Comment calculer le MTBF : guide complet pour mesurer la fiabilité IT

Saviez-vous qu’une panne informatique coûte en moyenne 200 millions de dollars par an aux grandes entreprises ? Selon une étude d’Oxford Economics relayée par Le Monde Informatique en 2024, c’est 9 % de leurs profits annuels qui s’envolent à chaque interruption. Productivité en berne, chiffre d’affaires amputé, image de marque écornée… Face à ces risques, il ne suffit plus de réagir. Il faut anticiper. Et pour anticiper, encore faut-il mesurer. C’est là qu’intervient le MTBF (Mean Time Between Failures). Encore faut-il comprendre comment calculer le MTBF pour en tirer toute la valeur.
Qu’est-ce que le MTBF et pourquoi est-il essentiel ?
Le MTBF (Mean Time Between Failures), ou temps moyen entre deux pannes, est un indicateur clé permettant d’évaluer la fiabilité d’un équipement ou d’un système informatique. Concrètement, il mesure le temps moyen de fonctionnement d’un composant entre deux interruptions. Plus le MTBF est élevé, plus le système est considéré comme fiable. Pour un DSI, c’est l’un des premiers indicateurs à surveiller lorsqu’on parle de stabilité opérationnelle.
Cet indicateur s’applique à de nombreux environnements IT : serveurs, routeurs, switches, applications ou encore infrastructures réseau complètes. Dans une démarche ITOM, le MTBF joue un rôle essentiel. Il permet d’anticiper les pannes, d’améliorer la disponibilité des services et d’orienter les décisions en matière de maintenance et d’investissement.
Maintenant que nous savons ce qu’est le MTBF, voyons comment calculer le MTBF concrètement.
Comment calculer le MTBF : définition, formule et importance pour la fiabilité IT
La formule est simple :
Formule du MTBF :
MTBF = Temps total de fonctionnement / Nombre de pannes
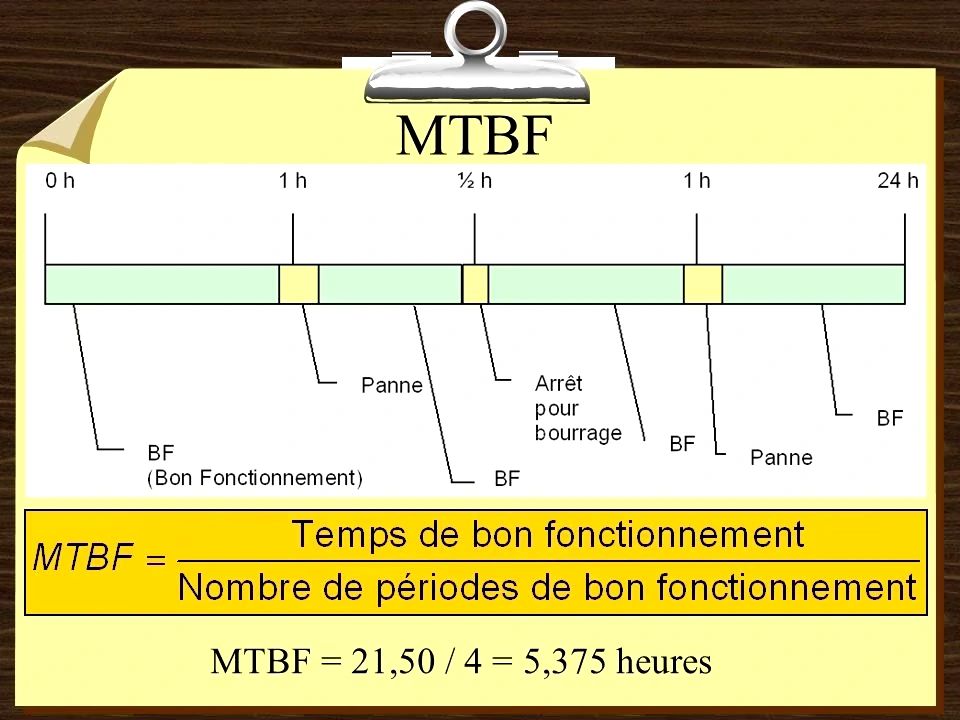
Le temps total de fonctionnement correspond à la durée pendant laquelle le système est opérationnel, tandis que le nombre de pannes représente les interruptions non Le temps total de fonctionnement correspond à la durée pendant laquelle le système est opérationnel, tandis que le nombre de pannes représente les interruptions non planifiées observées sur cette période.
