4 principais métricas críticas de help desk e por que você precisa delas

Em TI, o que é medido é melhorado. Essa afirmação é especialmente válida para o service desk, que se sustenta sobre uma grande variedade de métricas. Porém, com tantos indicadores e KPIs passíveis de acompanhamento e pouco tempo para monitorá-los com eficiência, como definir quais merecem prioridade?
Este artigo apresenta quatro principais métricas críticas de help desk e explica por que elas são indispensáveis para qualquer operação de TI.
1. Burn rate
A gestão de incidentes é realmente completa sem monitorar o burn rate? Trata-se de uma das métricas mais relevantes em qualquer help desk: ele representa o percentual de incidentes encerrados em relação ao total de chamados recebidos. Esse indicador pode funcionar como um KPI central no processo de gestão de incidentes, oferecendo uma visão clara sobre a agilidade da equipe na resolução das demandas.
Afinal, qual é o objetivo central de um help desk de TI? Além de garantir a satisfação do usuário final e acompanhar violações de SLA, resolver incidentes rapidamente é a base de qualquer operação eficiente. Tratar as solicitações recebidas com rapidez e precisão é um sinal claro de uma equipe bem estruturada.
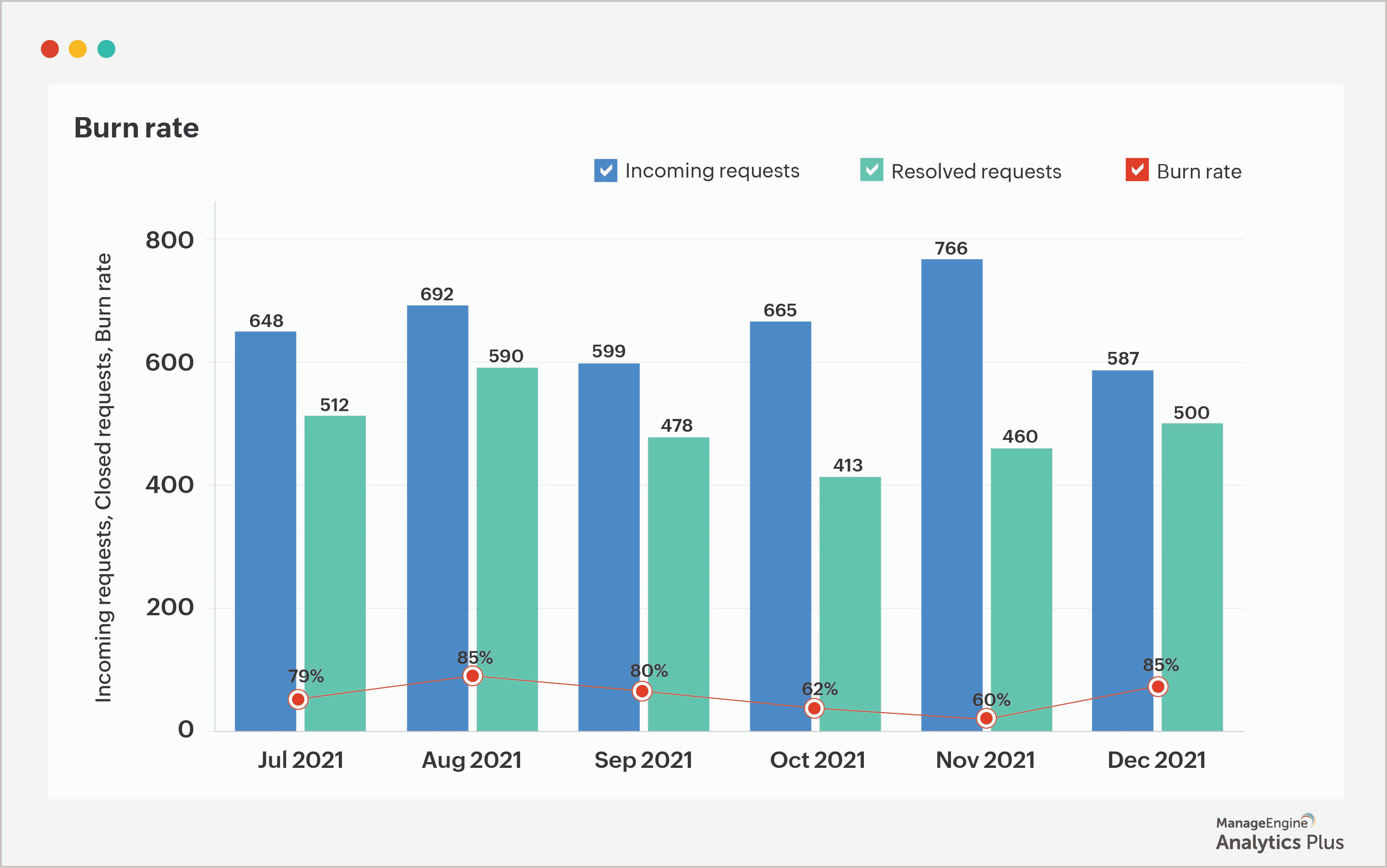
Vale detalhar o que essa métrica revela na prática. Um burn rate em torno de 50% indica que os técnicos resolveram apenas metade dos chamados abertos — situação que pode exigir a revisão dos processos existentes ou a contratação de novos profissionais para dividir a carga. Já uma taxa saudável, acima de 80%, demonstra que a equipe consegue resolver a maior parte das solicitações dentro do mesmo mês, sendo um bom sinal de desempenho.
