- Prevenzione della fuga di dati
- Valutazione dei rischi relativi ai dati
- Analisi dei file
- Controllo file
Contrassegno dei dati
Che cosa si intende per contrassegno dei dati?
Il contrassegno dei dati è il processo di assegnazione di un'etichetta a un dato, come un’immagine, un sito web o un video. I contrassegni associati sono spesso metadati che indicano il nome dell’autore, la data di creazione, il reparto, il formato di file o qualche altro dettaglio che li definisce. Questi contrassegni distinguono una serie di dati da altri dati all’interno di un ambiente, rendendoli semplici da cercare.
Perché il contrassegno dei dati è importante?
Il contrassegno dei dati fornisce un’identità ai tuoi dati associandoli ai metadati. In un’organizzazione, un ID dipendente ha lo scopo di fornire un’identificazione unica ai suoi dipendenti. Allo stesso modo, a una partita di calcio il numero di posto indica la postazione in cui ci si dovrà sedere allo stadio.
Un’analogia condivisa da questi scenari è che esiste un oggetto contrassegnato da un’etichetta. Tale etichetta assegna all’oggetto un’identificazione unica, fornendo:
- Identificazione senza sforzo
Nel caso di una partita di calcio, il numero di posto indica una postazione specifica allo stadio, eliminando lo sforzo di cercare il proprio posto a sedere.
- Categorizzazione facile
I nomi dei reparti categorizzano i dipendenti in gruppi riconoscibili.
- Sicurezza dei dati
Un ID dipendente fornisce informazioni sul dipendente, che possono essere utilizzate per offrire e limitare l’accesso a risorse organizzative, assicurando così la sicurezza dei dati.
Modelli di contrassegno dei dati
"I dati sono il nuovo petrolio" è una frase che abbiamo sentito di frequente nell’ultimo decennio ed è vero: siamo in presenza di organizzazioni che spendono somme ingenti nell’approvvigionamento di dati. Con il volume di archivi dati che si ritrovano le organizzazioni, esse hanno bisogno di una strategia per contrassegnare e organizzare i dati in modo efficiente. I seguenti sono modelli di contrassegno dei dati applicati dalle organizzazioni:
- Modello gerarchico
I contrassegni sono organizzati secondo un modello gerarchico, con le categorie più ampie in alto e contrassegni specifici in basso. Ad esempio, in un’applicazione come Spotify, la musica, i podcast e gli audiolibri saranno in alto, mentre al livello più basso vi saranno le sottocategorie per ciascuno, ovvero i generi, il supporto e la narrativa.
- Modello fisso
In un modello fisso, ogni contrassegno è importante allo stesso modo e non vi sono relazioni intrinseche tra i contrassegni.
- Modello a segmenti
Questo modello consiste nel contrassegnare i dati in base a segmenti. Ad esempio, SUV, tre volumi e due volumi potrebbero essere segmenti diversi in uno show room di auto.
- Modello basato sul linguaggio tecnico
Per il contrassegno può essere utilizzato il linguaggio tecnico riconoscibile tra i dipendenti all’interno di un’organizzazione o un reparto.
Diversi tipi di contrassegno di dati
Il contrassegno dei dati può essere classificato, in senso ampio, in diversi tipi a seconda del formato di dati da contrassegnare. La classificazione potrebbe riguardare testi, immagini o video. Inoltre, ognuno di questi formati può essere classificato ulteriormente in base alla funzionalità. Esistono sottoclassificazioni, tra cui:
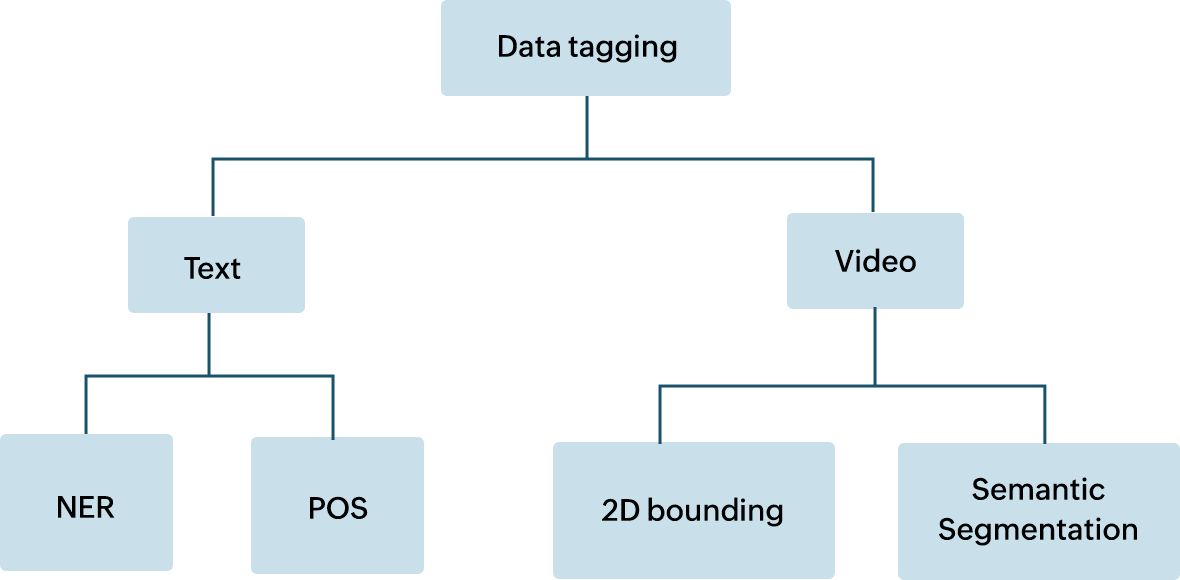
- Riconoscimento entità denominata
Il riconoscimento entità denominata aiuta nell’identificazione di entità, come nomi, luoghi e oggetti, nel corpo di un testo.
