Observabilidade de IA em tempos de agentes: qual é a importância
Nos primeiros anos após seu surgimento, a inteligência artificial era comumente associada apenas a chatbots e assistentes virtuais. Essas aplicações tinham um papel limitado: responder perguntas, gerar códigos, sugerir conteúdos ou automatizar interações mais simples.
Nos últimos dois anos, esse cenário mudou drasticamente.
A nova geração de IA é composta por agentes autônomos capazes de executar tarefas completas, tomar decisões e agir diretamente sobre sistemas corporativos. Agora, a IA não está mais limitada a sugerir ações, mas já é capaz de aprovar pagamentos, atualizar cadastros, modificar infraestruturas em cloud e coordenar processos sem precisar de intervenção humana direta.
Essa mudança marca a transição da IA assistiva para a IA operacional.
Neste artigo, vamos explicar como a IA está sendo implementada nas operações por meio de agentes, como isso funciona na prática e como a observabilidade garante o uso seguro na sua organização.
O que são os agentes de IA?
Com a inteligência artificial cada vez mais inserida nas organizações, a tecnologia não demorou a chegar aos agentes operacionais. Isso quer dizer que, impulsionados pela IA, esses agentes são capazes de tomar decisões sem a necessidade constante da fiscalização humana, promovendo a eficácia com que o sistema coleta informações e executa tarefas.
Em uma operação comum, os agentes seguem regras e fluxos pré-definidos, executando as ações programadas de maneira previsível, seguindo a lógica: "se o programa X der erro, execute Y comando".
Os agentes de IA utilizam LLMs (Large Language Models) para interpretar contexto e adaptar comportamentos de uma maneira mais dinâmica. Com isso, uma organização pode ter milhares de agentes executando tarefas diferentes em departamentos diferentes, como atendimento em vendas, catalogação em logística, troubleshooting em segurança, etc.
Essa automatização traz uma série de facilidades nos fluxos corporativos, mas também acende alguns alertas que devemos levar em consideração. Um deles é a dificuldade de compreender como exatamente os agentes de IA tomam algumas de suas decisões.
Mesmo quando o resultado parece ser o correto, muitas organizações não conseguem dizer o porquê o agente agiu de tal forma, quais dados influenciaram a decisão, se as informações utilizadas estão atualizadas e se ele ignorou alguma política da empresa.
Conhecido como o problema da caixa-preta, esse fenômeno é um dos maiores obstáculos da IA moderna, o que a torna um sistema difícil de auditar e governar.
Então, como é possível supervisionar milhares de agentes atuando autonomamente? Continue lendo este artigo para entender.
Observabilidade tradicional x Observabilidade de IA: qual é a diferença?
Antes de explorar a observabilidade de IA, vamos entender primeiro o que é o conceito de observabilidade e como ela está integrada no ambiente de trabalho.
A observabilidade nada mais é do que a capacidade de compreender o estado e o comportamento interno de um sistema com base nos dados de telemetria coletados. Isso significa que você consegue saber o que está acontecendo dentro de uma aplicação a partir dos dados que ela gera, sem a necessidade de entrar no código toda vez que há um evento.
Diferentemente do monitoramento — que tem como principal objetivo detectar falhas, anomalias e degradações de desempenho antes que essas afetem os usuários e se torne irreversíveis — a observabilidade é um passo adiante. Além de também identificar que um problema ocorreu, ela também investiga a causa raiz desses problemas nos ambientes de TI por meio da análise dos dados gerados pelos sistemas, contribuindo para evitar recorrências e aprimorar continuamente a operação.
Observabilidade de IA na prática
A observabilidade aplicada à IA nada mais é do que a consequência do aumento da presença de agentes, e de ferramentas, impulsionadas pela inteligência artificial e as mudanças que elas trazem para o ambiente de trabalho. Devido a essa presença, surge a necessidade de entender como o ecossistema agêntico funciona e como ele está se comportando, afim de prever erros antes que eles se tornem irreversíveis.
