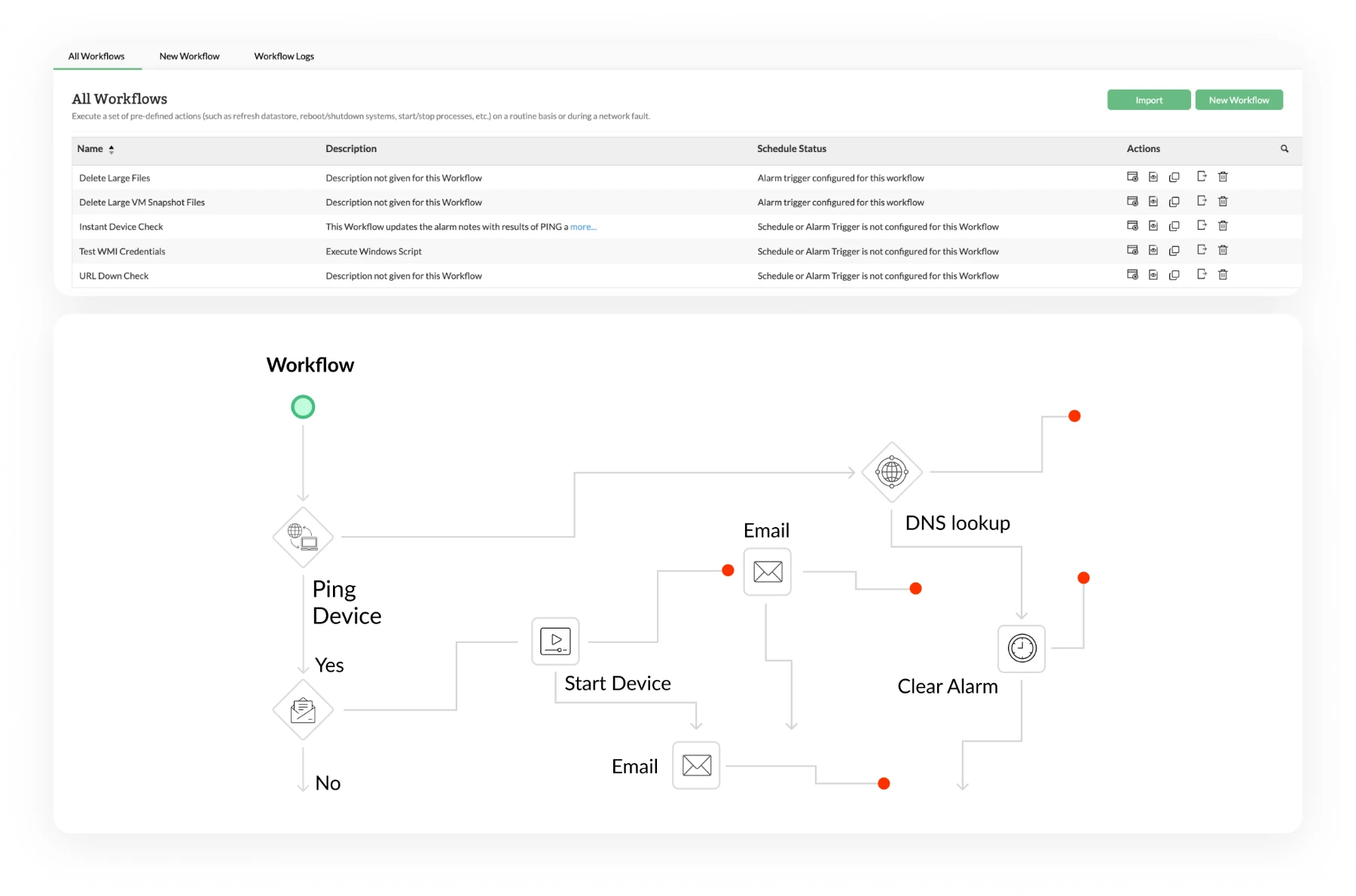
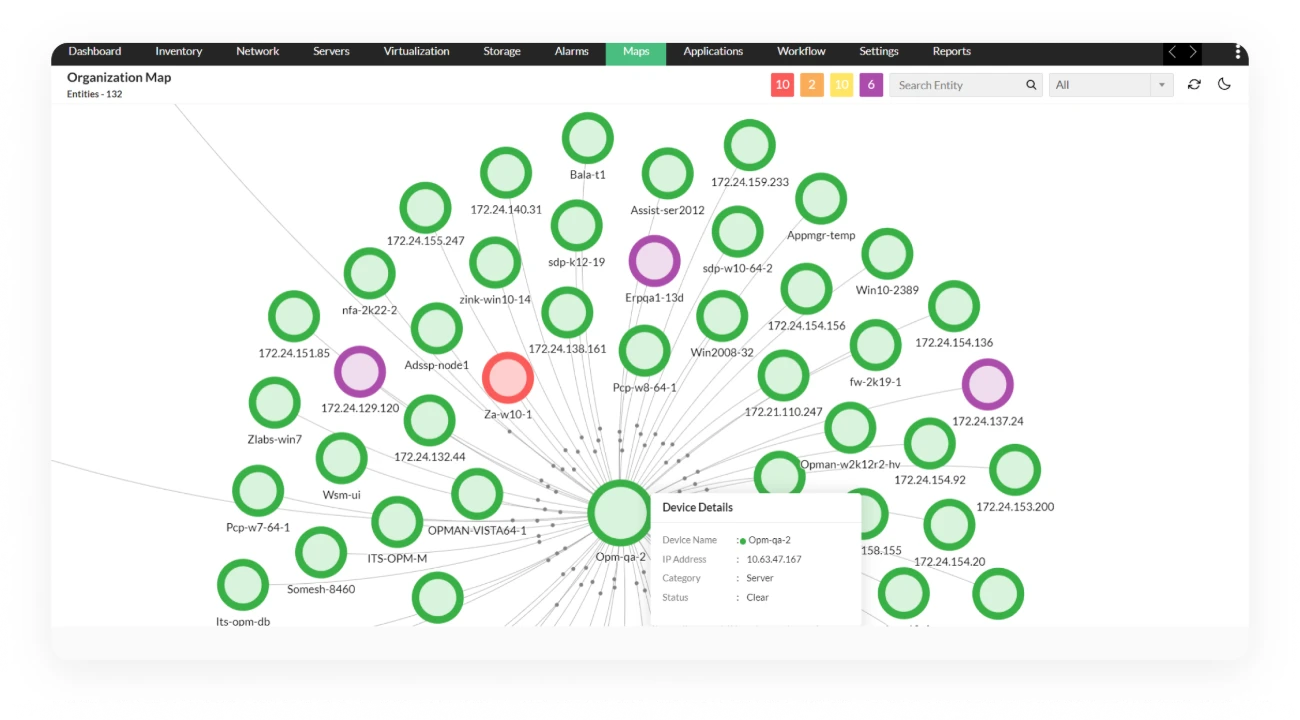
Prevent VM slowdowns in VMware & Hyper-V by watching the host layer
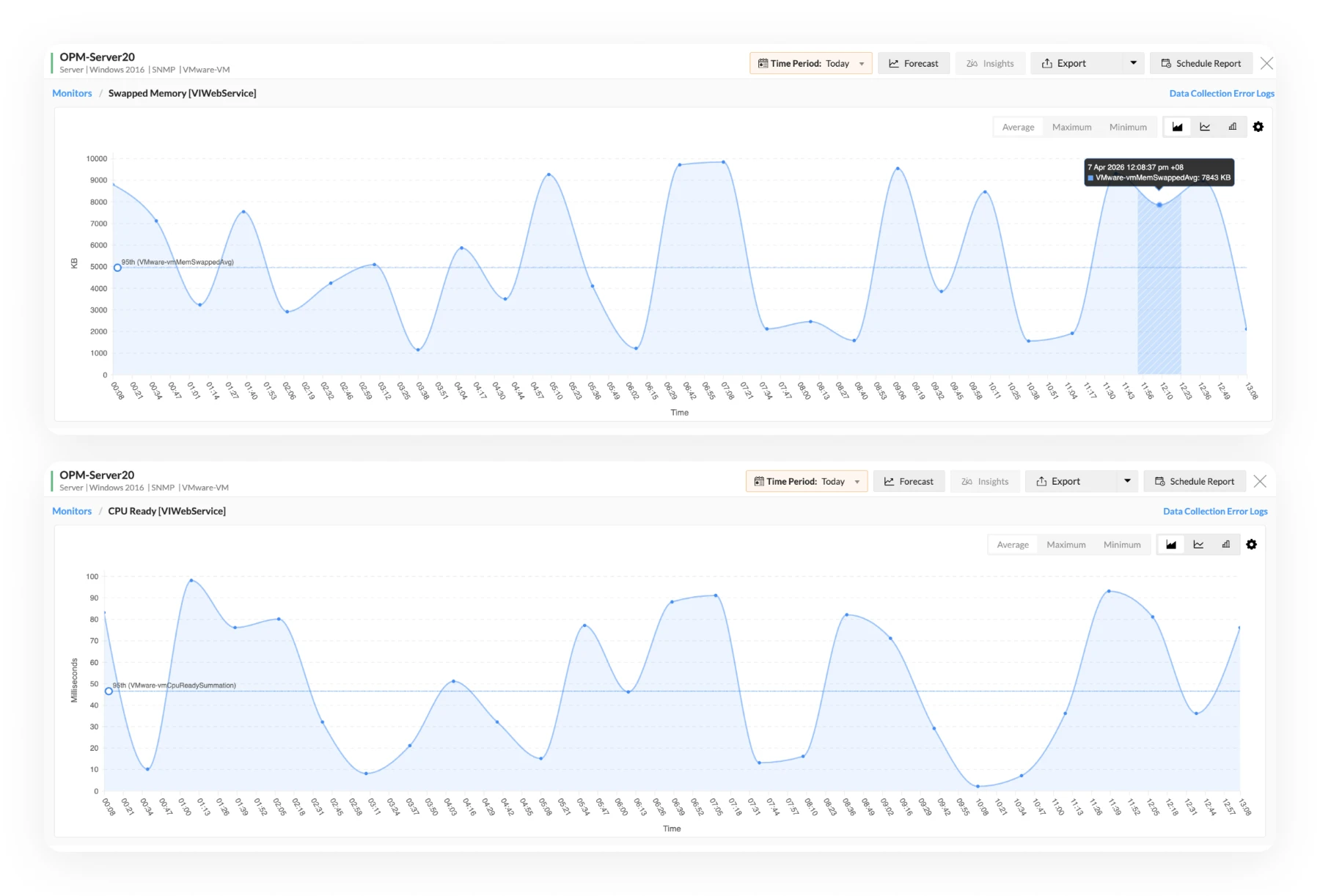
- Identify CPU scheduling delays that traditional monitoring misses: A VM may have CPU assigned, but still be waiting to run. OpManager helps you catch that kind of contention early through metrics like CPU ready time across VMware and Hyper-V environments.
- Track memory pressure beyond basic utilization: See when hosts are reclaiming memory through ballooning, swapping, or compression, so hidden pressure is easier to spot.
