Convierta la información en acción: Observabilidad, automatización y garantía basadas en IA
En el dinámico panorama empresarial actual, las operaciones de TI deben evolucionar de la resolución reactiva de problemas a la información proactiva. A medida que las nubes híbridas, los microservicios y las arquitecturas distribuidas redefinen la infraestructura moderna, ofrecer experiencias digitales eficientes ahora depende de una observabilidad profunda e inteligente.
Sin embargo, las herramientas de monitoreo convencionales a menudo se quedan cortas. Proporcionan vistas en silos, tienen dificultades para escalar o abruman a los equipos con alertas no correlacionadas que enmascaran la causa raíz. Lo que las empresas necesitan es una plataforma de observabilidad unificada, que ofrezca visibilidad contextual en todas las capas del ecosistema de TI, conecte de forma inteligente las señales con la información y permita responder automáticamente con base en los datos cuando más importa.
Con una solución de observabilidad completa, puede hacer lo siguiente:
Obtenga una visibilidad completa
Optimice el análisis de causa raíz
Garantice un rendimiento fiable
Acelere la detección y resolución de incidentes
Reduzca los costos generales
Mejore la colaboración entre equipos
La observabilidad redefine la forma en que las empresas entienden y gestionan los complejos entornos de TI, empoderando a los equipos para que pasen de simplemente monitorear lo que ha sucedido a descubrir por qué ha sucedido y evitar proactivamente que vuelva a suceder.

Nuestro reconocimiento en IDC MarketScape de 2025