Além de oferecer uma visão geral do desempenho do help desk, essa métrica também auxilia no planejamento de pessoal. Embora não existam parâmetros universais para definir o número ideal de colaboradores, um burn rate consistentemente baixo é um indicativo claro de que mais profissionais são necessários.
Reduzir o tempo de ociosidade dos tickets, estruturar fluxos de atribuição adequados e evitar a sobrecarga dos técnicos são ações que contribuem diretamente para a melhoria dessa taxa.
2. Carga de trabalho do técnico
O foco principal de um help desk é resolver todas as solicitações recebidas com precisão, e os técnicos são os protagonistas desse processo. Desempenho, resolução de incidentes e satisfação do cliente estão, portanto, diretamente interligados. Quando os técnicos enfrentam um volume excessivo e contínuo de tarefas, a produtividade cai e o tempo de resolução aumenta. Nesses casos, os gestores precisam analisar a distribuição da carga de trabalho para reatribuir chamados e, quando necessário, reforçar a equipe.
Para gerenciar essa distribuição de forma eficaz, é fundamental ter clareza sobre a carga individual de cada técnico. Isso pode ser obtido por meio do fator de carga do técnico, calculado dividindo o número de solicitações atribuídas ao profissional pelo tempo médio disponível para resolvê-las.
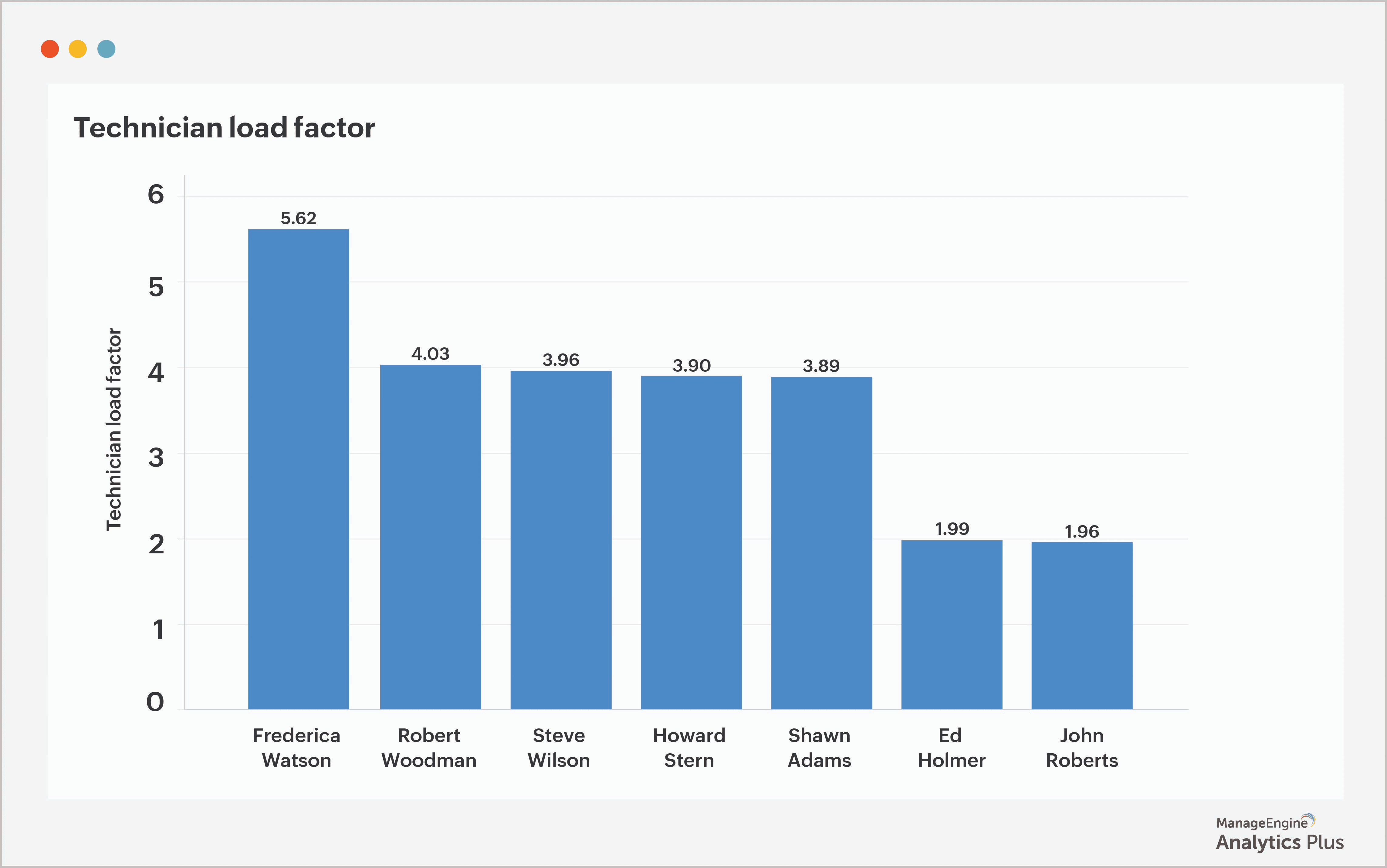
