- Preventie van gegevenslekken
- Risicobeoordeling van gegevens
- Bestandsanalyse
- Controle van bestand
Gegevens taggen
Wat is gegevens taggen?
Gegevens taggen is het proces waarbij een label wordt toegewezen aan een deel gegevens, zoals een afbeelding, website of video. De gekoppelde tags zijn vaak metagegevens die de naam van de auteur, de aanmaakdatum, de afdeling, de bestandsindeling of een ander definiërend detail aanduiden. Deze tags onderscheiden een gegevensset van andere gegevens binnen een omgeving, zodat ze gemakkelijk terug te vinden zijn.
Waarom is gegevens taggen belangrijk?
Gegevens taggen biedt een identiteit aan uw gegevens door ze te koppelen met metagegevens. In een organisatie dient een werknemers-id om de werknemers een unieke identiteit te geven. Op dezelfde manier geeft een stoelnummer bij een voetbalmatch de locatie aan waar u in een stadium zult zitten.
Een gemeenschappelijk kenmerk van deze scenario's is dat er een object wordt getagd met een label. Dit label geeft het object een unieke identiteit en biedt:
- Probleemloze identificatie
In het geval van de voetbalmatch geeft het stoelnummer een specifieke locatie in het stadium aan, waardoor u uw plaats niet hoeft te zoeken.
- Eenvoudig categoriseren
Afdelingsnamen categoriseren werknemers in herkenbare groepen.
- Gegevensbeveiliging
Een werknemers-id biedt informatie over de werknemer die kan worden gebruikt om toegang te verlenen en te beperken tot organisatorische bronnen zodat de gegevensbeveiliging wordt gegarandeerd.
Modellen gegevenstagging
"Data is the new oil" (gegevens zijn de nieuwe olie) is een zin die we het afgelopen decennium vaak hebben gehoord en die nog steeds waar is nu we zien dat organisaties grote sommen geld uitgeven aan het aanschaffen van gegevens. Met het volume gegevens dat door organisaties wordt opgeslagen, hebben ze een strategie nodig voor het efficiënt taggen en organiseren van gegevens. Hier zijn enkele modellen van gegevenstagging die door organisaties worden gevolgd:
- Hiërarchisch model
Orden tags in een hiërarchisch model met bredere categorieën bovenaan en specifieke tags onderaan. In een toepassing zoals Spotify, zullen muziek, podcasts en audioboeken bovenaan staan, terwijl subcategorieën voor elk onderwerp, zoals genres, zelfhulp en fictie op een lager niveau zullen staan.
- Plat model
In een plat model is elke tag even belangrijk en is er geen inherente relatie tussen tags.
- Segmentmodel
Dit model omvat het taggen van gegevens op basis van segmenten. SUV, sedan en hatchback kunnen bijvoorbeeld verschillende segmenten zijn in de showroom van een wagenverkoper.
- Jargon-model
Jargon dat herkenbaar is voor werknemers binnen een organisatie of afdeling, kan worden gebruikt voor tagging.
Verschillende types gegevenstagging
Gegevens taggen kan breed worden geclassificeerd in verschillende types op basis van de opmaak van de gegevens die worden getagd. Dit kan gaan tekst, beeld of video zijn. Daarnaast kan elk van deze opmaken verder worden geclassificeerd op basis van de functionaliteit. Enkele subclassificaties omvatten:
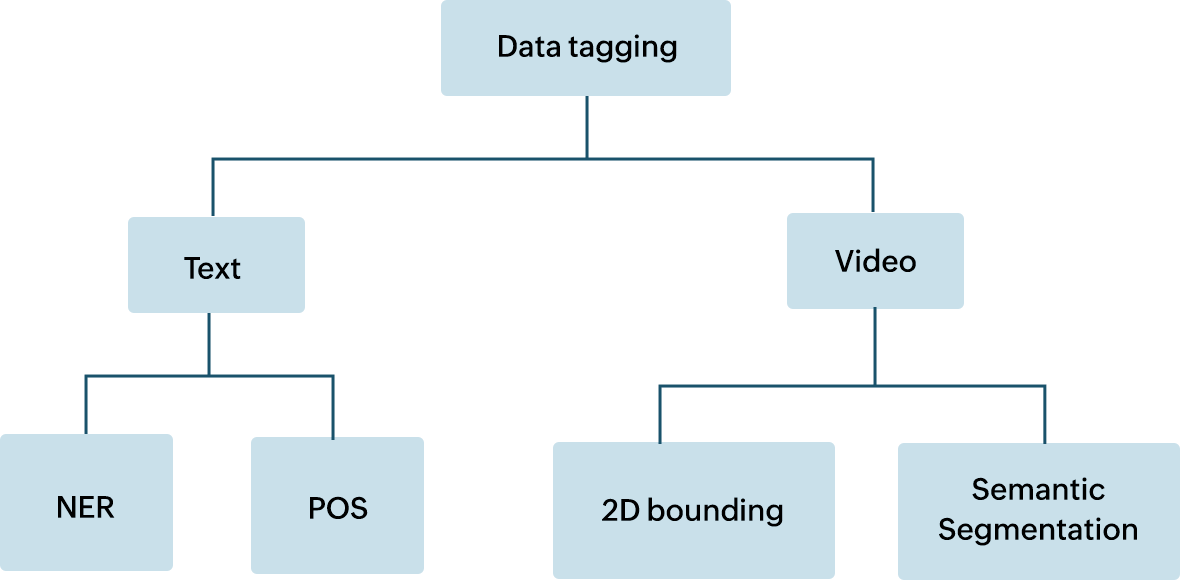
- NER (Named entity recognition = Herkenning van benoemde entiteiten)
NER helpt bij het identificeren van entiteiten, zoals namen, plaatsen en objecten in een tekstinhoud.