Estamos orgullosos de compartir que Zoho Corp. (ManageEngine) ha sido reconocido como Major Player en IDC MarketScape: Evaluación de proveedores de plataformas de observabilidad a nivel mundial 2025 (doc. N.º US53004325, noviembre de 2025). Creemos que se trata de un importante reconocimiento a nuestra inversión y a nuestro éxito a la hora de llevar las prácticas de observabilidad impulsadas por la IA a las empresas de todo el mundo.
Creemos que estar incluidos en IDC MarketScape resalta las fortalezas de ManageEngine en áreas como:
- Observabilidad de extremo a extremo y correlación de eventos en entornos híbridos y nativos de la nube
- Detección de anomalías, análisis de causa raíz e información predictiva basados en IA/ML
- Orquestación del flujo de trabajo y remediación autónoma
- Escala, arrendamiento multi inquilino y preparación para la nube a la medida de las operaciones de las grandes empresas.
- Alineación de la experiencia del usuario y las operaciones para reducir el impacto en el negocio
Ahora veamos algunas de nuestras principales funciones de AIOps/observabilidad.
Nuestras principales funciones de observabilidad
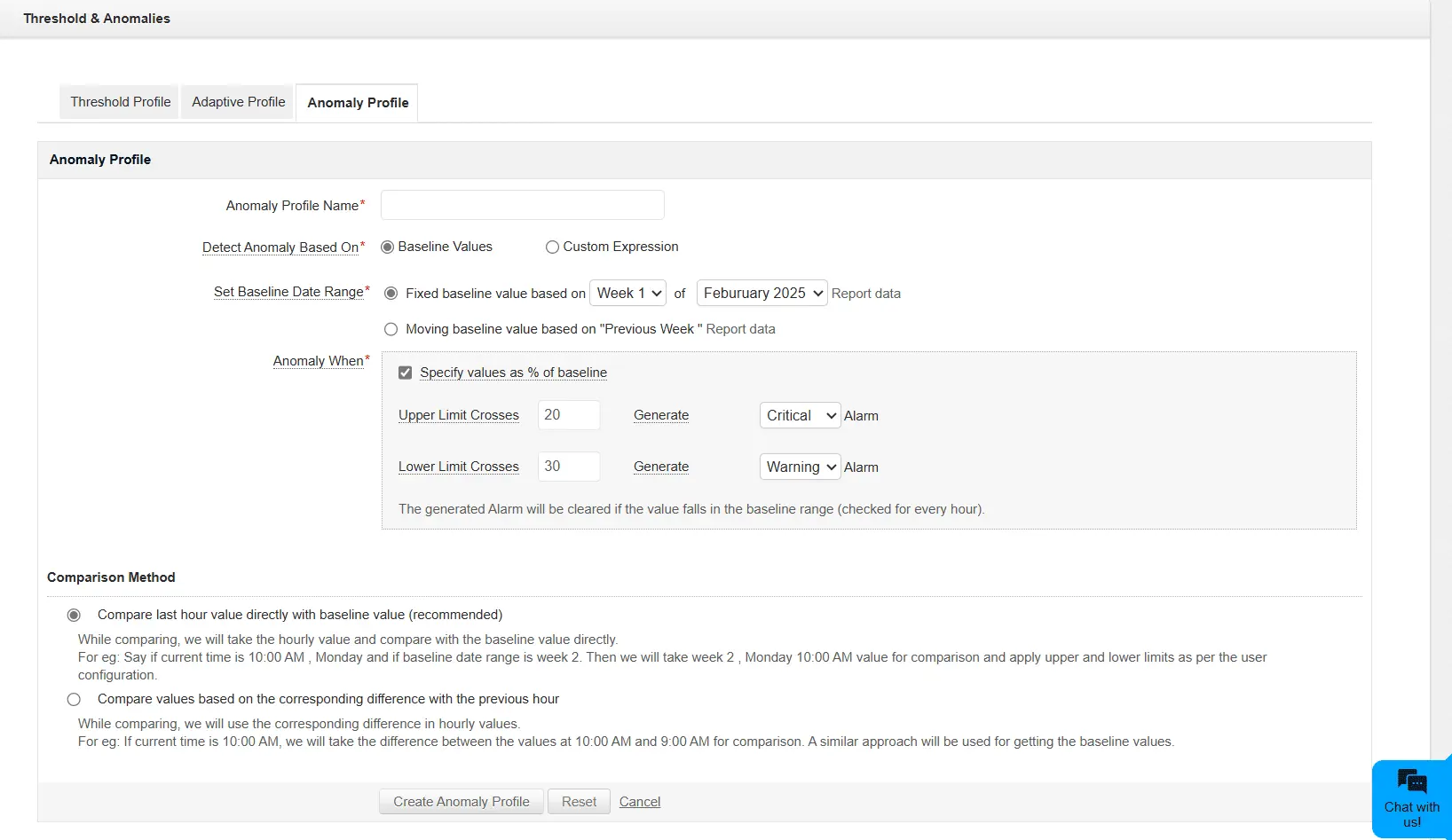
- Detección de anomalías
- Análisis predictivo basado en IA/ML
- Información basada en Gen Al
- Funciones de la plataforma
Las empresas modernas no pueden permitirse operar de forma reactiva. ManageEngine aprovecha la detección de anomalías basada en IA para detectar patrones irregulares en el rendimiento de TI antes de que se conviertan en fallos críticos. Mediante algoritmos avanzados de ML, ManageEngine analiza continuamente el comportamiento de la red, los servidores y las aplicaciones para detectar desviaciones de las líneas de base normales de rendimiento.
Monitoreo proactivo
El sistema identifica valores atípicos en métricas como la utilización de la CPU, el consumo de memoria y los tiempos de respuesta, lo que ayuda a los equipos de TI a abordar los posibles problemas antes de que afecten a las operaciones empresariales.
