- PÁGINA INICIAL
- Análise de ITSM
- 3 maneiras pelas quais a análise unificada ajuda a reduzir o MTTR
3 maneiras pelas quais a análise unificada ajuda a reduzir o MTTR
- Última atualização: 1 de julho de 2024
- 668 visualizações
- 7 min de leitura

Para líderes de TI, uma organização que funciona como uma engrenagem bem ajustada é um sonho. Especialmente quando ela consegue identificar e resolver problemas de forma ágil, enquanto gerencia com eficiência o tempo e o orçamento. Além disso, mantém os usuários satisfeitos e felizes. Embora pareça bom demais para ser verdade, seguir algumas melhores práticas já nos permite chegar perto desse cenário ideal.
O primeiro passo é reduzir o tempo médio de resolução (MTTR), pois isso minimiza custos e aumenta a satisfação dos usuários. No entanto, quando os dados estão isolados em diferentes fontes e aplicações, é difícil identificar os fatores que aumentam o MTTR.
É aqui que entra a análise unificada: ela torna a redução do MTTR uma meta muito mais alcançável. Neste artigo, vamos explorar o conceito de análise unificada, como ela contribui para diminuir o MTTR e dar uma visão geral das ferramentas necessárias para simplificar processos, aumentar a eficiência das operações e alcançar níveis inéditos de satisfação do usuário final.
O que é o tempo médio de resolução (MTTR)?
MTTR é uma métrica que ajuda as equipes de TI a acompanhar o tempo necessário para resolver tickets. Para calcular o MTTR de uma organização, basta dividir o tempo total de resolução pelo número de tickets.
Como exemplo, vamos comparar as taxas semanais de resolução de tickets de duas organizações. Os técnicos de help desk da Organização A resolveram 100 tickets em 60 horas, resultando em um MTTR de 0, 6 hora (60 dividido por 100). Já na Organização B, o help desk resolveu 80 tickets no mesmo período de 60 horas, obtendo um MTTR de 1, 33 hora. Sem considerar outras variáveis, essa comparação já mostra que a Organização A foi mais eficiente que a B.
Como os processos variam bastante entre empresas, é difícil estabelecer um padrão universal de MTTR. O ideal é que cada organização busque reduzir continuamente seu índice, aprimorando a eficiência dos processos de resolução de incidentes e da equipe de help desk.
O que é análise unificada e como ela ajuda a reduzir o MTTR?
Ter todos os dados em um só lugar é ótimo, mas como usá-los de forma eficaz para encontrar respostas? A análise unificada resolve esse desafio.
Essa abordagem permite correlacionar dados isolados em diferentes fontes, aplicações e ferramentas de monitoramento. Ao consolidar essas informações em uma única plataforma, é possível tomar decisões melhores e melhorar as operações. A análise unificada é essencial para reduzir o MTTR porque integra múltiplos subdomínios de TI e correlaciona fontes de dados, em vez de analisar apenas o ambiente onde os problemas aparecem com mais frequência. Com isso, líderes e técnicos de TI conseguem informações contextuais sobre os incidentes e rastreiam a origem de falhas até pequenas alterações que, de outra forma, passariam despercebidas. "Ao integrar dados diversos e recursos de análise em uma única plataforma, a análise unificada capacita os líderes de TI a lidar com incidentes com rapidez e agilidade".
3 maneiras pelas quais a análise unificada ajudar a reduzir o MTTR
Aqui estão três maneiras pelas quais a análise unificada pode ajudar a reduzir o MTTR em sua organização:
1. Identificar a causa raiz dos problemas com mais rapidez
À medida que a tecnologia avança, seu papel dentro das organizações também cresce. Hoje em dia, as empresas dependem cada vez mais da tecnologia para suas operações. No entanto, a tecnologia nem sempre funciona de forma impecável. Mesmo pequenas configurações ou atualizações em componentes de hardware ou software podem causar lentidão ou indisponibilidade na rede, criando um pesadelo para as equipes de help desk. A chave para resolver esses problemas é identificar rapidamente a causa raiz. Por exemplo, a perda de pacotes de rede pode se transformar em latência de aplicações que impacta diretamente o usuário final.
