Pourquoi avons-nous besoin de l’analyse de l’expérience numérique ?
Ralentissements du système. Plantages d’applications. Blocages. Voilà quelques-unes des plaintes les plus courantes adressées aux équipes informatiques, mais elles sont rarement accompagnées de détails exploitables. Un ticket peut simplement indiquer : "Mon ordinateur portable est lent". Mais qu’est-ce que cela signifie réellement ?
Les outils de surveillance traditionnels peuvent identifier ce qui ne va pas — une utilisation élevée du processeur, un espace disque insuffisant, des pics de mémoire — mais ils expliquent rarement pourquoi cela se produit ou comment cela impacte concrètement l’utilisateur final.
C’est là que réside le chaînon manquant.
Sans ce contexte, les équipes informatiques se retrouvent à faire des suppositions, ce qui ne fait qu’aggraver les problèmes et leur fait perdre un temps précieux à investiguer les symptômes plutôt qu’à en traiter la cause profonde.
L’analyse de l’expérience numérique comble cette lacune en transformant des plaintes vagues et des alertes fragmentées en informations claires et corrélées. Elle fournit aux équipes informatiques le contexte nécessaire pour établir un diagnostic plus rapide, proposer des solutions plus pertinentes et offrir une assistance proactive aux utilisateurs.
Comment les insights et l’analyse des causes profondes (RCA) simplifient le dépannage ?
La collecte de données télémétriques est essentielle. Mais sans interprétation, ces données ne font que signaler ce qui ne fonctionne pas, sans expliquer pourquoi.
C’est là que les fonctionnalités d’insights et d’analyse des causes profondes (RCA) de DEX Manager Plus entrent en jeu.
Lorsque les utilisateurs signalent des problèmes tels que « Mon système est lent » ou « Les applications plantent sans cesse », les équipes informatiques manquent souvent de clarté et de contexte. Les alertes classiques peuvent révéler une forte utilisation du processeur ou de la mémoire, mais elles n’indiquent pas l’origine du problème. Sans analyse approfondie, les équipes d’assistance sont contraintes de faire des suppositions, ce qui entraîne une perte de temps et l’accumulation de tickets non résolus.
Avec DEX Manager Plus, les données télémétriques ne sont pas seulement collectées : elles sont aussi interprétées.
Corrélation automatique et insights prioritaires
Voici comment cela fonctionne :
- Des seuils configurables déclenchent des alertes lorsqu’une métrique surveillée (comme l’utilisation du processeur ou de la mémoire) dépasse une valeur critique.
- Les alertes sont consolidées pour éviter la surcharge. Par exemple, si Microsoft Teams plante sur 100 machines, vous ne recevez pas 100 alertes distinctes mais une alerte unique, plus simple à traiter.
- Au lieu de voir uniquement l’incident, les équipes informatiques visualisent ce qui l’a provoqué, sa fréquence et les appareils systématiquement concernés. La corrélation automatique des composants impliqués fournit une vision globale et des diagnostics plus pertinents.
- Les composants corrélés sont classés par ordre de criticité grâce à un algorithme intégré, permettant au service informatique de savoir immédiatement ce qu’il faut corriger en priorité.
- Au-delà de l’analyse, DEX Manager Plus propose des mesures correctives ou des bonnes pratiques. Par exemple, si une alerte de plantage d’application est déclenchée, vous obtenez des détails précis (version concernée, fréquence des plantages, nombre de machines impactées) ainsi qu’une recommandation claire : revenir à une version plus stable ou mettre à jour vers une version corrigée.
