
La genómica es la rama de la biología molecular que se centra en la estructura, función, evolución y cartografía de los genomas, que son los conjuntos completos de ADN de un organismo, incluidos todos sus genes. A diferencia de la genética, que suele estudiar los genes individuales y su rol en la herencia, la genómica examina todos los genes y sus interrelaciones para comprender su influencia combinada en la biología, el desarrollo y la salud del organismo. Utiliza herramientas avanzadas como la secuenciación del ADN, el análisis computacional y la biología de sistemas para descodificar e interpretar datos biológicos complejos.
En esta página
Las plataformas de genómica y medicina personalizada están en la vanguardia de la innovación sanitaria. Al analizar el ADN de un paciente y otros datos biológicos, estas plataformas permiten realizar tratamientos precisos y a medida para afecciones que van desde el cáncer hasta trastornos genéticos raros. Los datos genómicos son complejos y voluminosos. Por ello, los investigadores recurrieron a servicios en la nube, bases de datos y aplicaciones de software bioinformático para desarrollar fármacos y secuenciar, descodificar y compartir los datos analizados.
Mientras tanto, los particulares están aprovechando los servicios de pruebas genéticas directas al consumidor, como 23andMe y Mapmygenome, para explorar su ascendencia y sus predisposiciones genéticas. Esto introduce riesgos de ciberseguridad, especialmente en torno a la confidencialidad e integridad de los datos genómicos. Un buen ejemplo de ello es la violación de la seguridad de los datos de 23andMe que se produjo en julio de 2023 y que supuso para la empresa una multa de £2,31 millones en junio de 2025. La seguridad de los datos genómicos se ha convertido en una prioridad crítica para los proveedores de atención sanitaria, los investigadores y las industrias relacionadas.
Genómica y medicina personalizada: Una visión general
La genómica es el estudio de toda la secuencia del ADN de un individuo, incluidos todos sus genes, y de cómo estos genes interactúan entre sí y con el medio ambiente. Los avances en genómica han permitido a investigadores y profesionales sanitarios analizar la información genética y allanar el camino hacia la atención sanitaria personalizada.
La genómica y la medicina personalizada están estrechamente interrelacionadas de las siguientes maneras:
- La genómica permite una atención médica precisa: La medicina personalizada, también conocida como medicina de precisión, se basa en datos genómicos para adaptar los tratamientos médicos a cada paciente de acuerdo con sus perfiles genéticos, su estilo de vida y sus factores ambientales. Los profesionales de la salud pueden predecir los riesgos de padecer alguna enfermedad, optimizar las terapias farmacológicas, desarrollar intervenciones específicas y mejorar los resultados de los pacientes analizando la composición genética de una persona.
- Predicción y prevención de enfermedades: Los estudios genómicos ayudan a identificar predisposiciones genéticas a enfermedades como el cáncer, los trastornos cardiovasculares y las afecciones neurológicas. También ayudan a descubrir biomarcadores que indican la progresión de la enfermedad o la respuesta al tratamiento. Esto permite una intervención temprana y estrategias preventivas. Por ejemplo, en la atención oncológica, el perfil genómico de los tumores permite a los oncólogos identificar las mutaciones causantes y elegir terapias dirigidas, como el tratamiento dirigido a HER2 en el cáncer de mama.
- Farmacogenómica y respuesta a los medicamentos: La genómica desempeña un rol crucial en la farmacogenómica, que estudia cómo las variaciones genéticas afectan a la respuesta de un individuo a los fármacos. Por ejemplo, la información genómica puede revelar cómo el organismo de un paciente podría metabolizar fármacos específicos como la Warfarin (un anticoagulante), si presenta variaciones en el gen CYP2C9. Esto puede ayudar a los médicos a personalizar la dosis para reducir el riesgo de hemorragia y mejorar la eficacia del tratamiento.
Las plataformas de medicina personalizada integran herramientas bioinformáticas, algoritmos de ML e infraestructura en la nube para analizar conjuntos de datos genómicos masivos, incluida la secuenciación del genoma completo, la secuenciación del ARN y los conjuntos de genotipado de forma eficiente. Sin embargo, esto amplía la superficie de ataque y presenta retos complejos que exigen adoptar un enfoque de seguridad estratégico y basado en los riesgos.