Prenons un exemple concret : un système fonctionne pendant 21,50 heures et subit 4 pannes. Son MTBF est donc de 5,375 heures. Cela signifie qu’en moyenne, une panne survient toutes les 5,375 heures.
Pour bien comprendre comment calculer le MTBF de manière fiable, certaines bonnes pratiques sont essentielles :
utiliser des données précises ;
bien définir ce qu’est une panne (incident réel vs alerte mineure) ;
exclure les maintenances planifiées (elles ne reflètent pas une défaillance).
À retenir : plus le MTBF est élevé, plus votre infrastructure est considérée comme fiable et stable.
MTBF : 3 limites à connaître avant de l’utiliser
Bien que le MTBF soit un indicateur essentiel pour évaluer la fiabilité d’un système, il présente certaines limites qu’il est important de comprendre. En effet, le MTBF ne mesure pas la durée des pannes : pour cela, il est nécessaire de prendre en compte un autre indicateur complémentaire, le MTTR (Mean Time To Repair), qui évalue le temps moyen de résolution des incidents.
De plus, le MTBF ne reflète pas la gravité des pannes. Une infrastructure peut afficher un MTBF élevé tout en subissant des interruptions longues et critiques, impactant fortement les utilisateurs et les opérations.
Utilisé seul, le MTBF peut donc donner une vision incomplète, voire trompeuse, de la performance réelle d’un système. Pour une gestion efficace, il est essentiel d’adopter une approche globale ITOM, combinant plusieurs indicateurs pour une vision complète de la disponibilité.
C’est précisément ce que permet une solution de supervision comme OpManager. Elle ne se contente pas de calculer le MTBF, elle intègre aussi le MTTR pour une vision complète.
Aller plus loin avec ManageEngine OpManager
Dans un environnement IT de plus en plus complexe, s’appuyer uniquement sur des calculs manuels ou des analyses ponctuelles ne suffit plus. Une solution de supervision réseau proactive devient indispensable pour garantir la disponibilité des services et anticiper les incidents.
C’est dans cette logique que ManageEngine OpManager s’impose comme un outil clé. Il permet de collecter automatiquement les données d’uptime et de downtime sur l’ensemble de votre infrastructure, tout en détectant les anomalies en temps réel. Grâce à ses capacités de monitoring avancées, OpManager génère des rapports détaillés sur la disponibilité et calcule facilement des indicateurs essentiels comme le MTBF et le MTTR.
Les bénéfices sont immédiats : réduction du nombre de pannes, amélioration des performances IT et prise de décision basée sur des données fiables. En adoptant une telle solution ITOM, les équipes passent d’une gestion réactive des incidents à une approche prédictive, plus efficace et stratégique.
Au-delà du calcul, améliorer votre MTBF passe par des actions concrètes. Améliorer le MTBF de votre infrastructure IT nécessite la mise en place d’actions continues :
4 bonnes pratiques pour améliorer votre MTBF
Améliorer le MTBF de votre infrastructure IT nécessite la mise en place d’actions concrètes et continues. Tout d’abord, la maintenance préventive permet d’identifier et de corriger les anomalies avant qu’elles ne provoquent des pannes. Ensuite, une surveillance continue (monitoring 24/7) est essentielle pour détecter rapidement les incidents et réduire leur fréquence.
L’analyse des causes racines (RCA) joue également un rôle clé : comprendre l’origine des pannes permet d’éviter leur répétition. Par ailleurs, l’automatisation des alertes facilite la réactivité des équipes IT face aux anomalies. Enfin, le capacity planning permet d’anticiper les besoins en ressources et d’éviter les surcharges.
Des solutions comme ManageEngine OpManager facilitent l’application de ces bonnes pratiques en centralisant la supervision et en fournissant des données exploitables en temps réel.
Conclusion
Le MTBF s’impose comme un indicateur clé pour évaluer la fiabilité d’une infrastructure IT, mais il reste insuffisant lorsqu’il est utilisé seul. Comprendre comment calculer le MTBF correctement est essentiel pour en tirer des insights pertinents et orienter les décisions techniques. Toutefois, une approche globale, intégrant d’autres indicateurs et des outils ITOM, est nécessaire pour obtenir une vision complète de la performance.
En adoptant une solution de supervision comme ManageEngine OpManager, les équipes IT peuvent passer d’une gestion réactive des incidents à une approche proactive, plus efficace et durable.