Imagine essa situação: Seu help desk pode se deparar com um aumento repentino no volume de tickets, deixando os técnicos sem entender a causa do problema. Ao mesmo tempo, as ferramentas de monitoramento de rede geram registros de eventos e alarmes que aumentam ainda mais a pressão sobre a equipe. Para obter insights sobre o que está por trás desses tickets, é possível gerar uma nuvem de palavras com os assuntos dos tickets recebidos e identificar de imediato os problemas em comum que causaram o aumento no volume. Veja um exemplo de relatório com os com os campos "assunto" de tickets de help desk de uma organização fictícia.

Com o relatório de nuvem de palavras, foi possível identificar que o problema de Wi-Fi causou o aumento nos tickets. Isso economiza tempo dos técnicos e permite localizar rapidamente a causa raiz da indisponibilidade. Com essas informações em mãos, podemos analisar outro relatório que mostra o número de alarmes gerados ao longo do dia:
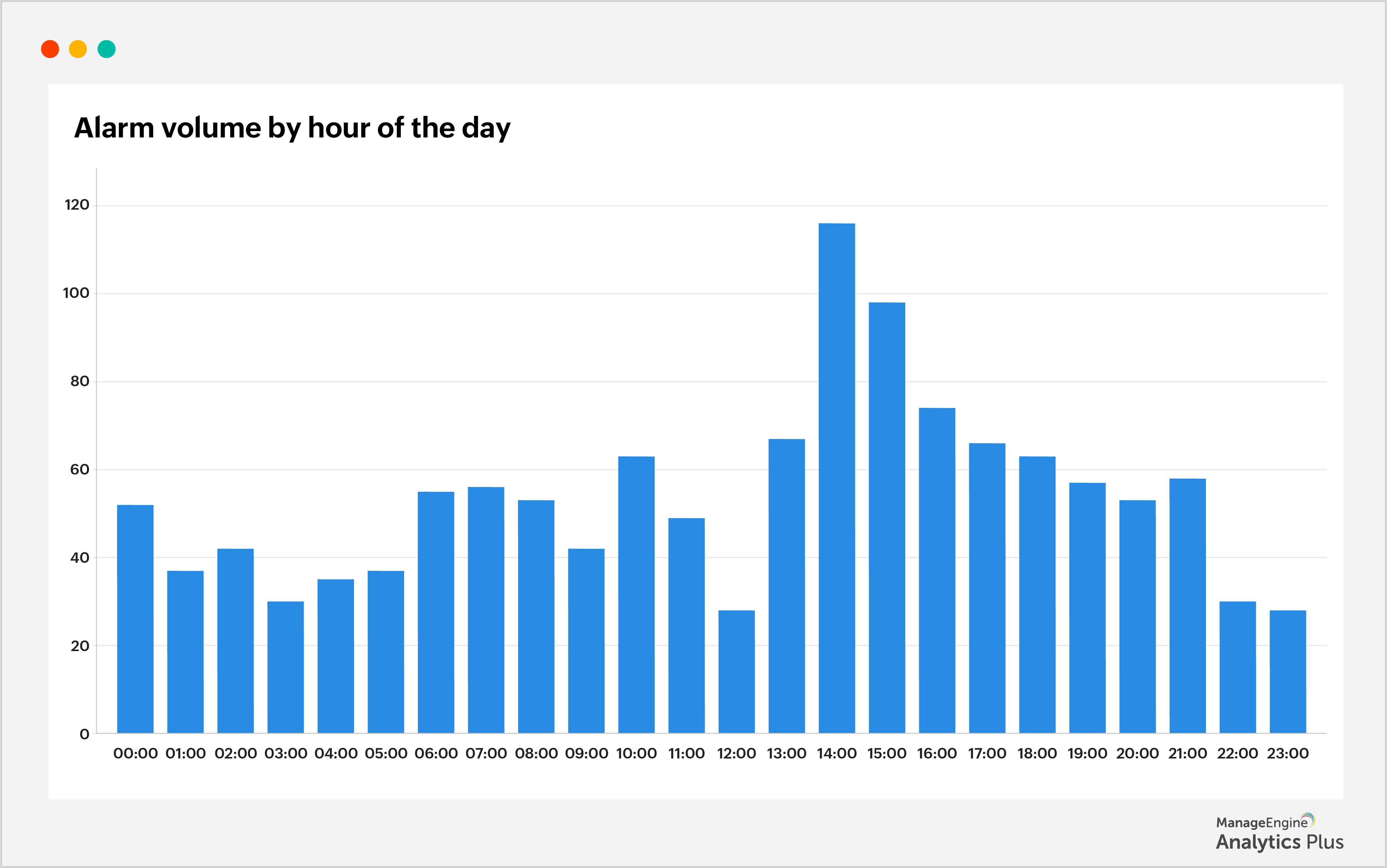
No relatório acima, o número de alarmes gerados durante a maior parte do dia está dentro do normal. Porém, há um pico de alarmes às 14h. Para identificar a causa desse pico, consolidamos dados das ferramentas de monitoramento de rede e dos logs dos pontos de acesso usando análise unificada, descobrindo o motivo dos alarmes e obtendo uma visão geral da infraestrutura de Wi-Fi. O resultado mostrou que uma queda em um ponto de acesso foi a causa raiz do problema. Relatório:
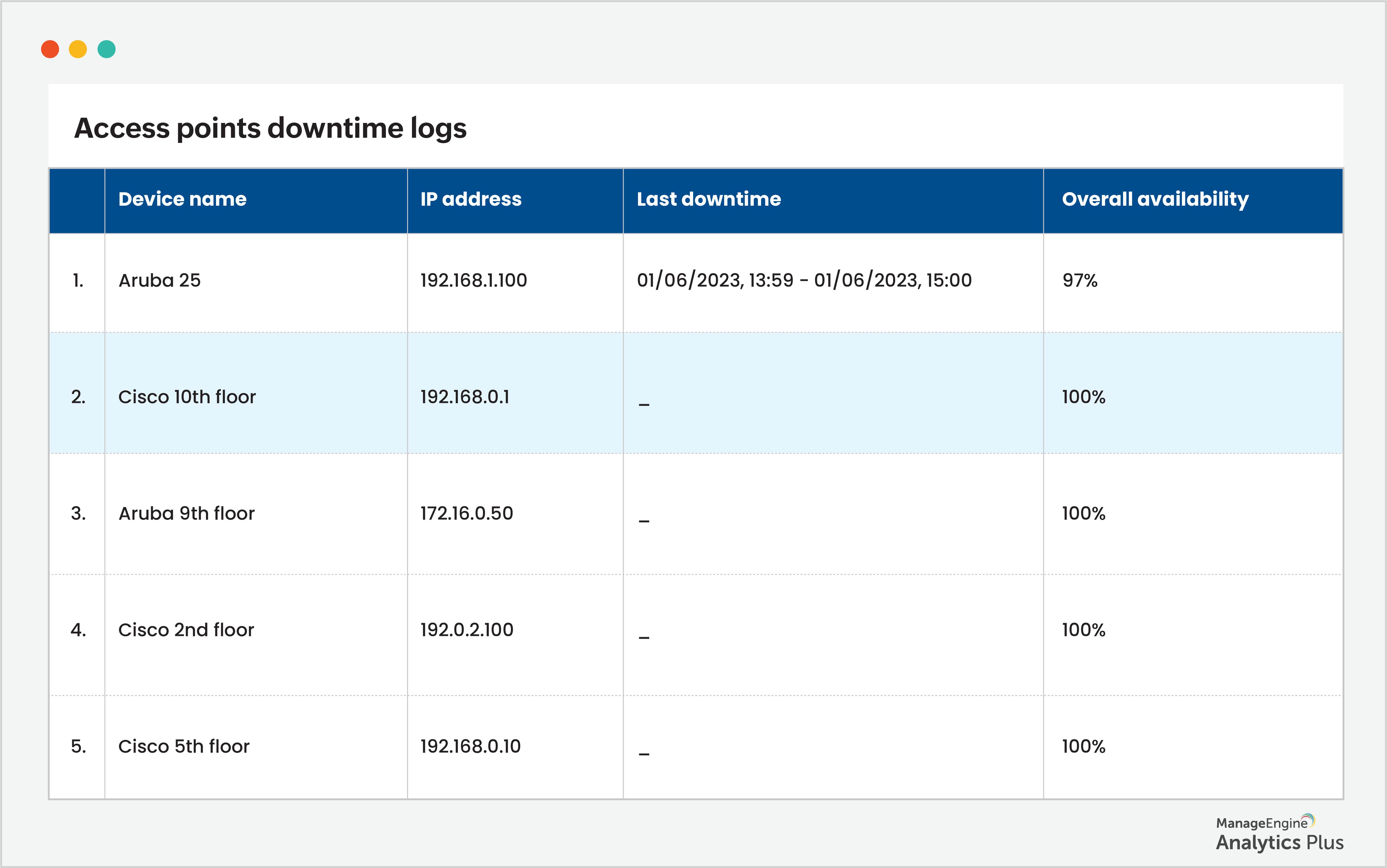
Ao identificar a causa raiz desses aumentos repentinos de tickets, você consegue resolver o problema de forma eficaz e reduzir a sobrecarga sobre o help desk. Ignorar essa análise faz com que os técnicos fiquem presos na solução de tickets relacionados à rede, enquanto outros incidentes críticos permanecem na fila e o MTTR dispara.