Retos de seguridad en las plataformas de genómica y medicina personalizada
La infraestructura digital que respalda la genómica y la medicina personalizada presenta problemas críticos de ciberseguridad, como se menciona a continuación:
- Privacidad de los datos: Los datos genómicos son inmutables, identificables personalmente y, a diferencia de una contraseña robada o una tarjeta de crédito, no se pueden restablecer ni modificar una vez expuestos. Una brecha no sólo compromete la privacidad del paciente; puede exponer información hereditaria que afecta a familias enteras. También aumenta el riesgo de robo de identidad y de discriminación genética.
- Integridad de los datos: Las organizaciones de investigación y las empresas de análisis suelen almacenar terabytes de datos genéticos en bruto y procesarlos en servicios en la nube o en plataformas bioinformáticas de terceros. Los ataques cibernéticos dirigidos contra las bases de datos genómicas pueden manipular la información genética, resultando en diagnósticos o recomendaciones de tratamiento incorrectos. Además, los entornos en nube mal configurados, la falta de cifrado y las API inseguras pueden dar lugar a accesos no autorizados, fugas de datos y riesgos para la cadena de suministro en la nube.
- Falta de medidas de seguridad estandarizadas: El rápido crecimiento de la investigación genómica ha superado el desarrollo de protocolos estandarizados de ciberseguridad, dejando lagunas en la protección de datos. Según un informe del NIST de 2023, las lagunas identificadas por las partes interesadas incluyen:
- Prácticas a lo largo del ciclo de vida relativas a la generación de datos genómicos
- Intercambio seguro y responsable de datos genómicos
- Monitoreo de los sistemas que procesan los datos genómicos
- Falta de directrices claras que aborden las necesidades específicas de los encargados del tratamiento de datos genómicos
- Lagunas normativas/políticas con respecto a las amenazas para la seguridad nacional y la privacidad durante la recopilación, el almacenamiento, la transferencia y la agregación de datos genómicos humanos.
- Riesgos de colaboración con terceros y de investigación: La investigación genómica a menudo implica compartir datos con colaboradores externos, como instituciones académicas y empresas biotecnológicas. Desde los socios bioinformáticos hasta los proveedores de almacenamiento en la nube, cada integración de terceros aumenta los posibles puntos de entrada. Las amenazas internas y las colaboraciones de investigación inseguras complican aún más la gobernanza. La figura 1 muestra el flujo de trabajo de la secuenciación de datos genómicos tal y como se documenta en la ficha informativa del NIST sobre ciberseguridad y privacidad de los datos genómicos. Como se muestra en la figura 1, el investigador envía una muestra de ADN al secuenciador del genoma, que genera los resultados de la secuenciación digital para su posterior análisis. Sin embargo, utilizar software de código abierto no fiable en este proceso amplía la posible superficie de ataque.
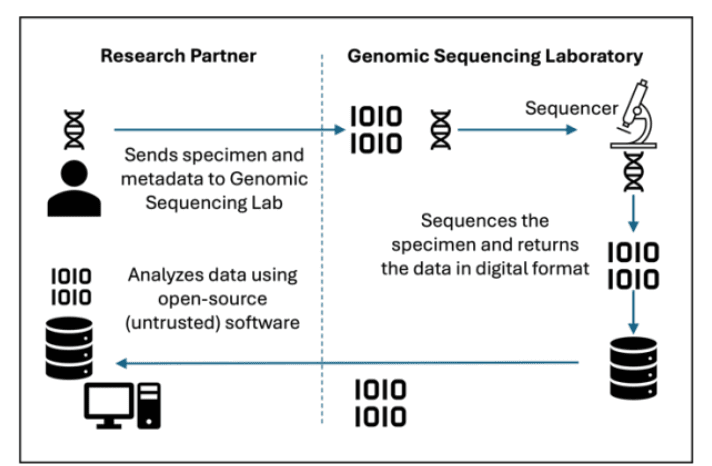
Fuente de la imagen: Ficha informativa del NIST
Figura 1: Flujo de trabajo de la secuenciación de datos genómicos
- Complejidad normativa: El uso de los datos genómicos está controlado por estrictos requisitos de cumplimiento, como la HIPAA, el GDPR y la Ley de no discriminación por información genética (GINA). Estas normas son difíciles de cumplir y una infracción puede acarrear importantes multas y consecuencias legales para las organizaciones que manejan datos genómicos.