Com base nessa análise, é possível redistribuir chamados para equilibrar a carga, além de oferecer treinamentos direcionados e criar documentação detalhada para aprimorar as habilidades da equipe. Se, ainda assim, as melhorias de desempenho forem pouco expressivas, isso indica que novos técnicos precisam ser incorporados para dar conta da demanda crescente.
3. Tempo médio de resolução
Todo help desk de TI precisa de uma estratégia sólida de gestão de incidentes que considere e trate cada chamado que surgir. Essa prática é o alicerce de qualquer operação de suporte eficiente: lidar bem com as solicitações recebidas garante que os usuários finais obtenham as resoluções de que precisam dentro do prazo, evitando violações dispendiosas de SLA e perda de produtividade.
Entre as métricas acompanhadas nesse contexto, as taxas de resolução de solicitações são bastante comuns. No entanto, uma alternativa mais prática e igualmente eficaz é monitorar o tempo médio de resolução (MTTR, do inglês Mean Time to Resolve).
Definido como o tempo necessário para encerrar um incidente no help desk, o MTTR é um dos principais fatores que influenciam a satisfação do cliente. Seu cálculo é feito ao dividir o tempo total de resolução pelo número total de incidentes registrados.
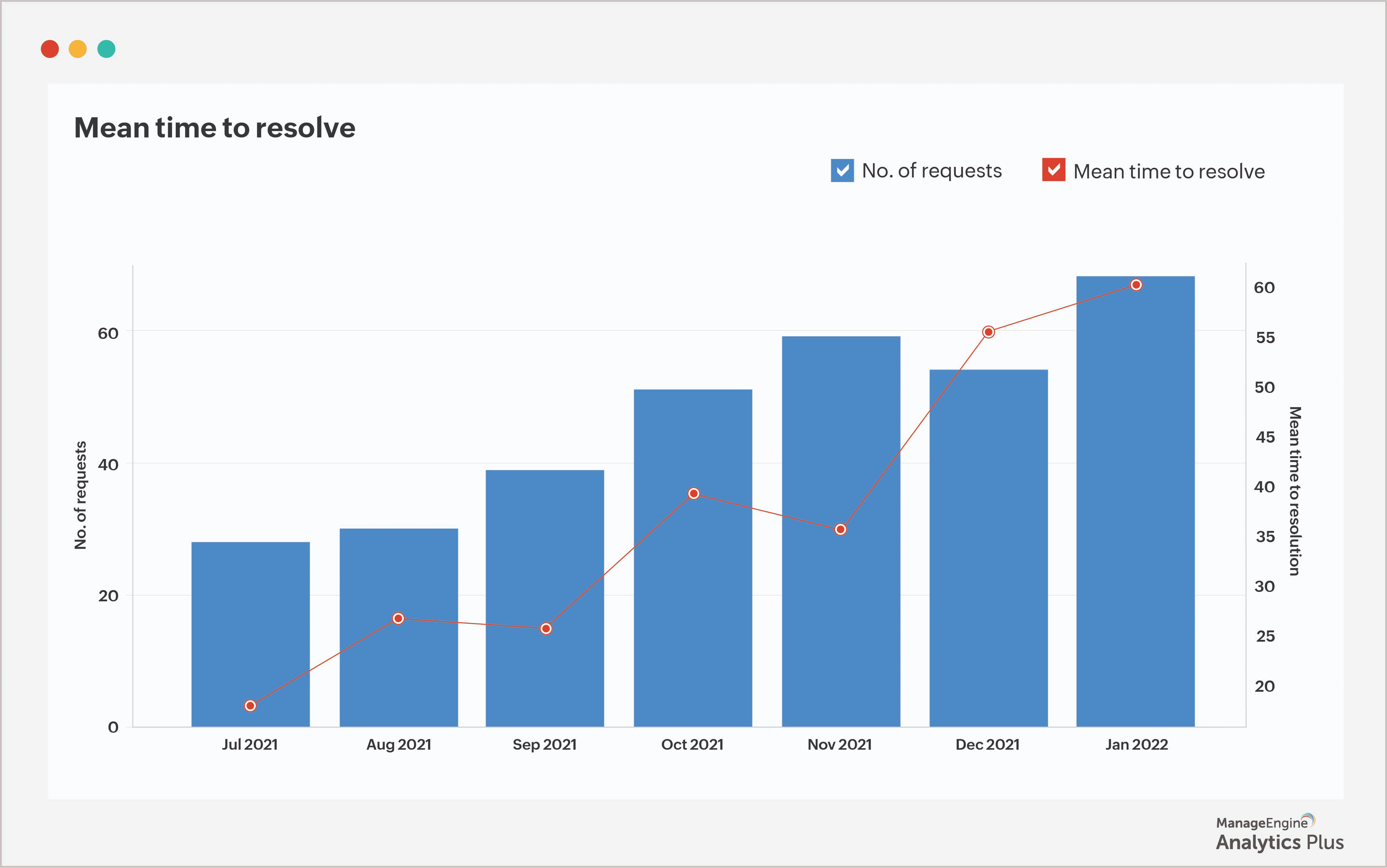