Dica: Também é possível se antecipar a esses picos de tickets aproveitando a análise unificada junto com eventos e logs de alarmes, que fornecem um histórico detalhado de incidentes de rede e seus respectivos timestamps.
2. Tenha visibilidade completa dos ativos da sua organização
Com o tempo, a falta de visibilidade dos ativos de uma organização impacta diretamente o MTTR. Quanto mais tempo leva para identificar um problema devido à falta de visibilidade, mais caro ele se torna para resolver. Por isso, ter uma visão de 360 graus de todos os ativos é fundamental para identificar problemas e garantir resoluções rápidas e eficazes. Melhores resoluções resultam em usuários satisfeitos e produtivos, além de maior disponibilidade operacional. Por outro lado, picos repentinos e significativos de trabalho comprometem essa visibilidade, atrasam a identificação e a resolução de problemas e levam a usuários insatisfeitos, queda de produtividade e redução no impacto da TI sobre os resultados do negócio.
Exemplo: Seu help desk recebe constantemente tickets relacionados a laptops. Apesar das tentativas repetidas de identificar e corrigir o problema, ele persiste. Isso pode ser causado por diversos fatores, como baixa duração da bateria, falha de hardware, idade do equipamento ou superaquecimento. Embora seja difícil apontar a causa exata, é provável que o envelhecimento do hardware seja o principal motivo. À medida que os ativos envelhecem, podem surgir falhas devido ao desgaste do hardware e incompatibilidade de software. Componentes como baterias, discos rígidos e ventoinhas podem se degradar com o tempo, causando queda de desempenho e falhas no sistema. O relatório a seguir mostra os tickets de laptops associados à idade do equipamento nos últimos 6 meses (considerando o tempo entre a data de compra do laptop e a data de abertura do ticket):
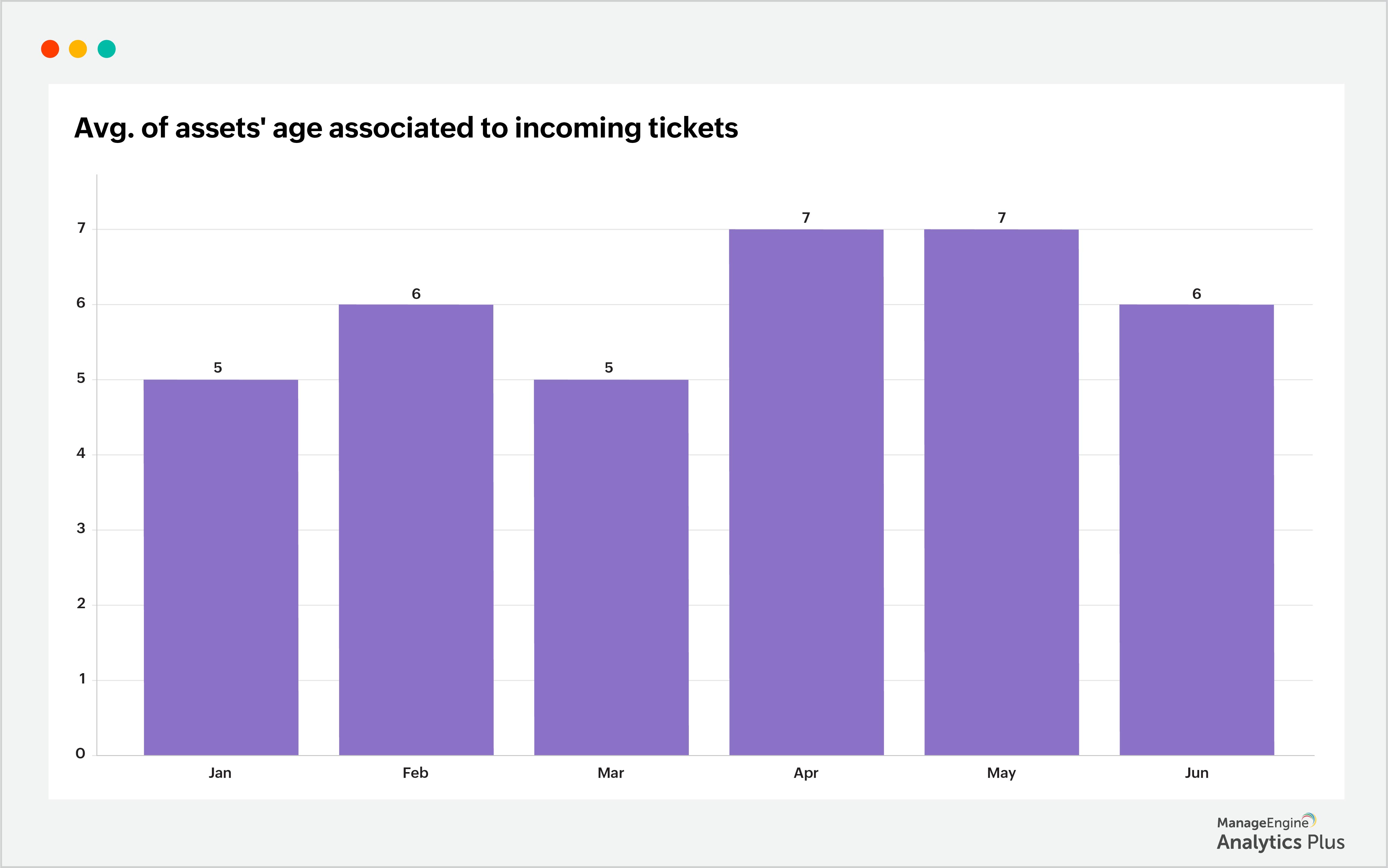
O relatório mostra que a idade média mensal dos laptops com problemas varia de 5 a 7 anos. Esse dado revela que o envelhecimento dos laptops contribuiu para o aumento de falhas e, consequentemente, para o maior volume de tickets. De forma semelhante, é possível aprofundar a análise verificando a idade média dos ativos em toda a organização. Confira um relatório de exemplo que apresenta a idade média dos ativos da organização:
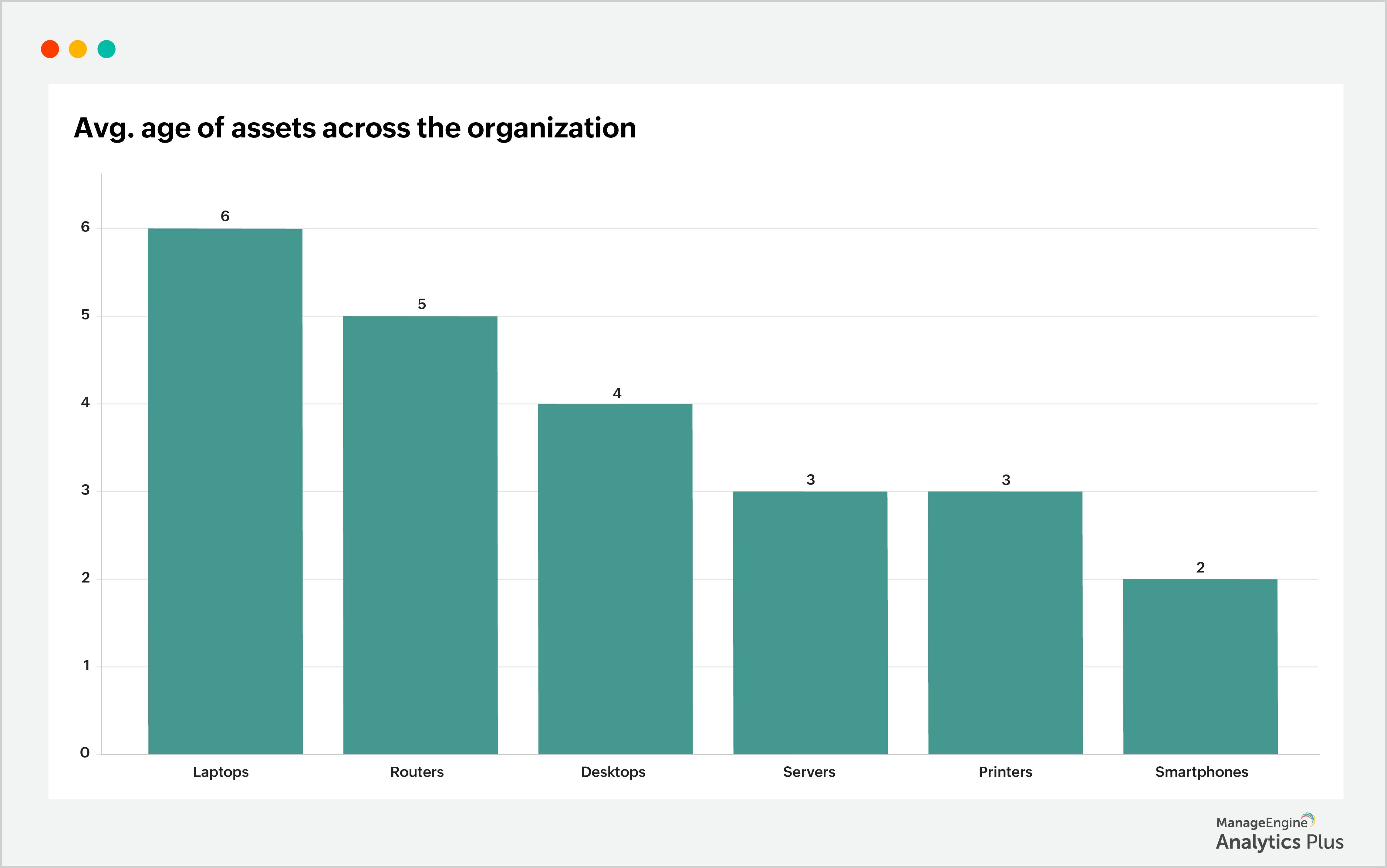
Enquanto servidores e desktops têm idade média entre 3 e 4 anos, laptops e roteadores tendem a apresentar idade média mais alta, entre 5 e 7 anos. Quanto mais antigos os ativos, maior sua vulnerabilidade a falhas. Por isso, é fundamental monitorá-los continuamente e considerar a substituição quando necessário, para manter uma infraestrutura de TI confiável e eficiente.
3. Acompanhe as mudanças na sua organização
O help desk de TI resolve diariamente uma quantidade considerável de tickets. No entanto, quando o volume de tickets aumenta repentinamente, os técnicos ficam sobrecarregados, sem entender a causa do problema e com tempo limitado para resolver todos os tickets e restabelecer as operações normais. Diversos fatores podem contribuir para esse aumento, e muitas vezes ele está relacionado a mudanças no ecossistema de TI. Exemplos incluem atualizações de sistema operacional, aplicação de patches, alterações de configuração, reparos de rede, indisponibilidade de aplicações ou a implementação de novas tecnologias. Todos esses fatores podem desencadear uma enxurrada de tickets. Nessas situações, a análise