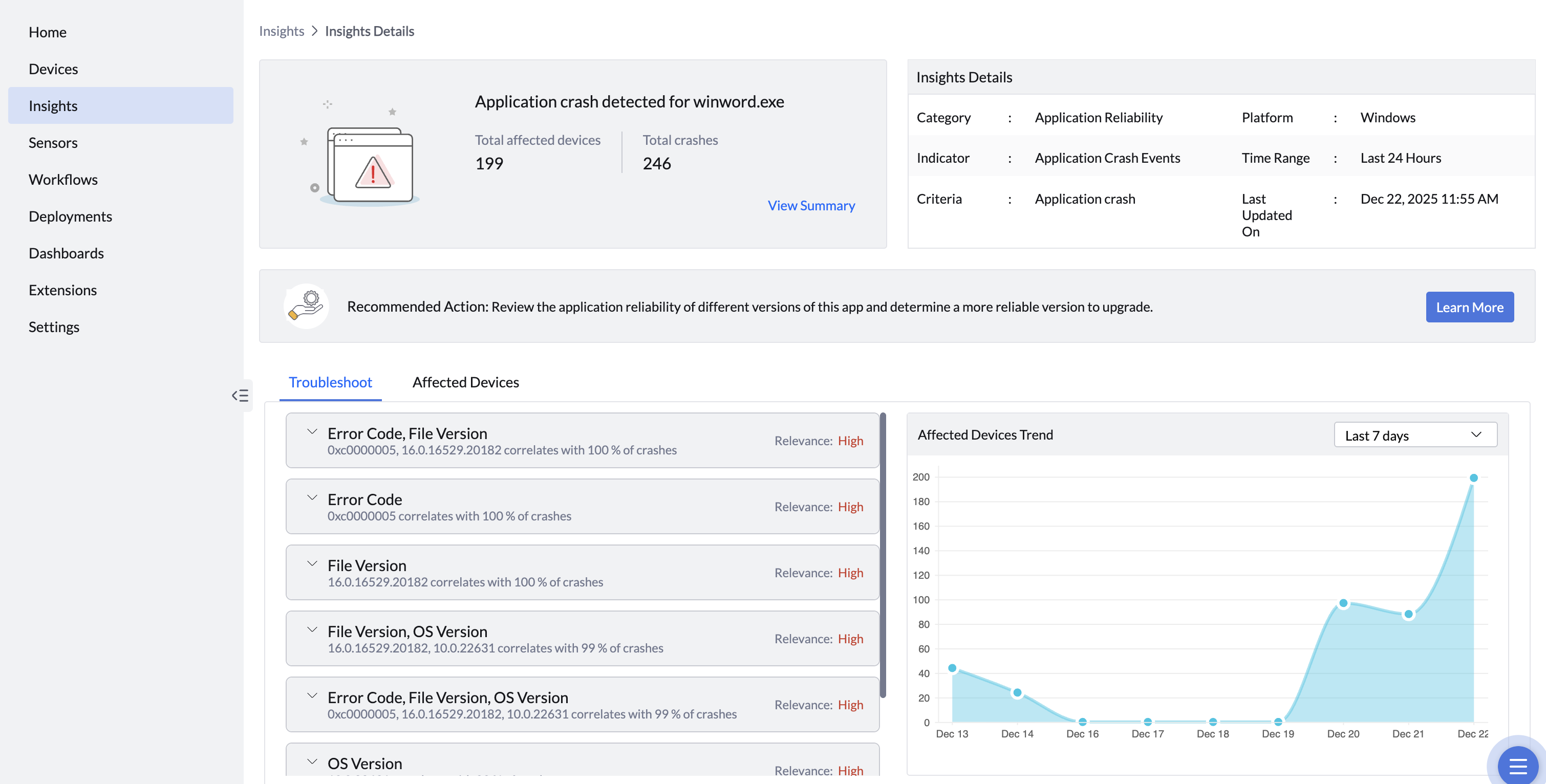
Cette capacité à transformer les données en contexte fait passer la collecte télémétrique d’un simple suivi à une véritable analyse de l’expérience
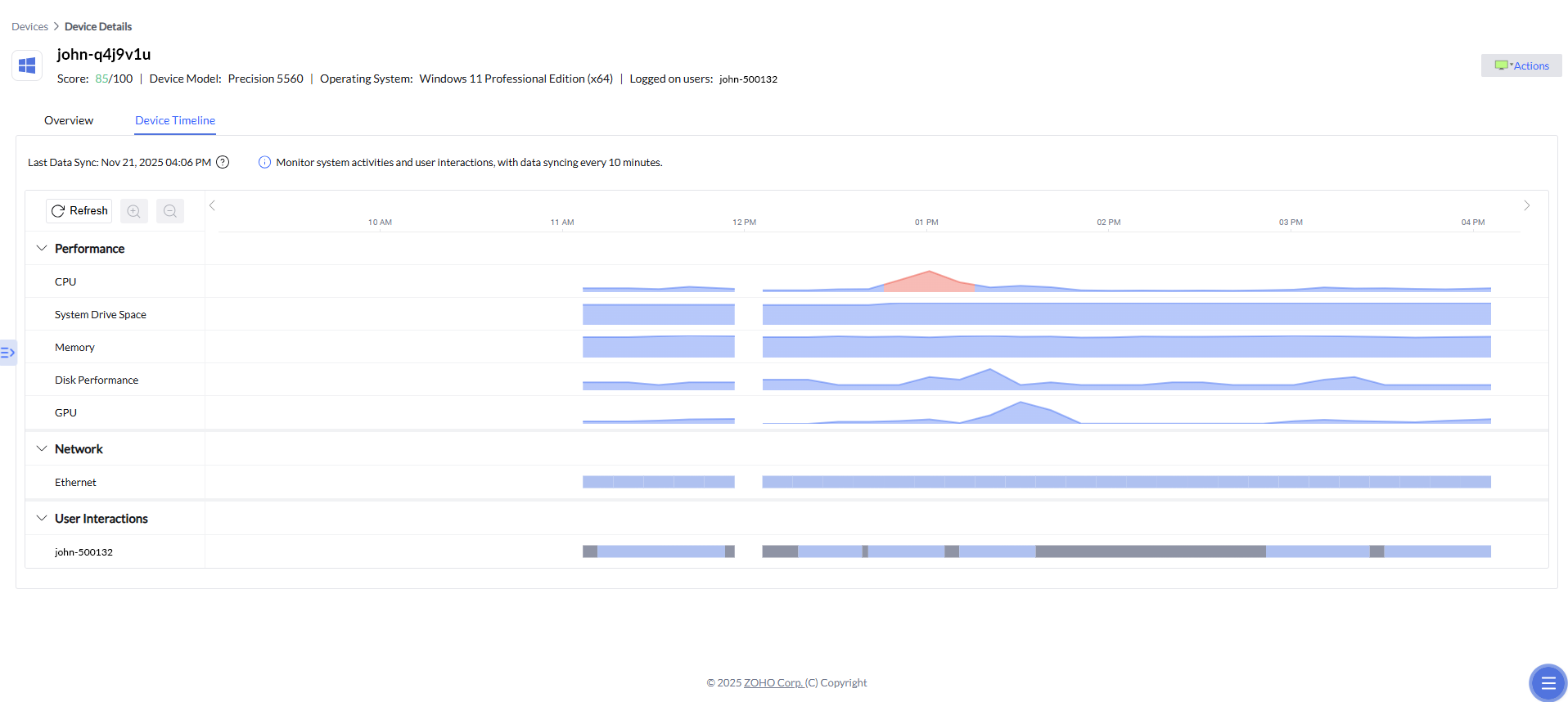
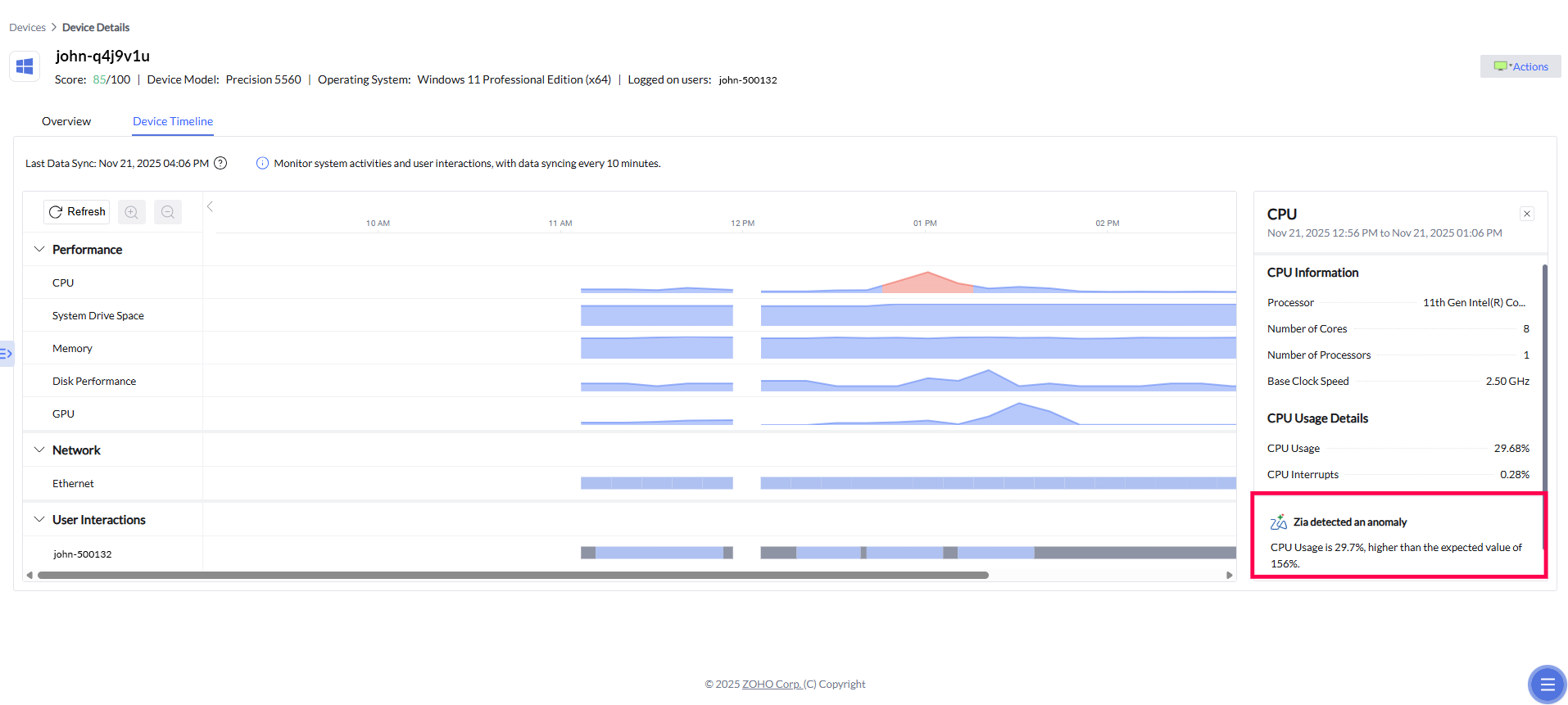
Chronologie des appareils
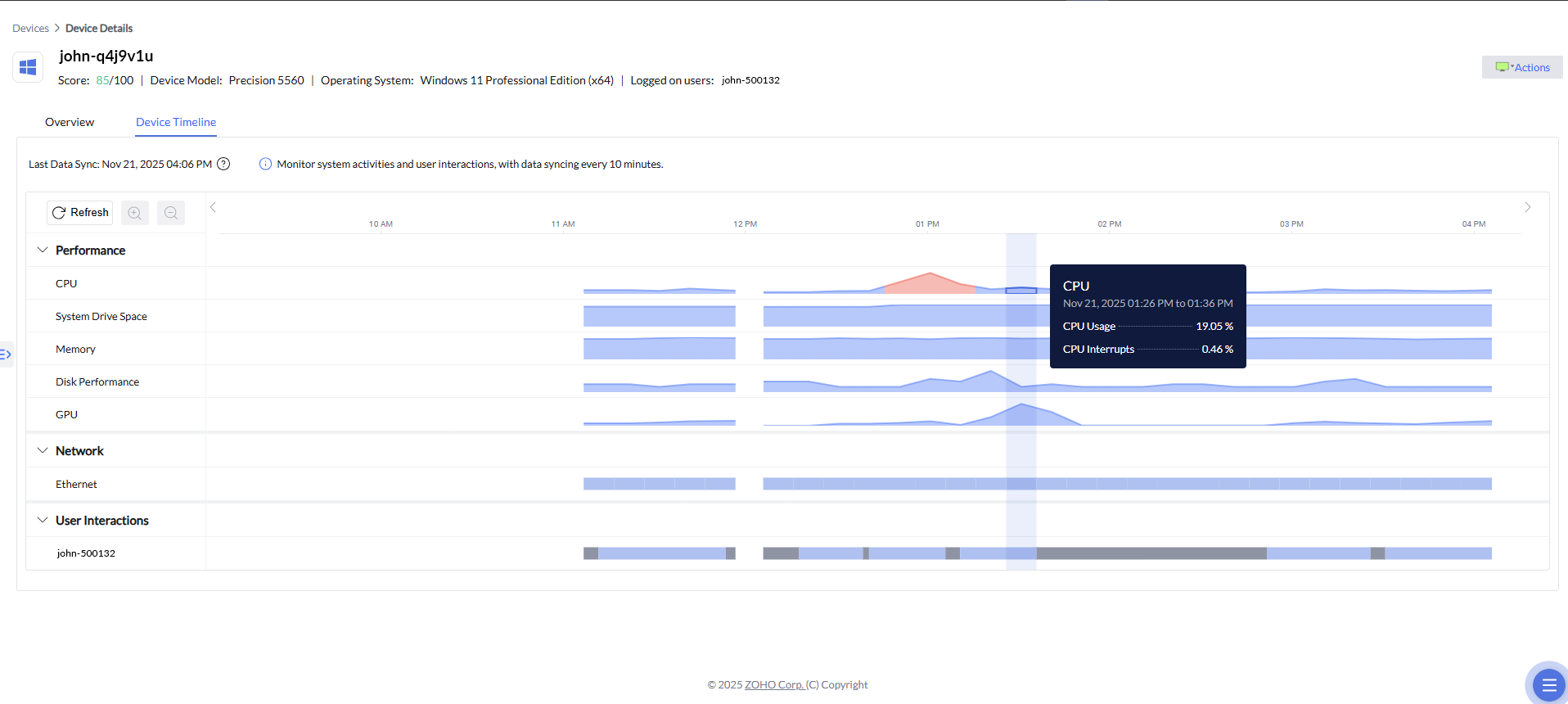
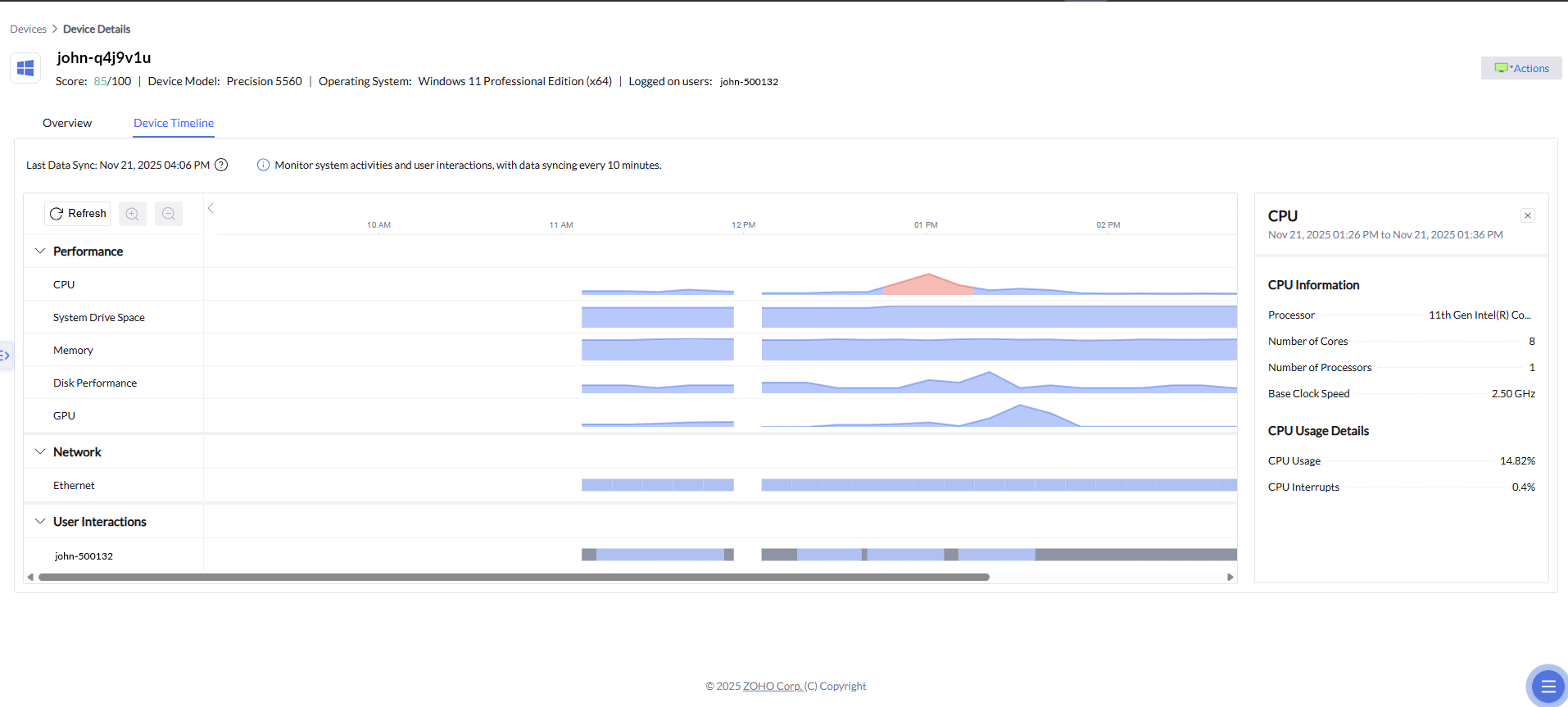
En plus des alertes corrélées et des analyses priorisées, la Chronologie des appareils ajoute une dimension temporelle essentielle à l’analyse des