Vulnerabilidades comunes y posibles ataques a las herramientas bioinformáticas
Según la revista Journal of Biomedical Informatics, las vulnerabilidades comunes en las herramientas bioinformáticas son las siguientes:
- Saneamiento deficiente del código y validación insuficiente de las entradas: Muchas aplicaciones bioinformáticas carecen de mecanismos robustos para validar y sanear las entradas del usuario, lo que las hace susceptibles de sufrir ataques de inyección y corrupción de datos.
- Uso de funciones obsoletas o inseguras: La dependencia de funciones de programación obsoletas o inseguras, como gets(), scanf(), strlen() y strcpy(), puede dar lugar a vulnerabilidades como desbordamientos de búfer, que los atacantes podrían aprovechar para ejecutar código arbitrario.
- Transmisión a través de canales inseguros: Algunas bases de datos genómicos implementan protocolos de autentificación mínimos y controles de acceso inadecuados, especialmente durante la descarga de datos genómicos. A menudo, estas bases de datos carecen de directivas de MFA o de contraseñas seguras, lo que aumenta el riesgo de acceso no autorizado a los datos.
- Transmission over insecure channels: La transmisión de datos genómicos sensibles a través de protocolos inseguros como HTTP en lugar de HTTPS los hace vulnerables a los ataques de manipulator-in-the-middle.
- Disponibilidad pública de datos sensibles: El intercambio abierto de conjuntos de datos genómicos, aunque es beneficioso para la investigación, puede exponer inadvertidamente la PII e impactar en la privacidad e integridad de los datos genómicos.
El mismo artículo enumera los posibles ataques cibernéticos a las herramientas bioinformáticas que procesan datos genómicos, como se muestra en la figura 2.
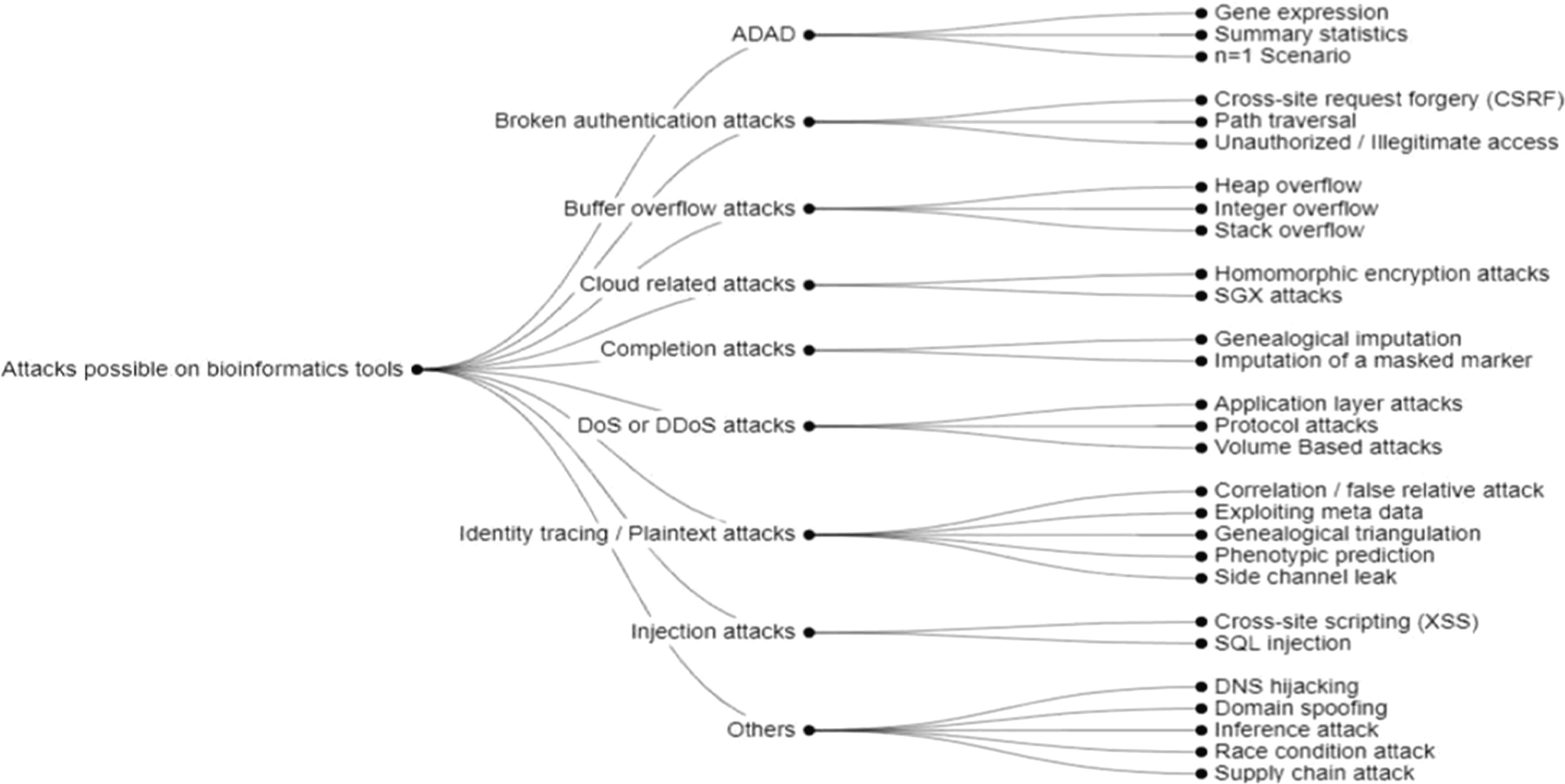
Fuente de la imagen: Revista Journal of Biomedical Informatics
Figura 2: Posibles ataques a las herramientas bioinformáticas
Algunos de estos ataques son:
- Ataques de divulgación de atributos mediante ADN (ADAD): Los ataques de ADAD utilizan técnicas como el análisis de perfiles de expresión genética o estadísticas resumidas para identificar a los individuos a partir de conjuntos de datos anonimizados, lo que compromete la privacidad.
- Ataques para eludir la autenticación: Los ataques de autenticación basados en la web más comunes contra el software bioinformático son los siguientes:
- Falsificación de solicitud entre sitios: Engaña a los usuarios autentificados para que ejecuten acciones no deseadas.