- Contrassegno di parti del discorso
Il contrassegno di parti del discorso riguarda l’associazione di parole in una frase alla parte grammaticale di un discorso.
- Segmentazione semantica
È il processo di contrassegno di ogni singolo pixel che fa parte di un’immagine.
- Delimitazione bidimensionale
Si tratta di disegnare una delimitazione attorno all’oggetto desiderato, per renderlo riconoscibile.
Procedure consigliate per il contrassegno dei dati
L’obiettivo primario del contrassegno di dati è quello di semplificare la vita all’utente finale, limitando il tempo che serve per eseguire la noiosa attività di ricerca dei dati. Pertanto, è imperativo che la tua strategia di contrassegno dei dati sia semplice da usare. Ecco alcune procedure consigliate che potrebbero facilitare l’esperienza:
-
Presenza di una nomenclatura ben definita
La presenza di convenzioni di denominazione a livello di organizzazione o reparto può aiutare i dipendenti a spostarsi tra i vari file e a recuperarli. Una nomenclatura ben definita deve essere riconoscibile da un utente finale. Pertanto, fai in modo di utilizzare parole chiave come reparto, progetto, manager, team e altri identificatori pertinenti. -
Costruzione di un modello
Un modello di contrassegno dei dati dà struttura ai tuoi dati e contribuisce alla loro classificazione. Come discusso in precedenza in questa pagina, ne esistono di vari tipi tra cui scegliere. -
Esecuzione di valutazioni sull’usabilità
L’esecuzione periodica di valutazioni di usabilità può migliorare l’efficienza del contrassegno di dati. I report di usabilità devono prendere in considerazione fattori quali accessibilità semplice e tempo trascorso a recuperare file. -
Automazione del processo di contrassegno dei dati
Il contrassegno manuale dei dati richiede un numero eccessivo di ore di lavoro ed è più a rischio di errore umano. Pertanto, automatizzare il processo di contrassegno dei dati con il Machine Learning potrebbe dimostrarsi inestimabile.
Classificazione e contrassegno dei dati
Il contrassegno e la classificazione dei dati sono spesso utilizzati in modo intercambiabile, ma sono due facce della stessa medaglia, ognuna di esse con una propria significatività.
Il contrassegno dei dati è l'etichettatura dei dati in base a meta-informazioni, quali nome progetto, proprietario del file o tipo di dati, e mira migliorare l’accessibilità e l’organizzazione. D’altra parte, la classificazione dei dati viene eseguita in base al livello di riservatezza del contenuto di un file, mira alla protezione dei dati sensibili e può essere utilizzata per contrassegnare dati sensibili da strumenti per la prevenzione della perdita di dati. Una strategia ben bilanciata di contrassegno e classificazione dei dati può garantire un’esplorazione senza problemi e la sicurezza di rete.
Impara la sostanza della classificazione dei dati nel nostro webinar su richiesta Classificazione dei dati: Fondamento della prevenzione della fuga di dati.
Individua e classifica i tuoi dati con DataSecurity Plus
DataSecurity Plus offre uno strumento di individuazione dei dati che automatizza il processo di classificazione dei file attraverso un sistema di etichettatura gerarchico. Lo strumento di individuazione e classificazione dei dati rileva, classifica e protegge i dati sensibili, come dati personali, informazioni sulle carte di pagamento, dati sanitari protetti, eccetera, garantendo la conformità alle normative.
DataSecurity Plus è dotato delle seguenti funzioni:
- Reporting in tempo reale su tipo, volume e posizione dei dati sensibili.
- Regole personalizzabili di individuazione dei dati per definire dati sensibili specifici dell’organizzazione.
- Avvisi di tracciatura dei file che contengono corrispondenze per le leggi sulla protezione dei dati, come GDPR, PCI DSS, e così via.
- Scansioni incrementali di individuazione dei dati per creare e mantenere un inventario dei tuoi dati più sensibili.
Prova la classificazione dei dati di DataSecurity Plus con una prova gratuita di 30 giorni, completamente funzionale.
Scarica una prova gratuita di 30 giorni