causes racines. Elle permet aux équipes IT de retracer visuellement le comportement d’un appareil avant, pendant et après un incident, en présentant les métriques de performance et de réseau sur une ligne du temps chronologique. Lorsqu’une alerte est déclenchée, les administrateurs peuvent accéder directement à la période exacte où le problème s’est produit et examiner les pics de CPU, la pression mémoire, l’activité disque ou les fluctuations réseau associées. Ce contexte historique aide à confirmer les relations de causalité, à distinguer les symptômes des causes profondes et à déterminer si un incident était isolé ou faisait partie d’un schéma plus large, ce qui accélère encore le diagnostic et permet de prendre des décisions de remédiation plus sûres et plus éclairées.
Détection d’anomalies Zia
S’appuyant sur le contexte historique fourni par la Chronologie des appareils, la détection d’anomalies de Zia ajoute une couche intelligente d’interprétation du comportement des appareils. En apprenant en continu ce qui constitue une performance « normale » pour chaque appareil au fil du temps, le système peut automatiquement signaler les écarts inhabituels de l’activité du CPU, du GPU ou de la mémoire lorsqu’ils se produisent. Ces anomalies sont mises en évidence directement dans la chronologie, permettant aux équipes IT d’identifier rapidement des pics, des baisses ou des schémas irréguliers inattendus et de comprendre dans quelle mesure ils s’écartent du comportement habituel. Au lieu d’analyser manuellement les métriques, les administrateurs sont guidés vers les moments les plus critiques, avec des informations contextuelles expliquant pourquoi l’écart est significatif — rendant l’analyse des causes racines plus rapide, plus précise et beaucoup moins dépendante des suppositions.
La prochaine étape pour renforcer le support informatique proactif et garantir une expérience numérique fluide consiste à automatiser la correction des problèmes détectés — en d’autres termes, à résoudre immédiatement les incidents qui dégradent ou risquent de dégrader l’expérience utilisateur