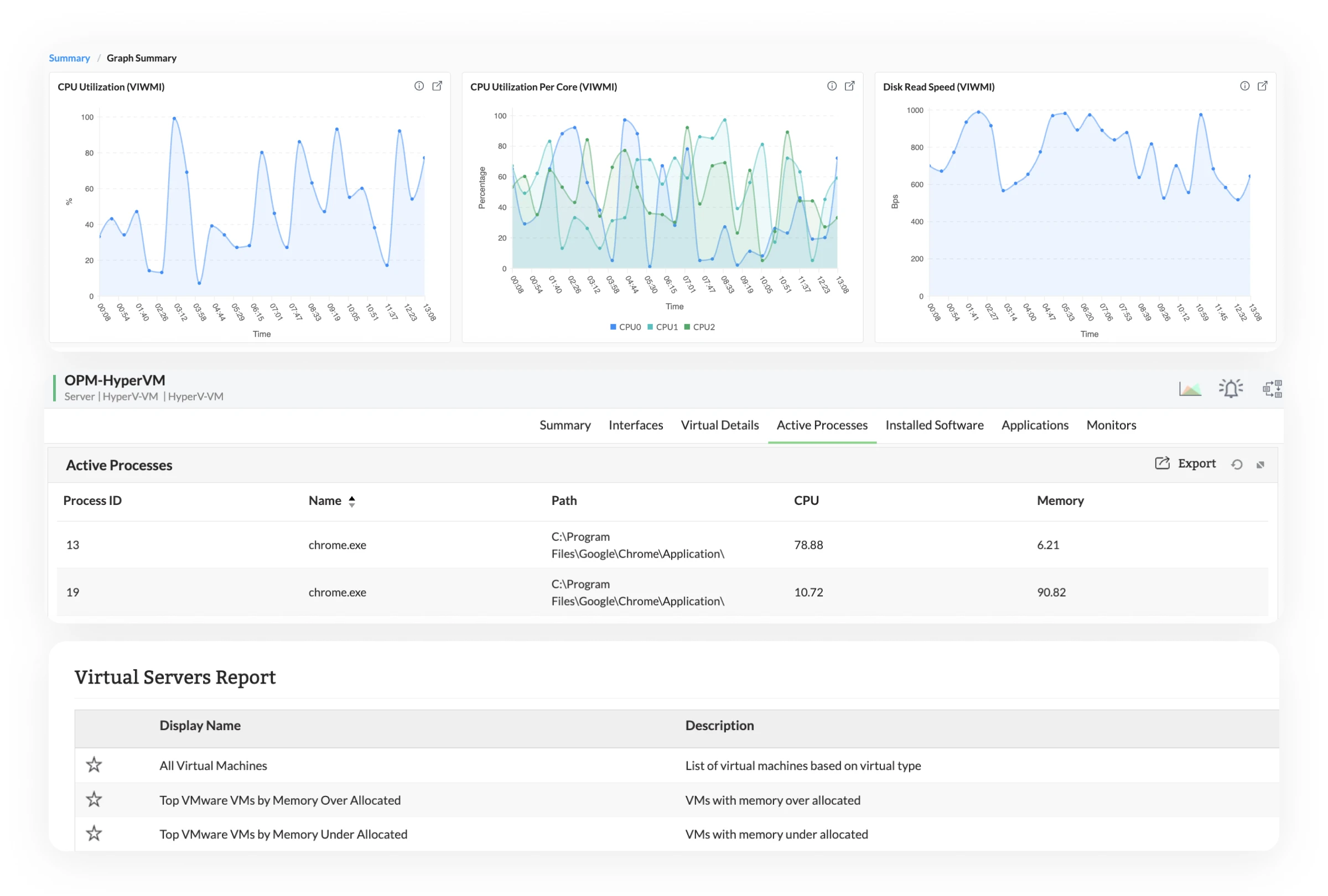
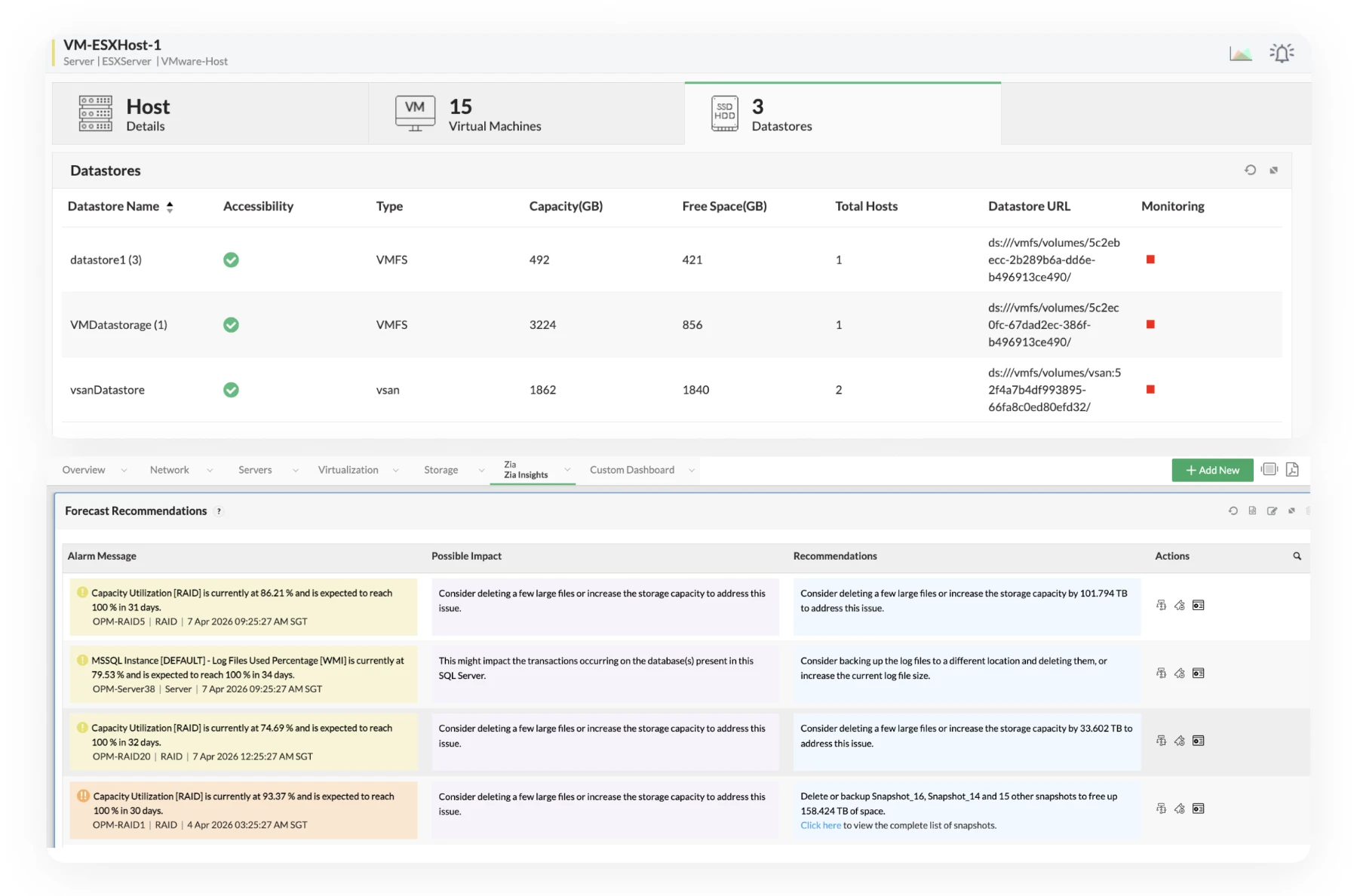
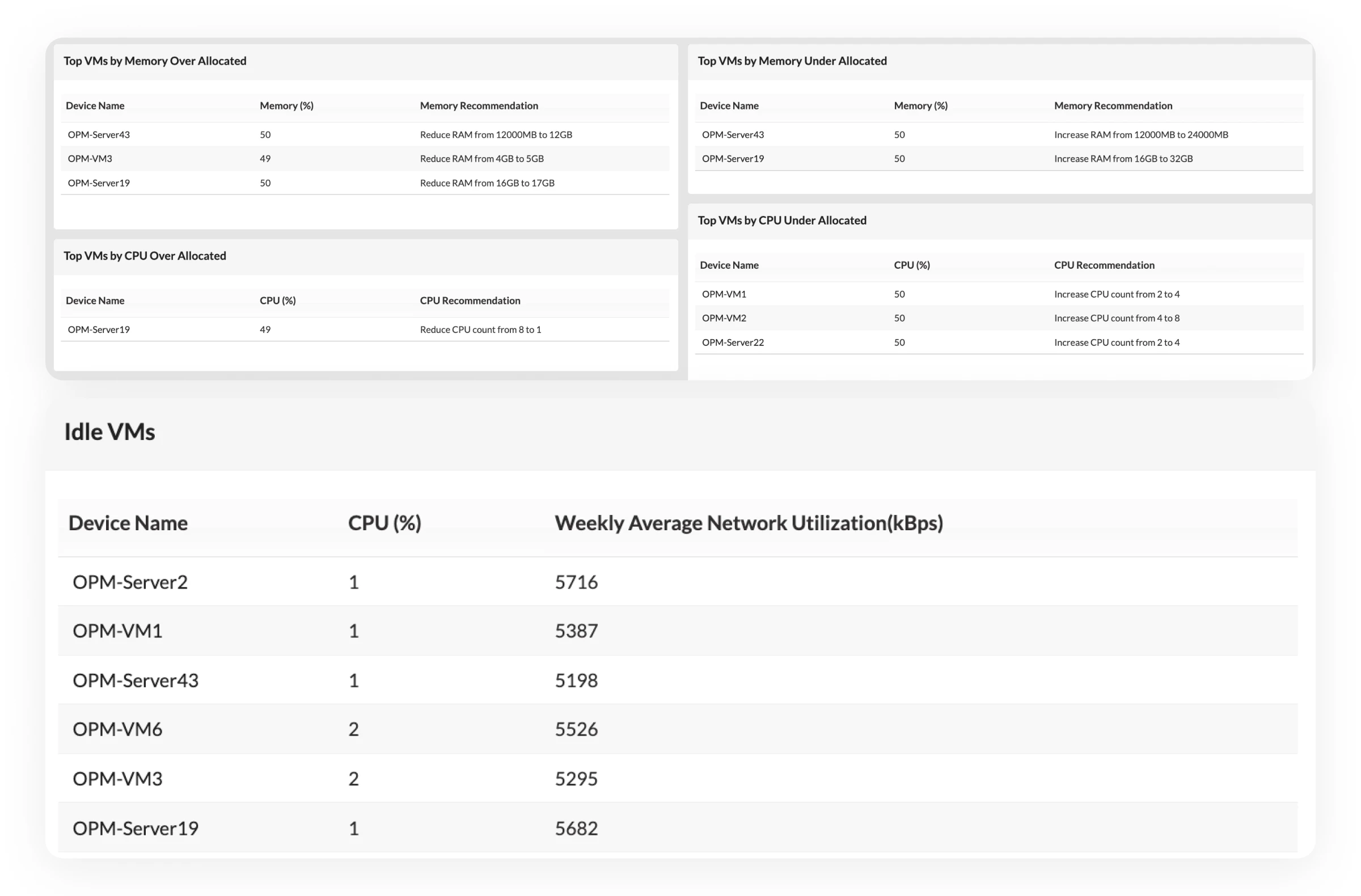
- Balance workloads using real utilization insights: Find overloaded hosts early and redistribute workloads before performance issues spread across multiple VMs in your VMware or Hyper-V setup.