Por exemplo, um agente autônomo pode ficar horas cometendo erros silenciosos antes de ser detectado, e, em muitos casos, a infraestrutura continua sem acusar falha alguma enquanto os clientes sentem o impacto.
Isso acontece pois, diferentemente de softwares tradicionais — onde uma falha pode gerar lentidão, mensagens de erro ou sintomas técnicos mais claros — os agentes de IA não falham de uma maneira "óbvia"; o erro pode ocorrer na camada de interpretação e tomada de decisão.
Com isso, o sistema continua operando normalmente, respondendo rapidamente, executando ações que podem parecer válidas, concluindo tarefas sem apresentar qualquer falha técnica visível, mas ainda assim produzir resultados incorretos.
Esse fenômeno é conhecido como alucinação, e ocorre porque os modelos de IA generativa trabalham de forma probabilistica. Eles não sabem de algo da mesma maneira que um banco de dados retém uma informação estruturada, mas calculam a probabilidade de cada resposta com base nos padrões aprendidos durante o treinamento de implementação.
A consequência disso são as respostas extremamente convincentes que os agentes geram, mesmo estando incorretas. E é exatamente essa lacuna que a observabilidade de IA irá preencher.
Pilares da observabilidade aplicados à IA
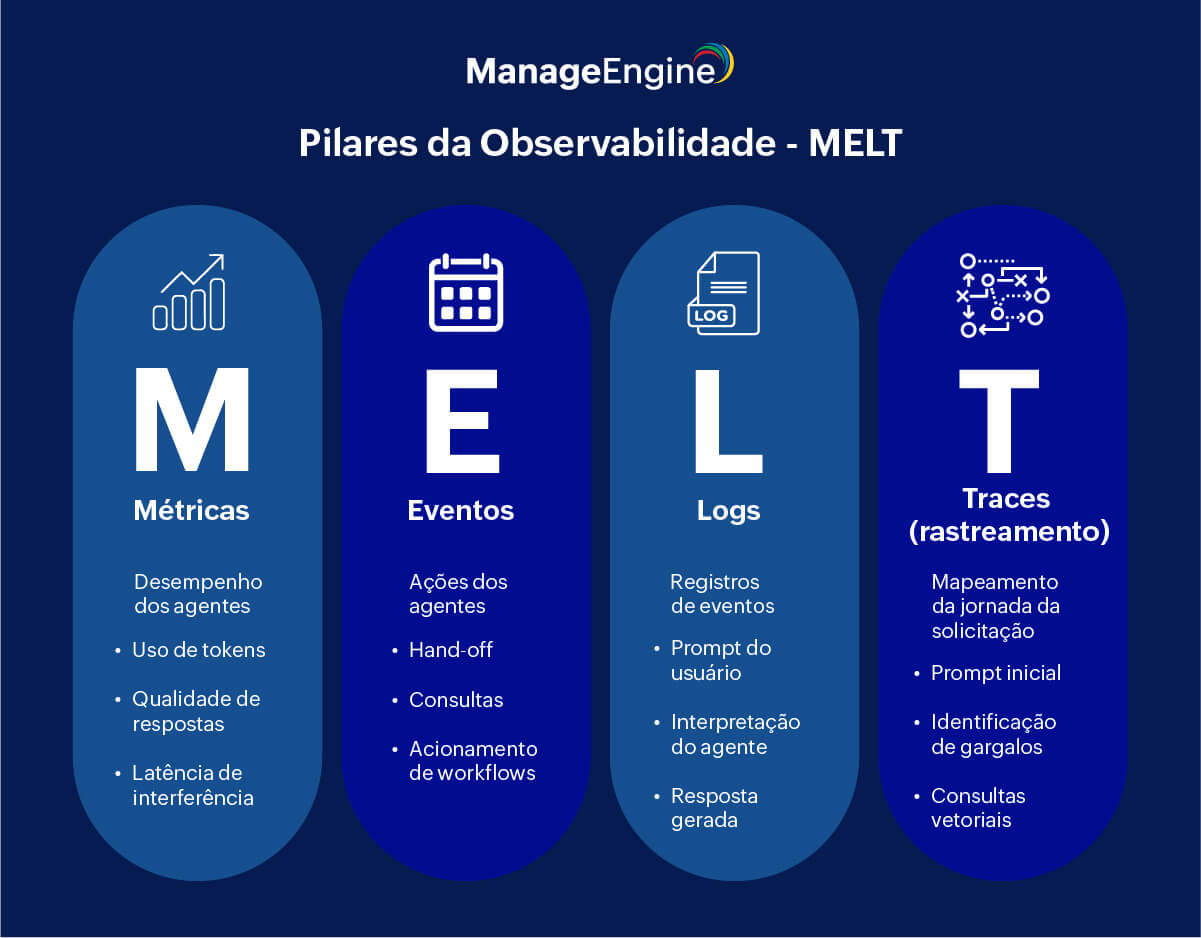
Com a ascensão da IA Generativa e dos sistemas baseados em LLMs, os pilares clássicos conhecidos como MELT: Métricas, Eventos, Logs e Traces (Rastreamentos), ganharam novas camadas de complexidade fundamentais para garantir a eficiência operacional, a segurança e a viabilidade financeira das aplicações.
Métricas
As métricas servem para avaliar a integridade e o desempenho das aplicações e sistemas ao longo de sua vida útil. Em um ambiente digital tradicional, esses parâmetros irão medir a performance de uma aplicação em um pico de uso, ou quanta memória da CPU ela utiliza em um determinado tempo.
No contexto da IA, as métricas priorizam o monitoramento do uso de tokens, que representam o custo operacional direto da aplicação. Para manter a saúde financeira, é preciso rastrear o consumo por usuário, por agente e por fluxo, além de calcular o custo por tarefa e identificar onde há desperdício.