- Recorrido de ruta: Permite el acceso no autorizado a archivos fuera de los directorios previstos y se lleva a cabo aprovechando URL, llamadas al sistema o comandos de shell.
- Robo de credenciales: Explota la autenticación débil para comprometer las credenciales del usuario (por ejemplo, claves, contraseñas y tokens) y hacerse pasar por usuarios legítimos.
- Ataques de desbordamiento del búfer: Los atacantes aprovechan las vulnerabilidades del software para sobrescribir la memoria y ejecutar código malicioso.
- Ataques relacionados con la nube: Los atacantes suelen apuntar a buckets de almacenamiento mal configurados, a una seguridad de API débil y a controles de acceso inadecuados, lo que conduce al acceso no autorizado de información genética sensible. Además, pueden explotar las vulnerabilidades en los conductos bioinformáticos basados en la nube o aprovechar las integraciones inseguras de terceros para exfiltrar datos.
- Ataques de relleno de datos: Para reconstruir perfiles genéticos completos a partir de datos parciales, los atacantes pueden aprovechar el desajuste de vinculación entre los marcadores genéticos y los paneles de referencia que contienen información genética completa.
- Ataques de denegación de servicio: Los atacantes pueden saturar los servidores bioinformáticos con solicitudes excesivas, haciendo que los servicios no estén disponibles para los usuarios legítimos.
- Ataques de rastreo de identidad: Los ciberatacantes localizan la identidad de una muestra de ADN anónima aprovechando los cuasi-identificadores del conjunto de datos para establecer una coincidencia única. Estos ataques pueden llevarse a cabo mediante la correlación con bases de datos públicas, la triangulación genética, la explotación de metadatos, la predicción de fenotipos o las fugas de canales laterales.
- Ataques de inyección: Los atacantes pueden ejecutar ataques de inyección SQL o scripting entre sitios en aplicaciones web bioinformáticas.
- Ataques a la cadena de suministro de software: Los atacantes pueden insertar código malicioso en los componentes de software de terceros que se utilizan en los conductos bioinformáticos, lo que provoca vulnerabilidades generalizadas.
- Secuestro de DNS: Los atacantes redirigen el tráfico de las bases de datos genómicas legítimas a sitios maliciosos.
- Ataques de condición de carrera: Los atacantes pueden aprovecharse de los problemas de sincronización en los procesos de software para ejecutar acciones no autorizadas.