- POS-tagging (Part of speech = deel van spraak)
POS-tagging omvat het koppelen van woorden in een zin met een grammaticaal spraakgedeelte.
- Semantische segmentatie
Het proces van het taggen van elke individuele pixel die deel uitmaakt van een afbeelding.
- 2D-begrenzingsvak
Dit omvat het tekenen van een begrenzing rond het gewenste object om het herkenbaar te maken.
Beste praktijken voor gegevens taggen
Het primaire doel van gegevens taggen is om het leven van een eindgebruiker gemakkelijker te maken door de tijd die nodig is om de langdradige taak van het zoeken van gegevens uit te voeren, te verkorten. Het is daarom cruciaal voor uw strategie bij het taggen van gegevens om gebruiksvriendelijk te zijn. Hier zijn enkele van de beste praktijken die een naadloze ervaring kunnen mogelijk maken:
-
Beschikken over een goed gedefinieerde nomenclatuur
Als u organisatie- of afdelingsoverkoepelende naamgevingsconventies hebt, kunt u werknemers helpen bij het navigeren en ophalen van bestanden. Een goed gedefinieerde nomenclatuur moet herkenbaar zijn voor een eindgebruiker. Zorg er dus voor dat u trefwoorden gebruikt, zoals afdeling, project, beheerder, team en andere relevante id's. -
Een model bouwen
Een model voor gegevenstagging geeft structuur aan uw gegevens en draagt bij tot gegevensclassificatie. Er zijn enkele types waaruit u kunt kiezen die eerder op deze pagina werden besproken. -
Bruikbaarheidsevaluaties uitvoeren
Het periodiek uitvoeren van bruikbaarheidsevaluaties kan de efficiëntie van uw gegevenstagging verbeteren. Bruikbaarheidsrapporten moet rekening houden met factoren, zoals gemakkelijke toegankelijkheid en tijd die aan het ophalen van bestanden is besteed. -
Het gegevenstaggingsproces automatiseren
Het handmatig taggen van gegevens neemt een buitensporig aantal werkuren in beslag en is onderhevig aan menselijke fout. Het automatiseren van het proces van gegevens taggen via machine learning kan van onschatbare waarde blijken.
Gegevensclassificatie en tagging
Gegevenstagging en -classificatie worden vaak door elkaar gebruikt, maar er zijn twee zijden van dezelfde munt die elk een eigen betekenis hebben.
Gegevenstagging is het labelen van gegevens op basis van metagegevens, zoals projectnaam, bestandseigenaar of gegevenstype en heeft het doel de toegankelijkheid en organisatie te verbeteren. Anderzijds gebeurt gegevensclassificatie op basis van het vertrouwelijkheidsniveau van de inhoud van een bestand, met de bedoeling om vertrouwelijke gegevens te beveiligen en kan worden gebruikt voor het markeren van vertrouwelijke gegevens via de hulpprogramma’s voor preventie van gegevensverlies. Een evenwichtige gegevenstagging en classificatiestrategie kunnen zorgen voor een naadloze navigatie en netwerkbeveiliging.
Leer de essentie van gegevensclassificatie in ons on-demand webinar over gegevensclassificatie: De steunpilaar van DLP.
Detecteer en classificeer uw gegevens met DataSecurity Plus
DataSecurity Plus biedt een hulpprogramma voor gegevensdetectie dat het proces van de bestandsclassificatie automatiseert via een hiërarchisch labelingsysteem. Het hulpprogramma voor gegevensdetectie en classificatie detecteert, classificeert en beveiligt vertrouwelijke gegevens, zoals persoonlijk identificeerbare informatie, betaalkaartgegevens, informatie over de beschermde status en meer, wat zorgt voor de regelgevende naleving.
DataSecurity Plus is uitgerust met functies, zoals:
- Rapportage in realtime over het type, volume en locatie van vertrouwelijke gegevens.
- Aanpasbare gegevensdetectieregels voor het definiëren van organisatiespecifieke vertrouwelijke gegevens.
- Waarschuwt om bestanden te volgen die treffers bevatten voor wetten van gegevensbescherming, zoals de GDPR, de PCI DSS en meer.
- Incrementele gegevensdetectiescans om een inventaris te maken van uw meest vertrouwelijke gegevens.
Probeer de gegevensclassificatie van DataSecurity Plus met een gratis, volledig functionele proefperiode van 30 dagen.
Download een gratis proefversie voor 30 dagen