Além do aspecto financeiro, as métricas irão avaliar a qualidade da resposta, ajudando a detectar alucinações, inconsistências, perda de contexto, respostas tóxicas ou de baixa precisão; e também a latência de interferência, pois um tempo de resposta elevado impacta negativamente a experiência do usuário, a produtividade e as taxas de conversão.
Eventos
Os eventos são ações discretas e cruciais executadas pelo sistema, como chamadas de API, execução de ferramentas, consultas em bancos de dados, mudanças de contexto e o acionamento de workflows.
Entre todos os eventos, o hand-off — a transferência para o atendimento humano — tem uma grande relevância, pois serve como um indicador de baixa confiança no agente de IA, ambiguidade na solicitação ou falha operacional.
Logs
Os logs são os registros e o armazenamento de eventos que ocorrem no ambiente digital. Esses eventos podem ser desde registros de inicialização de um desktop até mensagens de erro de alguma aplicação instalada no sistema.
Na IA Generativa, dois deles estão à frente:
Logs de interação: documentam o prompt do usuário, a interpretação do agente, o contexto e a resposta gerada.
Logs de tomada de decisão: mostram o raciocínio por trás das ações do agente, explicando por que determinada ferramenta foi escolhida e quais critérios guiaram o fluxo.
É a partir da análise dos logs que as equipes de TI conseguem entender a cadeia de eventos que leva a uma possível falha, o que também se torna essencial para as auditorias de segurança.
Traces (rastreamentos)
O rastreamento coleta os dados registrados pelos logs e métricas e segue a jornada completa de uma solicitação, ou uma transação, através dos vários componentes do sistema. O objetivo é identificar os pontos de entrada e saída de todas as operações, do inicio ao fim.
Em um sistema agêntico, o rastreamento irá mapear desde o prompt inicial, passando pela recuperação de contexto, consultas vetoriais e chamadas de APIs, até as decisões intermediárias e a execução final.