Cómo prevenir la violación de los datos genómicos
Para prevenir las violaciones de los datos genómicos se debe adoptar un enfoque de varios niveles que combine las mejores prácticas de ciberseguridad, el cumplimiento normativo y las tecnologías avanzadas.
1. Utilice técnicas de cifrado sólidas
- Cifre los datos genómicos tanto en reposo como en tránsito para evitar accesos no autorizados.
- Implemente un cifrado resistente al quantum para protegerse de futuras amenazas.
2.Implemente controles de acceso estrictos
- Utilice la MFA para garantizar que sólo el personal autorizado pueda acceder a las bases de datos genómicas.
- Implemente un control de acceso basado en roles para limitar la exposición de los datos.
3. Aproveche la detección de amenazas basada en IA
- Implemente sistemas de seguridad basados en IA para identificar anomalías y posibles infracciones en tiempo real.
- Utilice modelos de ML para detectar patrones de acceso inusuales.
4. Utilice blockchain para la integridad de los datos
- Utilice la tecnología blockchain para crear registros inmutables de las transacciones de datos genómicos.
- Garantice la transparencia y la seguridad en el intercambio de datos al tiempo que evita modificaciones no autorizadas.
5. Garantice el cumplimiento de las regulaciones y las normas éticas
- Implemente controles para adherirse a las leyes de protección de datos como el GDPR, la HIPAA, la GINA y el CSF del NIST.
- Establish clear consent policies for individuals sharing their genetic information.
6. Establezca directivas claras de consentimiento para las personas que compartan su información genética.
- Implemente soluciones de SIEM para monitorear en tiempo real.
- Desarrolle un plan de respuesta rápida a incidentes para mitigar las brechas de forma efectiva.
7. Aproveche las tecnologías de preservación de la privacidad
- Utilice el aprendizaje federado para analizar datos genómicos sin exponer la información genética en bruto.
- Emplee un cifrado homomórfico seguro para permitir que se realicen cálculos sobre los datos cifrados sin descifrarlos.
¿Cómo pueden las soluciones de SIEM garantizar la ciberseguridad en la genómica?
Las soluciones de SIEM pueden mejorar la ciberseguridad en las plataformas de genómica y medicina personalizada proporcionando:
- Visibilidad centralizada y monitoreo de la seguridad en tiempo real: Las soluciones de SIEM consolidan los logs y la telemetría de los proveedores de la nube, las herramientas bioinformáticas, los endpoints y las sesiones de usuario. Esto permite a los equipos de seguridad detectar comportamientos anómalos, como grandes descargas de secuencias de ADN o un uso indebido de la API; correlacionar las amenazas en todos los entornos; y automatizar las alertas y orquestar la respuesta a los incidentes. Las soluciones de SIEM también se integran con las herramientas de DLP y CASB para monitorear los flujos de datos y bloquear las transferencias o cargas no autorizadas de datos genómicos.
- Detección de amenaza interna: Las soluciones de SIEM vienen con funciones de análisis del comportamiento de usuarios y entidades que aprovechan los algoritmos de ML para aprender el comportamiento normal de los usuarios e identificar anomalías, como investigadores que acceden a conjuntos de datos fuera del alcance, picos repentinos en la actividad de exfiltración de datos o el uso indebido de accesos privilegiados. Esto es fundamental en los entornos de investigación en donde los roles de los empleados y las necesidades de acceso a los datos son muy dinámicos.
- Apoyo para el cumplimiento normativo: Con dashboards de cumplimiento predefinidos para la HIPAA, el GDPR, y el CSF del NIST, las soluciones de SIEM pueden generar informes listos para la auditoría, proporcionar logs inmutables para las investigaciones forenses y demostrar los controles de seguridad durante las inspecciones reglamentarias.
- Monitoreo de la web oscura e inteligencia sobre amenazas: Las soluciones de SIEM se pueden integrar con herramientas de monitoreo de la web oscura y fuentes de información sobre amenazas para detectar conjuntos de datos genómicos filtrados, robo de credenciales de investigadores o administradores e IoC de amenazas persistentes avanzadas conocidas dirigidas a la biotecnología y la sanidad.
