Demo planen, um Ihr Netzwerk auf alles vorzubereiten.
FAQs zum Netzwerk-Desaster-Wiederherstellungsplan
1. Was ist der Unterschied zwischen DR und BCP?
Disaster Recovery (DR) konzentriert sich auf die Wiederherstellung von IT-Systemen nach Störungen. Business Continuity Planning (BCP) beschreibt, wie die gesamte Organisation während und nach einer Katastrophe den Betrieb aufrechterhält.
2. Wie oft sollten Netzwerk-Konfigurationen gesichert werden?
Backups sollten planmäßig (täglich/wöchentlich) sowie automatisch bei jeder Änderung erfolgen. Kritische Geräte benötigen häufig änderungsbasierte Backups.
3. Was verursacht die meisten Netzwerkausfälle?
Fehlkonfigurationen, unautorisierte Änderungen, veraltete Firmware, Hardwareausfälle und Sicherheitsangriffe gehören zu den häufigsten Ursachen.
4. Wie testet man einen Desaster-Wiederherstellungsplan?
Tests umfassen simulierte Wiederherstellungen, Integritätsprüfungen der Konfiguration, Failover-Übungen, Compliance-Validierung und die Dokumentation der Einhaltung von RTO/RPO-Zielen.

Von Akash,
Produktmarketing, ManageEngine