Modelos de IA ahora pueden acceder fácilmente a la base de datos de Wikipedia, Wikidata y sus plataformas hermanas

¿Prefieres un resumen de este blog? ¡Da click en el botón de abajo y deja que ChatGPT te lo cuente! (también puedes probar con Perplexity)

Gracias a una reciente iniciativa de Wikimedia, organización que alberga Wikipedia y Wikidata, ahora es más sencillo emplear su expansiva base de datos para el entrenamiento y funcionamiento de modelos de IA. ¿Pero por qué es importante?
Ya debería ser de conocimiento general que la inteligencia artificial (IA) no es barata, en más de un sentido. Tanto su entrenamiento y funcionamiento requieren de grandes cantidades de electricidad y agua. Si bien tanto OpenAI como Google han asegurado que el gasto energético y del valioso líquido en el que incurren con sus respectivos modelos de IA es ínfimo, expertos se muestran escépticos ante tales cifras.
Hace un año, The Washington Post determinó que pedir un texto de 100 palabras a ChatGPT requiere 519 mililitros de agua y 0,14 kilovatios-hora (kWh). ¿Sigue siendo el caso? No hay certeza, pero varias fuentes —tales como el informe de consumo de energía de centros de datos de Estados Unidos de 2024 y el estudio Making AI Less "Thirsty": Uncovering and Addressing the Secret Water Footprint of AI Models— señalan que el consumo de energía y agua de los modelos de IA es proporcional a su potencia.
Lo anterior va de la mano con otra de las «materias primas» necesarias para el entrenamiento de la inteligencia artificial. Por supuesto, nos referimos a los datos.
¿Por qué los modelos de IA necesitan tantos datos?
Para ponerlo de forma muy simple, el entrenamiento de modelos de IA consiste en alimentarlos con conjuntos de datos. Mientras que un modelo sencillo requerirá una cantidad reducida o un tipo muy específico de datos, un modelo más complejo —como ChatGPT o Stable Diffusion, por ejemplo— necesita un número mucho más elevado.
Como se mencionó, procesar ese volumen de datos requiere mucha energía. Por eso, muchos pioneros de esta tecnología abogan por la adopción de la energía nuclear.
En el proceso de desarrollar modelos más avanzados, las compañías de IA están en una búsqueda desesperada por fuentes de datos. Al fin y al cabo, el internet no es un pozo ilimitado de información. Sin embargo, una reciente iniciativa de Wikimedia —organización que alberga Wikipedia, Wikimedia y otros proyectos de conocimiento libre— ha facilitado que su expansiva base de datos esté al alcance de la IA.
¿Qué es Wikidata Embedding Project?
Encabezado por Wikimedia Alemania, Wikidata Embedding Project es un sistema que aplica una búsqueda semántica basada en vectores a la base de datos de Wikidata. Ha estado en desarrollo desde 2024 y está disponible desde el 1 de octubre de 2025.
Durante un año, el equipo basado en Berlín trabajó arduamente para convertir 30 millones de entradas en Wikidata en vectores que comprenden el contexto y significado alrededor de cada entrada. Cabe aclarar que esta base de datos es mucho más grande que la información públicamente disponible en su plataforma hermana, Wikipedia.