- Respuesta automatizada y manuales estratégicos: La orquestación, automatización y respuesta de seguridad es una función básica de las soluciones de SIEM modernas que puede ayudar a los equipos de seguridad a automatizar el bloqueo de IP o usuarios maliciosos y ejecutar acciones de flujo de trabajo para contener amenazas como el ransomware, la exfiltración de datos y el compromiso de cuentas.
A medida que la secuenciación genómica y la medicina personalizada siguen evolucionando, es fundamental proteger estas plataformas de los ataques cibernéticos. Al implementar la SIEM, el monitoreo basado en IA y el cifrado, los CISO del sector de la salud pueden proteger las bases de datos genéticas, garantizar el cumplimiento de las normativas y fomentar la confianza en los sistemas de salud basados en datos.
Preguntas frecuentes
Los datos genómicos son altamente sensibles, identificables de forma única e inmutables: no pueden cambiarse como una contraseña. Contienen información no sólo sobre un individuo, sino también sobre sus parientes y rasgos hereditarios. Esto los hace extremadamente valiosos para el comercio en el mercado negro, el robo de identidades, el fraude en los seguros e incluso la investigación de armas biológicas. Los atacantes también pueden atacar a empresas de pruebas genéticas e instituciones de investigación para robarles propiedad intelectual, como algoritmos de secuenciación patentados o modelos terapéuticos.
La genómica es fundamental para la medicina personalizada porque permite ofrecer una atención de salud a medida basándose en el perfil genético de cada individuo. Analizando el genoma de un paciente, los médicos pueden:
- Predecir la susceptibilidad a ciertas enfermedades (por ejemplo, cáncer, diabetes, trastornos genéticos raros).
- Determinar cómo puede responder una persona a determinados medicamentos (farmacogenómica).
- Personalizar las estrategias de prevención, diagnóstico y tratamiento en función de su perfil genético.
La información genómica permite pasar de un modelo único a un enfoque basado en la precisión que mejora los resultados y minimiza los efectos secundarios.
La bioinformática es esencial en la medicina personalizada, ya que ayuda a procesar, analizar e interpretar enormes cantidades de datos biológicos y genómicos. Los roles clave incluyen:
- Alinear y anotar secuencias de ADN o ARN de pacientes.
- Identificar variantes genéticas vinculadas a la enfermedad o a la respuesta a fármacos.
- Integrar datos procedentes de la genómica, la proteómica y los historiales clínicos.
- Permitir el desarrollo de modelos predictivos para diagnosticar y tomar decisiones sobre el tratamiento.
El software y las aplicaciones bioinformáticas permiten a los investigadores y a los médicos traducir los datos genéticos sin procesar en información práctica, como identificar mutaciones que influyen en la elección de las terapias contra el cáncer o el manejo de enfermedades raras.
La genómica tiene varias aplicaciones en medicina, como predecir el riesgo de padecer una enfermedad, orientar el tratamiento del cáncer elaborando perfiles tumorales y adaptar las terapias farmacológicas en función de la composición genética. También ayuda en la detección temprana de trastornos genéticos raros, el cribado prenatal y el seguimiento de enfermedades infecciosas analizando genomas de patógenos.
La medicina personalizada implica integrar datos genómicos, conductuales y clínicos, a menudo a través de múltiples jurisdicciones. Esto crea dificultades para:
- Garantizar el consentimiento informado para cada caso de uso
- Minimizar los datos y limitar su finalidad
- Gestionar las transferencias de datos transfronterizas
- Tratar la información genética como datos de identificación personal en virtud de leyes que evolucionan como la GINA y el GDPR
Para garantizar el cumplimiento continuo se requiere una gobernanza dinámica de los datos y una trazabilidad lista para la auditoría.
Soluciones relacionadas
ManageEngine AD360 es una solución de IAM unificada que proporciona SSO, MFA adaptable, análisis impulsado por UBA y RBAC. Gestione las identidades digitales de los empleados e implemente la confianza cero y los principios del mínimo privilegio con AD360.
Para obtener más información,
Regístrese para una demostración personalizadaManageEngine Log360 es una solución de SIEM con funciones de UEBA, DLP, CASB y monitoreo de la web oscura. Proteja la infraestructura multi nube y obtenga informes listos para auditoría para la HIPAA, el GDPR y el CSF del NIST con Log360.
Para obtener más información,
Regístrese para una demostración personalizadaEste contenido ha sido revisado y aprobado por Ram Vaidyanathan, consultor de tecnología y seguridad de TI en ManageEngine.