Algumas organizações conseguem manter um MTTR de apenas cinco horas, enquanto outras podem levar dez horas em média para atender suas demandas. Por isso, não é recomendável estabelecer benchmarks setoriais para esse indicador, já que a natureza dos incidentes, as tecnologias envolvidas e os ativos de cada negócio variam bastante.
O que se pode afirmar com segurança é que, quanto menor o MTTR, melhor. Uma taxa acima da média sinaliza que os processos de resolução precisam de ajustes para que os usuários recebam suporte em tempo hábil. Valores elevados podem impactar diretamente a satisfação do cliente, gerar downtime, causar interrupções significativas e até resultar em perda de clientes.
Incentivar resoluções no primeiro contato, coletar todas as informações necessárias já na abertura do chamado e categorizar e priorizar as solicitações com precisão são boas práticas para reduzir o tempo geral de resolução.
4. Tempo de resposta a incidentes críticos
Para ir além do MTTR e aprimorar ainda mais a gestão de incidentes, vale acompanhar também o tempo de resposta a incidentes críticos (CIRT, do inglês Critical Incident Response Time).
Enquanto o MTTR abrange o tempo de resolução de todas as solicitações, o CIRT foca especificamente nos incidentes que podem paralisar o negócio, oferecendo uma visão mais aprofundada sobre a eficiência dos processos e o desempenho do help desk nessas situações de maior impacto.