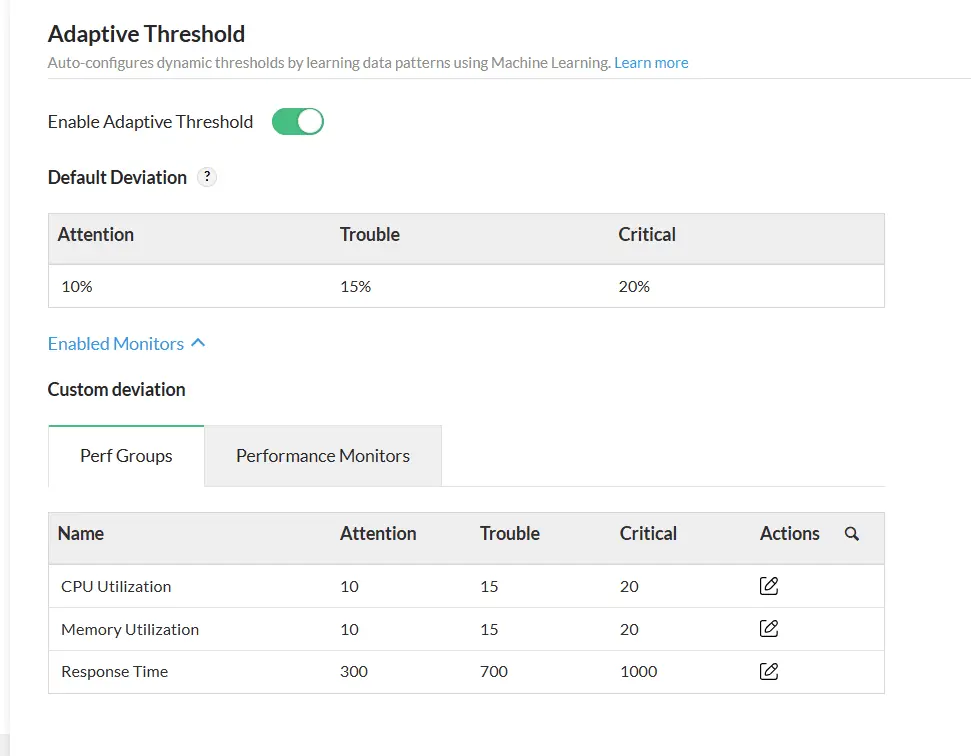
Umbrales dinámicos
A diferencia de los umbrales manuales tradicionales, los umbrales adaptables de ManageEngine se ajustan dinámicamente analizando los patrones de uso históricos y en tiempo real de su infraestructura, garantizando que su mecanismo de monitoreo tenga en cuenta el contexto.
Mejor respuesta a incidentes
Al detectar las anomalías a tiempo, los equipos de TI pueden mitigar los riesgos de forma proactiva, minimizar la inactividad y mejorar la fiabilidad general del servicio.
ManageEngine aprovecha el análisis predictivo para ayudar a los administradores de TI a anticipar los fallos de la infraestructura, la degradación del rendimiento y las limitaciones de recursos. Sus algoritmos de ML internos analizan continuamente el comportamiento de la infraestructura a lo largo del tiempo, identificando