unificada oferece insights valiosos aos técnicos que buscam identificar a causa raiz do incidente que gerou o aumento. Ao integrar dados de aplicações de gerenciamento de mudanças e de service desk, a análise unificada possibilita identificar correlações entre mudanças específicas e os incidentes resultantes. Veja abaixo um exemplo de relatório:
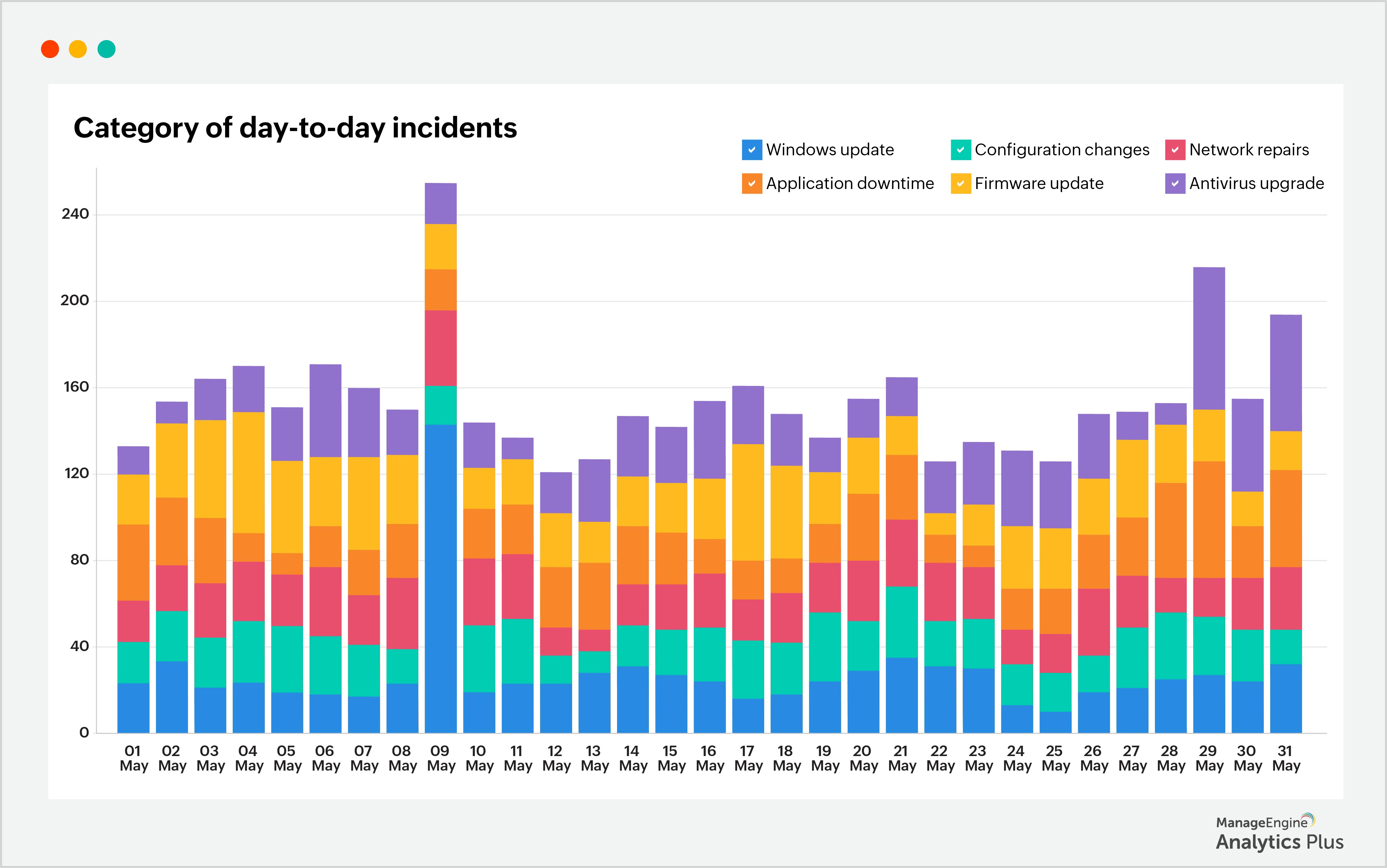
De acordo com o relatório, houve um aumento significativo de tickets em 9 de maio. Ao integrar esses dados com as informações da aplicação de gerenciamento de mudanças, foi possível determinar que a causa foi uma atualização do Windows realizada em 8 de maio. Outro relatório ilustrando essa relação é mostrado abaixo:
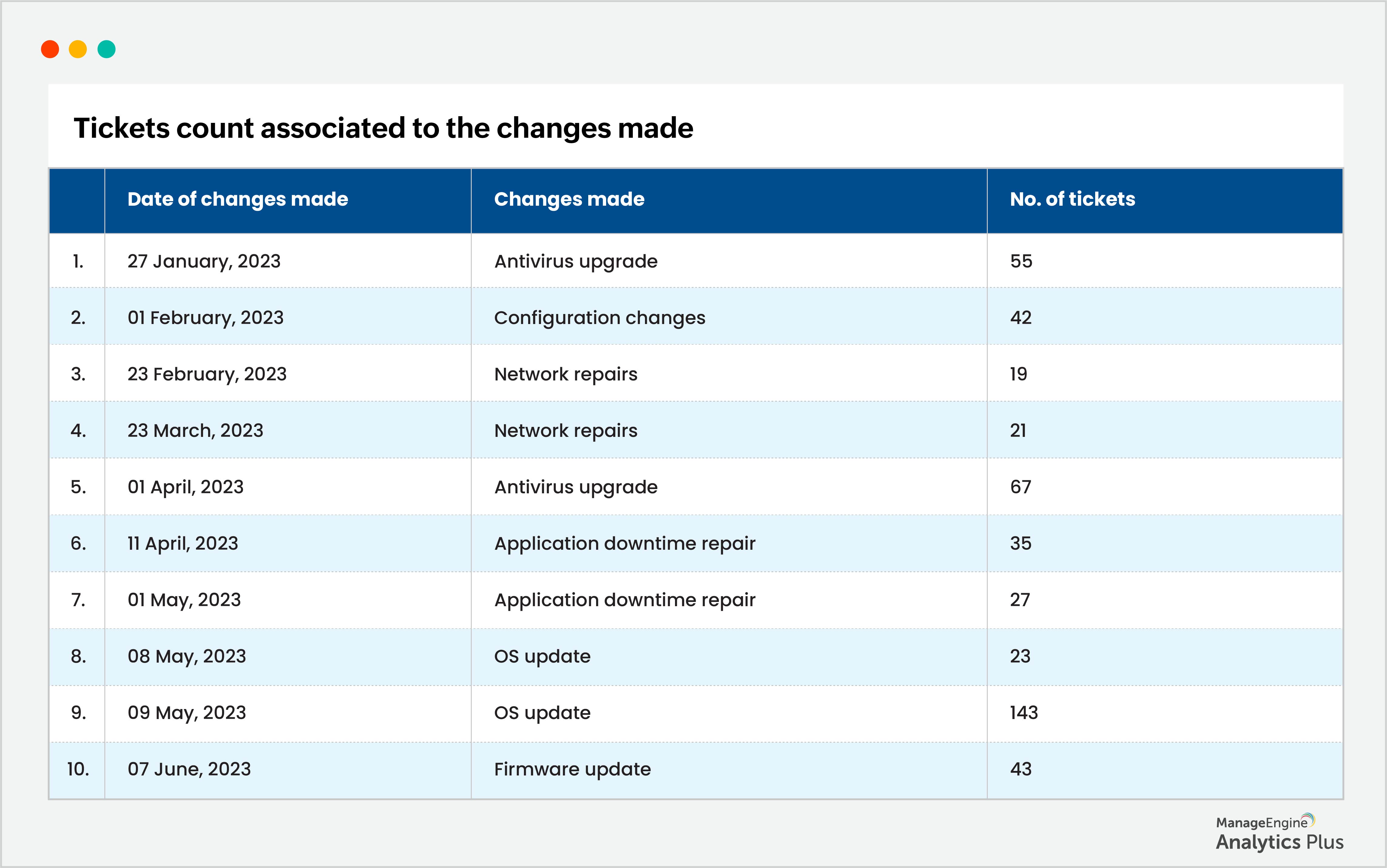
Embora a atualização de um sistema operacional ou patch normalmente não leve a um aumento repentino de incidentes, más práticas nesse processo podem causar esse efeito. Para mitigar riscos, é recomendável seguir as melhores práticas. Comece instalando o novo sistema operacional ou patch em sistemas internos, monitorando de perto seu desempenho e impacto. Depois de garantir sua estabilidade, aplique as atualizações aos demais sistemas. Com essa abordagem, você reduz significativamente a probabilidade de picos de incidentes e garante uma transição mais suave durante o processo de atualização.
Conclusão
A análise unificada pode desempenhar um papel essencial na redução do MTTR dentro de uma organização. Ao reunir múltiplos subdomínios de TI e integrar e correlacionar diferentes fontes de dados, ela vai além do escopo limitado de analisar apenas o ambiente onde os problemas são mais frequentes. Essa abordagem holística dá aos usuários acesso a informações contextuais sobre os incidentes e permite rastrear sua origem até mudanças sutis que normalmente passariam despercebidas. Esse nível de visibilidade revela insights essenciais que, de outra forma, permaneceriam ocultas, e permite processos de resolução de problemas mais rápidos e eficazes.
Esses relatórios foram criados com o Analytics Plus, a plataforma de análise de TI da ManageEngine. Experimente o Analytics Plus gratuitamente hoje mesmo..
Quer saber mais sobre análise nas operações de TI? Fale com nossos especialistas e descubra todas as maneiras de aproveitar os benefícios da análise em sua área de TI.