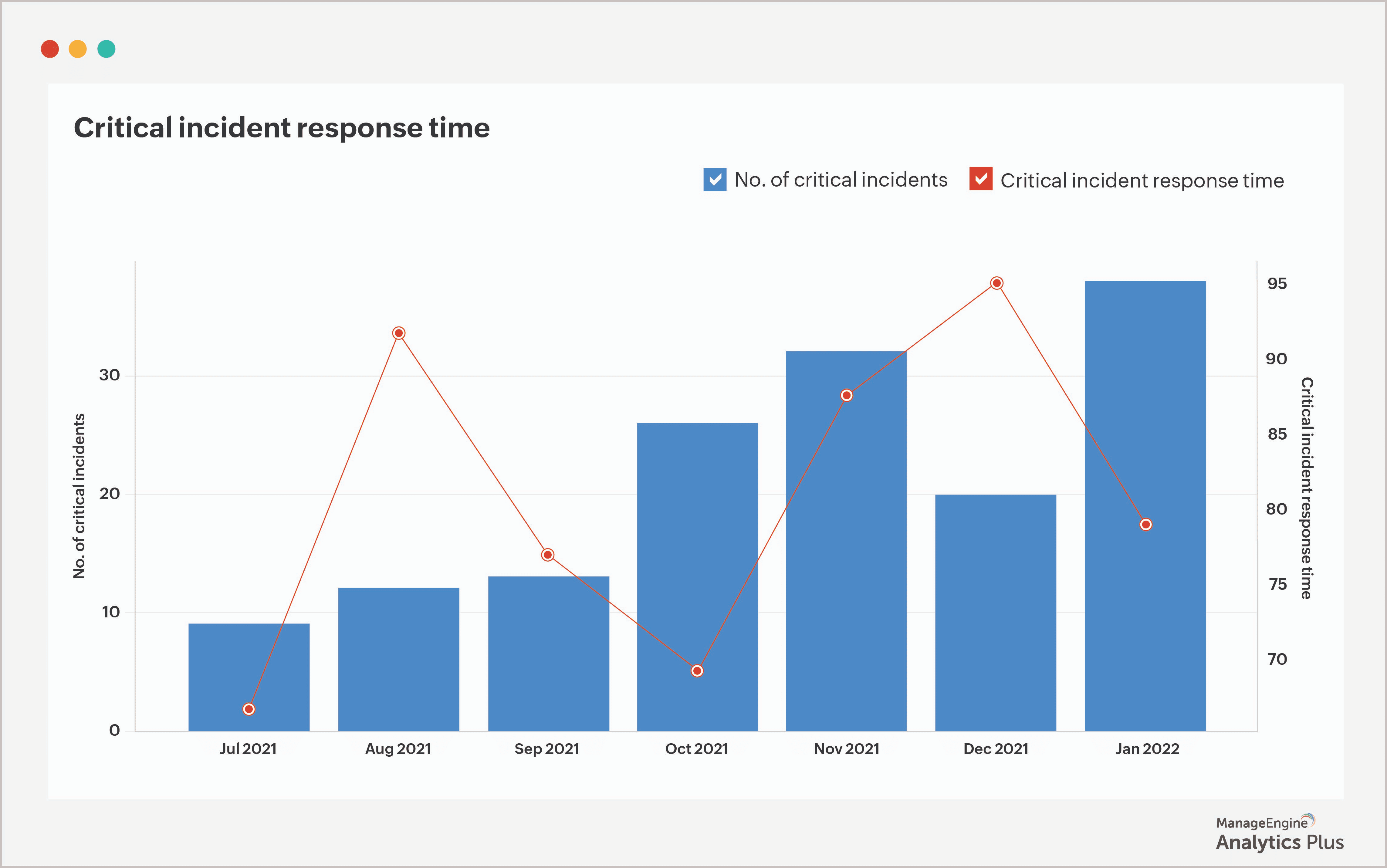
Responder com agilidade a esse tipo de ocorrência aproxima a organização de um ambiente mais estável, com menos interrupções e menor tempo de inatividade. Para acelerar essa resposta, algumas medidas podem ser adotadas: configurar alertas para incidentes de alto impacto, designar técnicos seniores para tratá-los e garantir que a identificação, categorização e priorização dos chamados sejam feitas com precisão.
Também é importante observar a diferença entre o CIRT e o MTTR. Uma variação muito acentuada entre os dois pode indicar que os técnicos estão concentrados demais nos incidentes críticos, deixando os demais chamados em segundo plano. Por fim, ao monitorar ambas as métricas, mantenha atenção às taxas de reabertura de solicitações, pois elas ajudam a verificar se a qualidade das resoluções não está sendo comprometida em favor da velocidade.
As imagens acima apresentam alguns dos relatórios disponíveis no Analytics Plus, a solução de análise de TI da ManageEngine. A ferramenta oferece integrações padronizadas com diversas aplicações populares, como ServiceNow, Jira Software, Zendesk e o portfólio de produtos da ManageEngine. Para criar relatórios semelhantes com seus próprios dados de TI, experimente o Analytics Plus gratuitamente.
Quer saber mais sobre análise para operações de TI? Fale com nossos especialistas e descubra como sua organização pode se beneficiar ao adotar essa abordagem.
Artigo traduzido. Conteúdo original escrito por Cherubina em Parte I e Parte II.
Nota: Encontre a revenda da ManageEngine certa. Entre em contato com a nossa equipe de canais pelo e-mail latam-sales@manageengine.com.
Importante: a ManageEngine não trabalha com distribuidores no Brasil.