- Prévention des fuites de données
- Évaluation des risques liés aux données
- Analyse des dossiers
- Audit des dossiers
Balisage des données
Qu'est-ce que le balisage des données ?
Le balisage des données est le processus d'affectation d'une étiquette à un élément de données, tel qu'une image, un site Web ou une vidéo. Les balises associées sont souvent des métadonnées qui indiquent le nom de l'auteur, la date de création, le service, le format de fichier ou tout autre détail déterminant. Ces balises distinguent un ensemble de données des autres données d'un environnement, ce qui facilite leur recherche.
Pourquoi le balisage des données est-il important ?
Le balisage des données fournit une identité à vos données en les associant à des métadonnées. Dans une organisation, un identifiant d'employé sert à fournir une identité unique à ses employés. De même, lors d'un match de football, un numéro de siège indique l'emplacement où vous serez assis(e) dans un stade.
L'un des points communs de ces scénarios est qu'un objet est balisé avec une étiquette. Cette étiquette attribue une identité unique à l'objet et fournit :
- Identification sans effort
Dans le cas d'un match de football, le numéro de siège indique un endroit précis dans le stade, ce qui élimine la tâche de chercher votre place.
- Catégorisation facile
Les noms des services classent les employés en groupes reconnaissables.
- Sécurité des données
Un ID d'employé fournit des informations sur l'employé, qui peuvent servir à fournir et interdire l'accès aux ressources de l'organisation, garantissant ainsi la sécurité des données.
Modèles de balisage des données
« Les données sont le nouveau pétrole » est une phrase que nous avons souvent entendue au cours de la dernière décennie, et elle reste vraie lorsque nous voyons des organisations dépenser des sommes considérables pour se procurer des données. Avec le volume de données que les entreprises stockent, elles ont besoin d'une stratégie pour les étiqueter et les organiser efficacement. Voici quelques modèles de balisage de données utilisés par les organisations :
- Modèle hiérarchique
Organisez les balises dans un modèle hiérarchique, avec des catégories plus larges en haut et des balises spécifiques en bas. Par exemple, dans une application comme Spotify, la musique, les podcasts et les livres audio seront en haut tandis que les sous-catégories de chacun d'entre eux, telles que les genres, l'auto-assistance et la fiction, seront au niveau inférieur.
- Modèle plat
Dans un modèle plat, chaque balise a la même importance et il n'y a pas de relation inhérente entre les balises.
- Modèle segmenté
Ce modèle implique le balisage des données selon des segments. Par exemple, les SUV, les berlines et les voitures à hayon peuvent être dans des segments différents d’un hall d’exposition automobile.
- Modèle à jargon
Un jargon reconnaissable par les employés d'une organisation ou d'un service peut servir au balisage.
Différents types de balisages des données
Le balisage des données peut être globalement classé en différents types en fonction du format des données balisées. Il peut s'agir d'un texte, d'une image ou d'une vidéo. De plus, chacun de ces formats peut être classé selon sa fonction. Voici quelques sous-classifications :
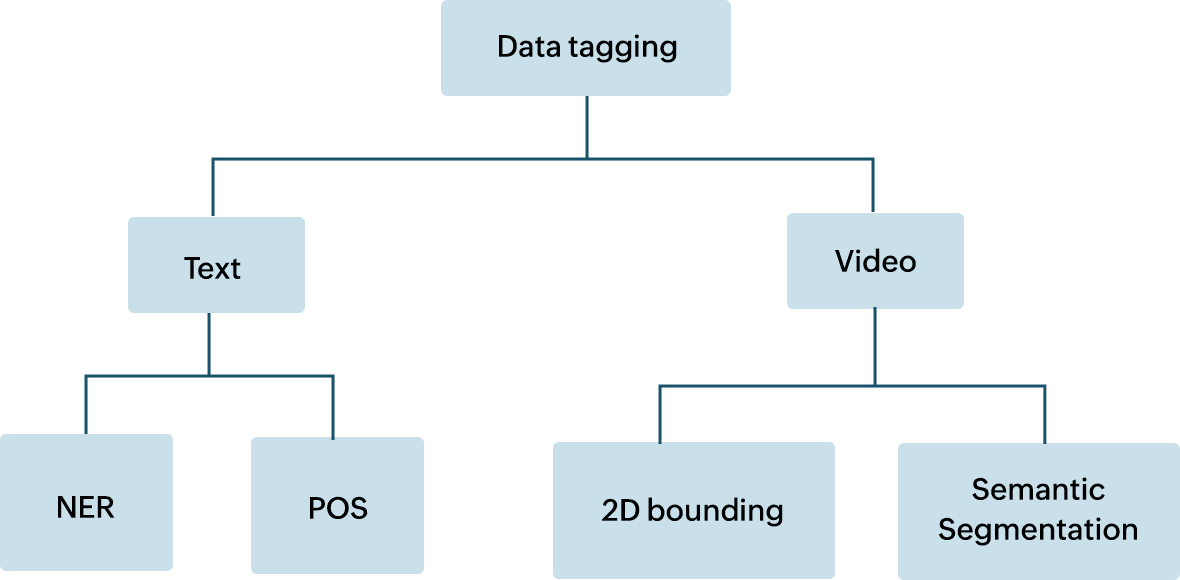
- Reconnaissance d'entités nommées (NER, named entity recognition)
La NER permet d'identifier des entités, telles que des noms, des lieux et des objets, dans un corps de texte.