Objetivos
A observabilidade de IA também possui objetivos estratégicos como: redução de riscos, eficiência operacional e fortalecimento da governança e da confiança da organização nos agentes de IA. Quando implementada de forma eficaz, a observabilidade de IA permite identificar, prever e mitigar problemas como: o aumento de alucinações; a degradação do desempenho; as falhas nas integrações; o comportamento fora da política ou o uso indevido de ferramentas.
Isso evita que a equipe de TI seja a última a saber que há uma irregularidade no ambiente digital, o que gera um aumento na eficácia operacional e na confiança da organização nos seus agentes de IA.
Contudo, essa confiança não depende apenas da redução das possíveis falhas que os agentes de IA podem apresentar, mas também da capacidade de auditoria e de rastreabilidade das decisões e ações tomadas por eles.
As organizações devem estar cientes de quem tomou determinada decisão, de qual modelo foi utilizado, do prompt que originou a ação, das ferramentas que foram acionadas e das políticas que estavam ativas naquele momento.
Já a eficácia operacional é atingida quando parâmetros técnicos são associados aos indicadores-chave de desempenho do negócio.
Por exemplo, o aumento da latência impacta a conversão; o crescimento no consumo de tokens eleva os custos; a baixa precisão reduz a satisfação do cliente; e as falhas em agentes afetam a receita.
A observabilidade é, portanto, um componente central de governança de IA, de conformidade regulatória e de estratégia, pois é essencial para garantir a integridade, a transparência e a confiabilidade dos sistemas de inteligência artificial, garantindo o sucesso de qualquer empreendimento.
Por que é fundamental acompanhar os agentes de IA em operação?
Como mencionamos anteriormente neste artigo, os agentes autônomos estão o tempo todo executando funções críticas, como: aprovar transações, alterar configurações, mover recursos financeiros, interagir com clientes, provisionar as infraestruturas da organização e executar comandos administrativos.
Em arquiteturas multiagentes, diferentes agentes de IA assumem responsabilidades específicas e colaboram para executar tarefas complexas, o que pode gerar comportamentos difíceis de prever. Com os agentes constantemente interagindo entre si, uma falha aparentemente isolada em um deles pode gerar um efeito dominó com graves consequências através das operações. E isso pode acontecer mesmo quando a lógica individual de cada agente parece estar correta, já que o problema pode surgir das interações, dependências e decisões tomadas ao longo do fluxo de execução.
Em algumas situações, essas falhas também podem estar relacionadas à degradação do desempenho dos modelos utilizados pelos agentes. Esse fenômeno, conhecido como model drift, ocorre quando mudanças nos dados, no contexto de uso ou no ambiente operacional fazem com que o modelo passe a produzir resultados menos precisos ao longo do tempo.
Exemplos comuns incluem mudanças no comportamento de consumidores, novas táticas de fraude, alterações regulatórias, novos padrões linguísticos e mudanças econômicas.
Sem a observabilidade contínua dos agentes de IA, esses detalhes podem passar despercebidos até gerar prejuízos significativos para a organização.
O OpManager Nexus como plataforma de observabilidade para ambientes de IA
O OpManager Nexus da ManageEngine oferece uma abordagem integrada de observabilidade full-stack, fornecendo visibilidade abrangente sobre ambientes híbridos e distribuídos. Com seus recursos de monitoramento e correlação de dados, a plataforma ajuda as organizações a acompanhar aplicações modernas e os componentes que sustentam iniciativas baseadas em inteligência artificial.
No dia a dia, o OpManager Nexus pode monitorar sua operação de ponta a ponta e fazer uma correlação direta entre todos os componentes MELT, proporcionando uma visualização unificada da infraestrutura, trazendo alertas inteligentes e uma análise detalhada do desempenho das aplicações.
Saiba como implementar uma observabilidade de IA na sua organização ao fazer um teste gratuito de 30 dias!
Nota: Encontre a revenda da ManageEngine certa. Entre em contato com a nossa equipe de canais pelo e-mail latam-sales@manageengine.com.
Importante: a ManageEngine não trabalha com distribuidores no Brasil.