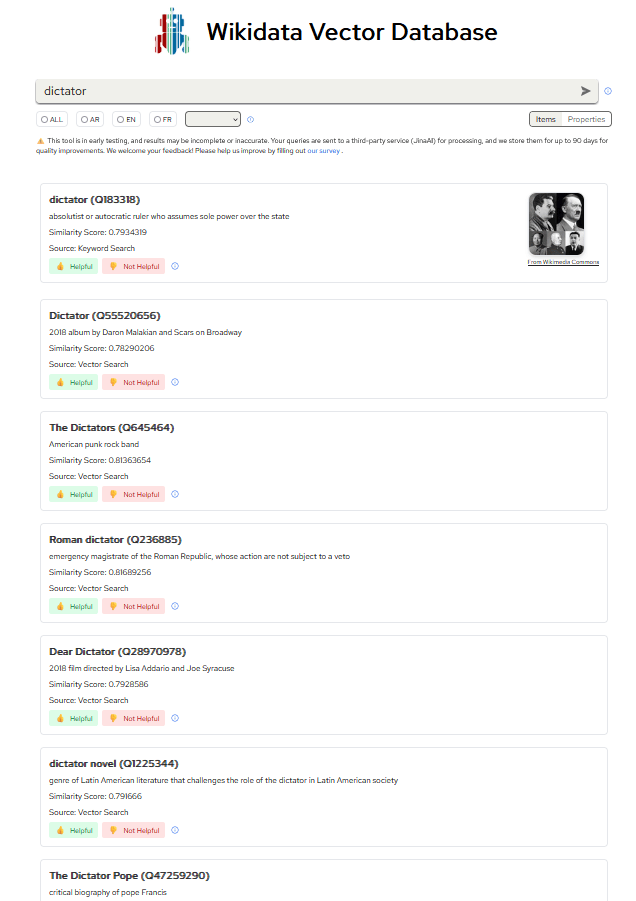
¿Qué quiere decir lo anterior? Por ejemplo, el resultado de buscar el término «dictador» ya no se limita a la definición de la palabra. Ahora, Wikidata ofrece una lista de figuras destacadas e incluso recursos audiovisuales relacionados con el término de búsqueda.
MCP, la pieza clave
Esto no tendría relevancia para los desarrolladores de IA si no fuera porque Wikidata Embedding Project tiene soporte para el estándar Model Context Protocol (MCP).
Como explica Wired, este protocolo ofrece un «idioma común» para que las IA se comuniquen con fuentes de datos externas, API o cualquier otro servicio. Antes de la creación de MCP, las herramientas disponibles solo permitían búsquedas por palabras clave y consultas SPARQL. Mientras que las primeras no logran capturar el significado detrás de una consulta, las últimas son complejas para el usuario promedio.
MCP ofrece lo mejor de ambos mundos: simplicidad y plenitud. ¡Y esa no es la única ventaja! Ya no es necesario diseñar un sistema de integraciones punto a punto.
Cómo Wikidata Embedding Project beneficia a los modelos de IA
Con la combinación de MCP y Wikidata Embedding Project, los desarrolladores de IA ahora cuentan con una base de datos robusta y verificada para entrenar sus modelos. Esto no solo garantiza que la inteligencia artificial entregue información confiable y extensa, sino que la fuente de dicha información no vulnere derechos de autor.
Philippe Saadé y Lydia Pintscher —gerente del proyecto y portfolio lead en Wikidata, respectivamente— explicaron a The Verge y TechCrunch que el objetivo de la iniciativa es equilibrar el campo de juego en favor de los desarrolladores de IA más pequeños.
“El lanzamiento de Wikidata Embedding Project demuestra que la IA potente no tiene por qué estar controlada por un puñado de empresas. Puede ser abierta, colaborativa y diseñada para servir a todos”.
Philippe Saadé, gerente de Wikidata AI project
¿La democratización es tan simple ?
Wikidata Embedding Project democratiza el acceso a los datos necesarios para el entrenamiento y funcionamiento de los modelos de IA. De eso no hay duda.
No obstante, Saadé y Pintscher omiten que el procesamiento de dichos datos todavía supone una inversión energética y de agua considerable. Dependiendo del tamaño de la compañía, esto puede seguir sin ser rentable ni sostenible. Por supuesto, el tamaño del modelo y las tareas para las que esté diseñado influirán en lo anterior. Aun así, esto no cambia el hecho de que los datos solo son una parte de la ecuación que es la IA.
Cabe señalar que no es la primera vez que se oyen promesas de una democratización de la IA. Ocurrió en su momento con Llama 2. E incluso si MCP reduce la carga computacional, lo que se traduce en costos más bajos y mayor eficiencia, solo resta esperar y ver si Wikidata Embedding Project puede ser un cambio de paradigma..
Ojalá apunte a un futuro en el que la IA sea una tecnología sostenible y rentable.
¿Quiere probar el buscador semántico de Wikidata?