patrones para prever posibles problemas. Esta información predictiva permite detectar fallos de forma proactiva, lo que permite a los administradores abordar los cuellos de botella de recursos y las anomalías de rendimiento de forma preventiva. Además, ManageEngine recomienda acciones correctivas para mitigar los riesgos y garantizar un rendimiento óptimo de la infraestructura.
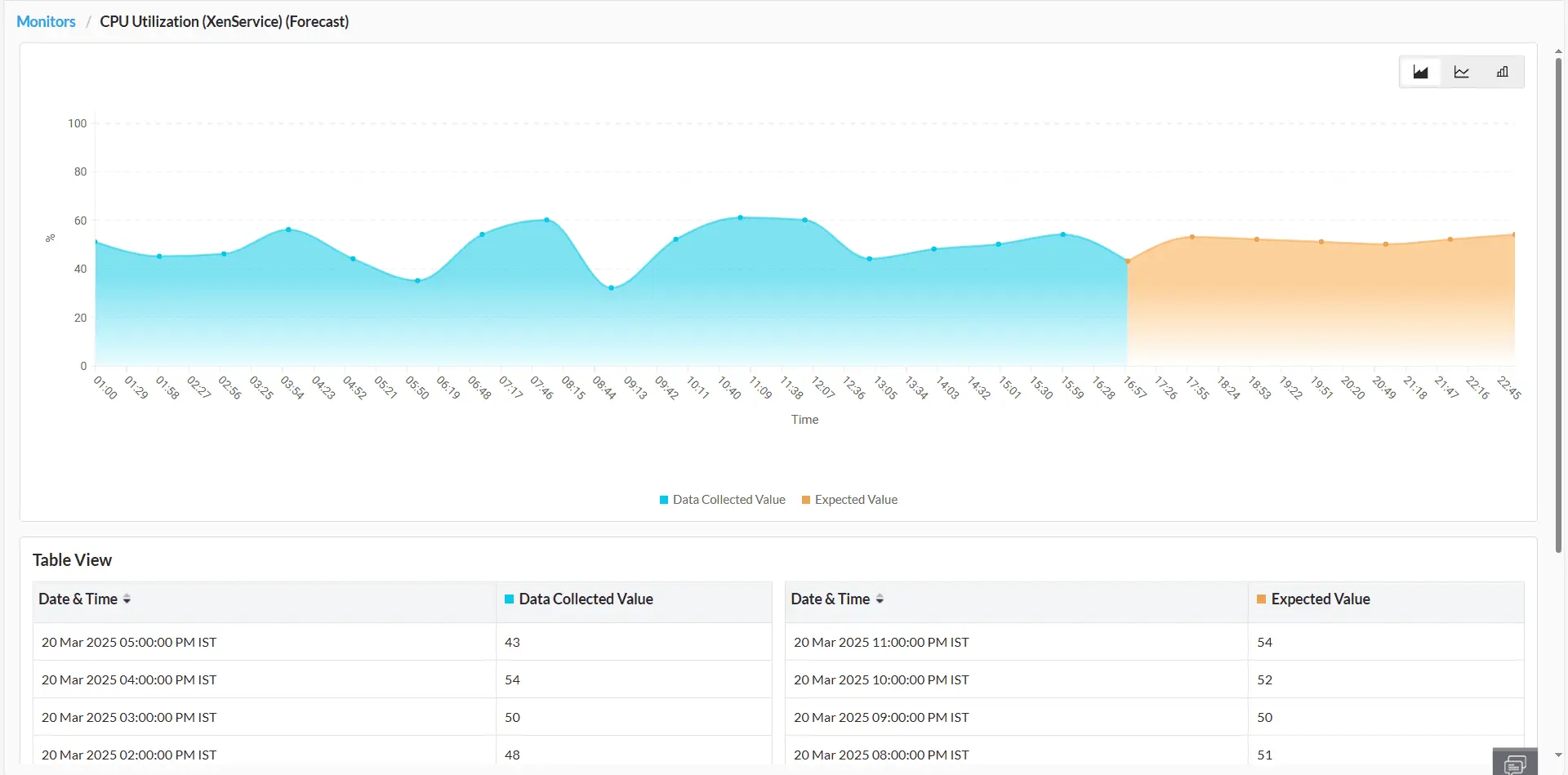
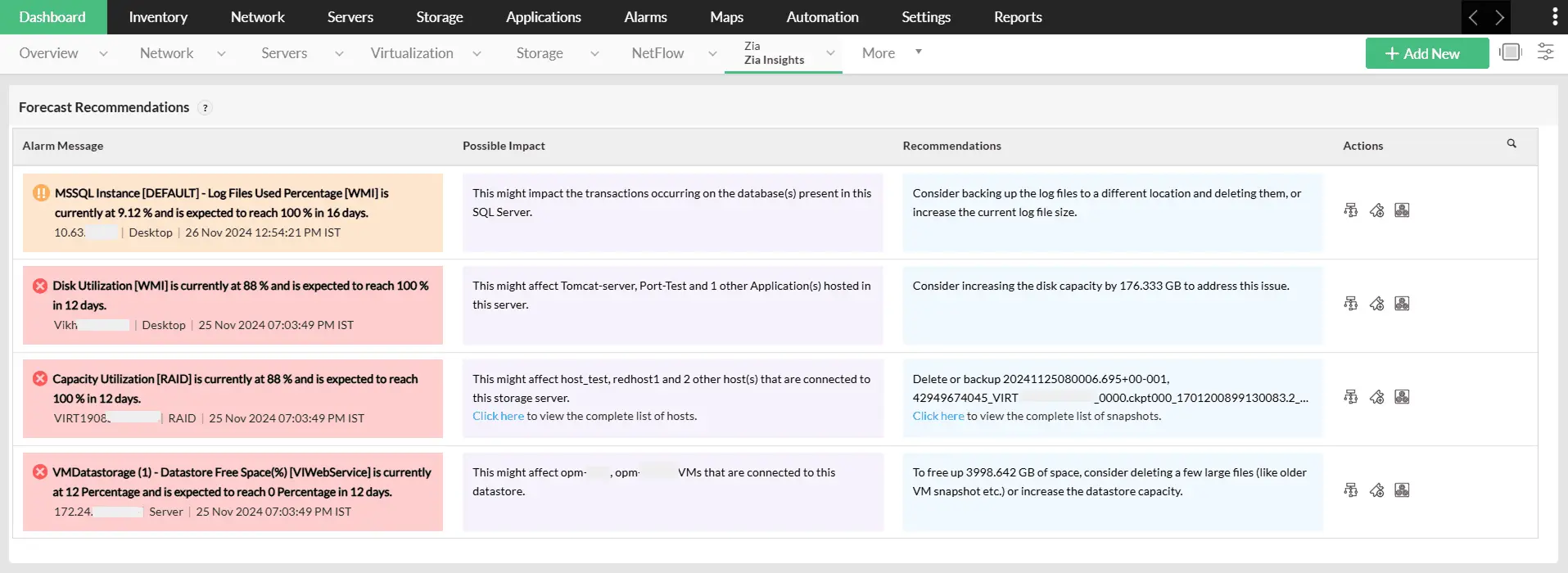
Previsión de tendencias de rendimiento
Utilice algoritmos basados en IA para predecir con exactitud las tendencias futuras del rendimiento de la infraestructura, lo que permite adoptar medidas proactivas para alinearse con las demandas cambiantes de su entorno de TI. Más información.
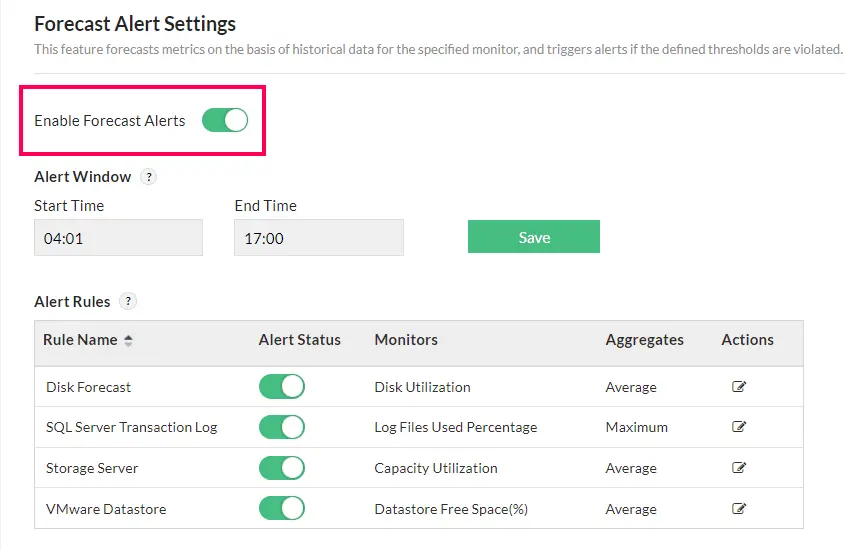
Alertas de previsión
Anticipe el agotamiento de los recursos prediciendo el tiempo estimado hasta que los recursos de la red alcancen umbrales críticos. Esta predicción se logra observando de forma continua los patrones de uso de los recursos a lo largo del tiempo y se analiza mediante un avanzado motor de predicción. Basándose en estas previsiones, se activan alertas proactivas que permiten a los administradores de red mitigar los riesgos e implementar estrategias efectivas de planificación de la capacidad. Más información.
Dashboards de Zia Insights
Convierta los cuellos de botella de las previsiones en información práctica con los dashboards de Zia Insights. Reciba recomendaciones basadas en IA sobre los fallos previstos en la infraestructura y manténgase a la vanguardia empoderando a sus equipos de TI para que actúen de forma proactiva y mitiguen los fallos incluso antes de que se produzcan. Más información.