- Balisage d'une partie du discours (POS, part of speech)
Le balisage POS consiste à associer des mots d'une phrase à une partie grammaticale du discours.
- Segmentation sémantique
Processus de balisage de chaque pixel faisant partie d'une image.
- Boîte englobante 2D
Elle trace une frontière autour de l'objet souhaité afin de le rendre reconnaissable.
Bonnes pratiques de balisage des données
L'objectif principal du balisage des données est de faciliter la vie d'un utilisateur final en réduisant le temps nécessaire à la tâche fastidieuse de recherche des données. Il est donc impératif que votre stratégie de balisage des données soit conviviale. Voici quelques bonnes pratiques qui pourraient faciliter la fluidité de votre expérience :
-
Avoir une nomenclature bien définie
Avoir des conventions de nommage à l'échelle de l'organisation ou du service peut aider les employés à parcourir et à récupérer des fichiers. Une nomenclature bien définie doit être reconnaissable par l'utilisateur final. Veillez donc à utiliser des mots-clés tels que service, projet, responsable, équipe et d'autres identifiants pertinents. -
Construire un modèle
Un modèle de balisage des données structure vos données et contribue à leur classification. Il existe quelques types à choisir parmi ceux présentés précédemment sur cette page. -
Réalisation d'évaluations de la facilité d'utilisation
La réalisation périodique d'évaluations de la facilité d'utilisation peut améliorer l'efficacité de votre balisage des données. Les rapports sur la facilité d’utilisation doivent prendre en compte des facteurs tels que la facilité d'accessibilité et le temps passé à récupérer les fichiers. -
Automatisation du processus de balisage des données
Le balisage manuel des données prend trop d'heures de travail peut subir des erreurs humaines. L'automatisation du processus de balisage des données par apprentissage automatique pourrait donc s'avérer inestimable.
Classification et balisage des données
Le balisage et la classification des données sont souvent utilisés de manière interchangeable, mais ce sont les deux faces d'une même médaille, chacune possédant sa propre signification.
Le balisage des données est l'étiquetage des données selon les métadonnées, telles que le nom du projet, le propriétaire du fichier ou le type de données, qui vise à améliorer l'accessibilité et l'organisation. D'autre part, la classification des données se fait en fonction du niveau de sensibilité du contenu d'un fichier, vise à sécuriser les données sensibles et peut servir à signaler les données sensibles par des outils de prévention des pertes de données. Une stratégie bien équilibrée de balisage et de classification des données peut garantir une navigation fluide et une sécurité du réseau.
Découvrez les détails de la classification des données dans notre Webinaire sur demande sur la classification des données : La pierre angulaire de la DLP.
Découvrez et classez vos données avec DataSecurity Plus
DataSecurity Plus offre un outil de découverte de données qui automatise le processus de classification des fichiers par un système d'étiquetage hiérarchique. L'outil de découverte et de classification des données détecte, classe et sécurise les données sensibles telles que les informations d’identification personnelle, les informations de carte de paiement, les informations de santé protégées, et autres, garantissant ainsi la conformité réglementaire.
DataSecurity Plus est équipé de fonctions telles que :
- Rapports en temps réel sur le type, le volume et l'emplacement des données sensibles.
- Règles de découverte de données personnalisables pour définir des données sensibles spécifiques à l'organisation.
- Alertes de suivi des fichiers qui contiennent des correspondances avec les lois sur la protection des données telles que le RGPD, la norme PCI DSS, et autres.
- Analyses incrémentielles de découverte de données pour créer et maintenir un inventaire de vos données les plus sensibles.
Essayez la classification des données de DataSecurity Plus avec une évaluation gratuite et entièrement fonctionnelle de 30 jours.
Téléchargez une version d'évaluation gratuite de 30 jours