Aproveche el poder de la IA generativa para transformar los datos brutos de observabilidad en inteligencia accionable. Desde recomendaciones predictivas hasta interfaces conversacionales, estas funciones ayudan a los equipos a trabajar de forma más inteligente, no más difícil.
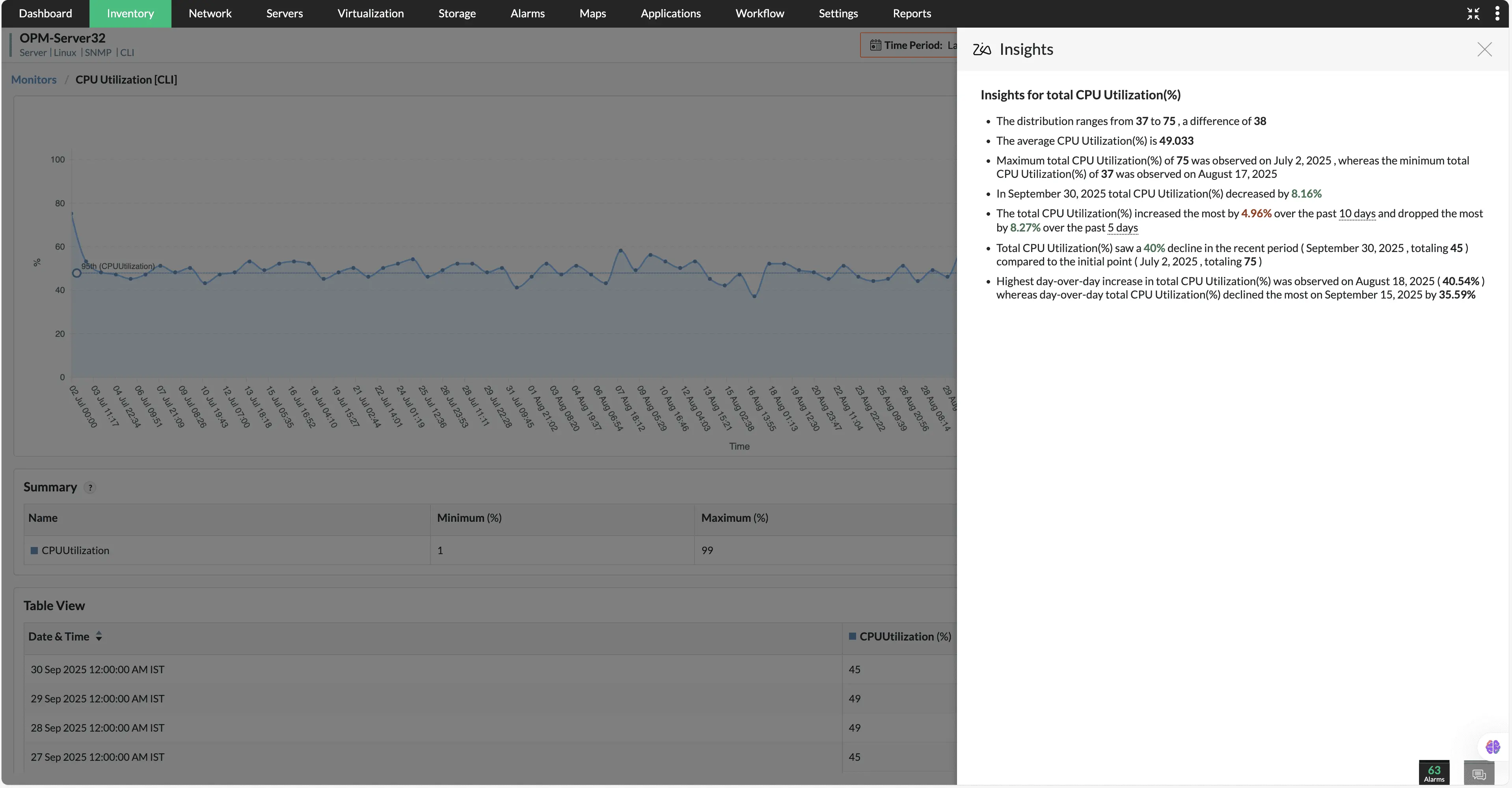
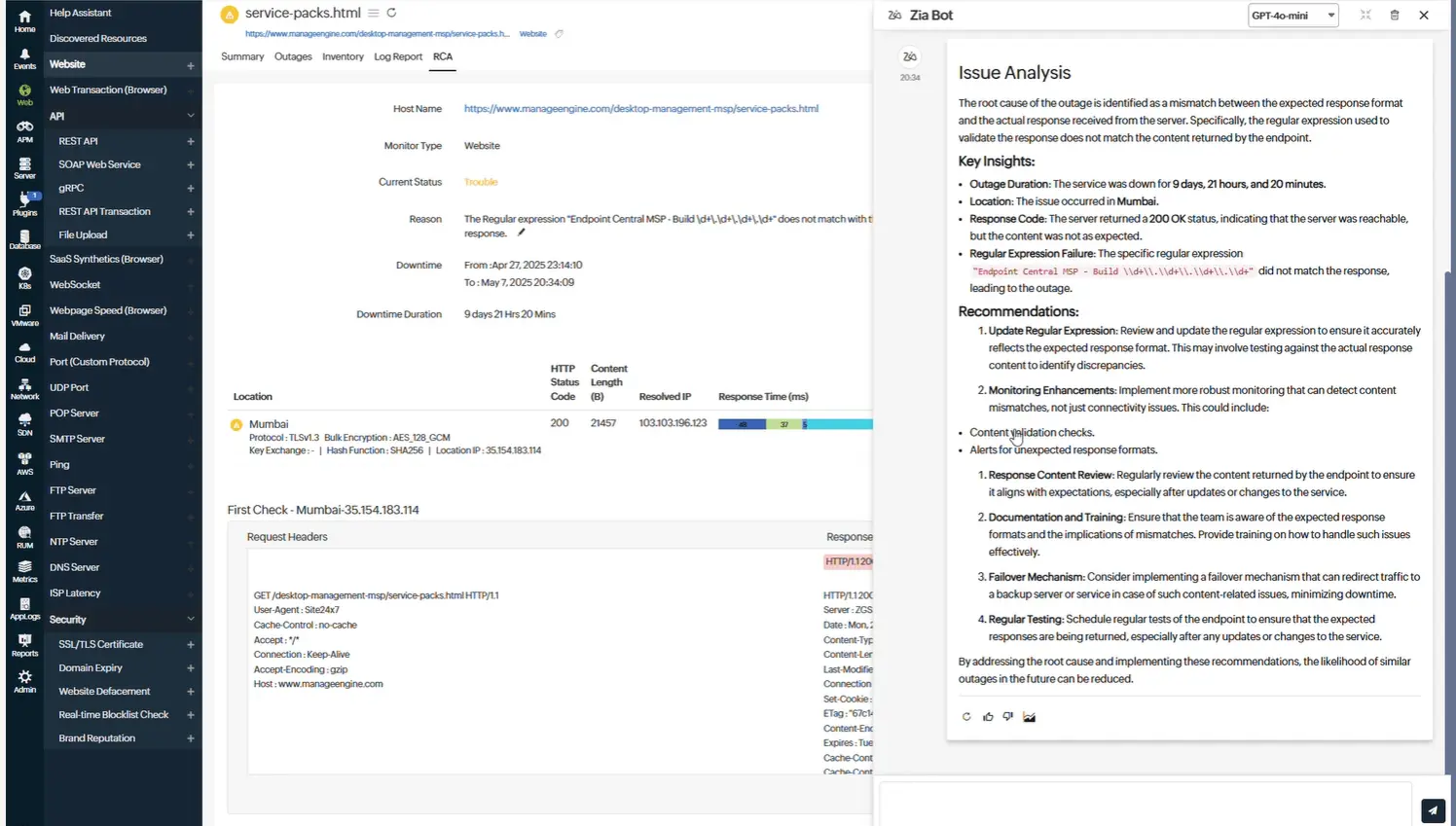
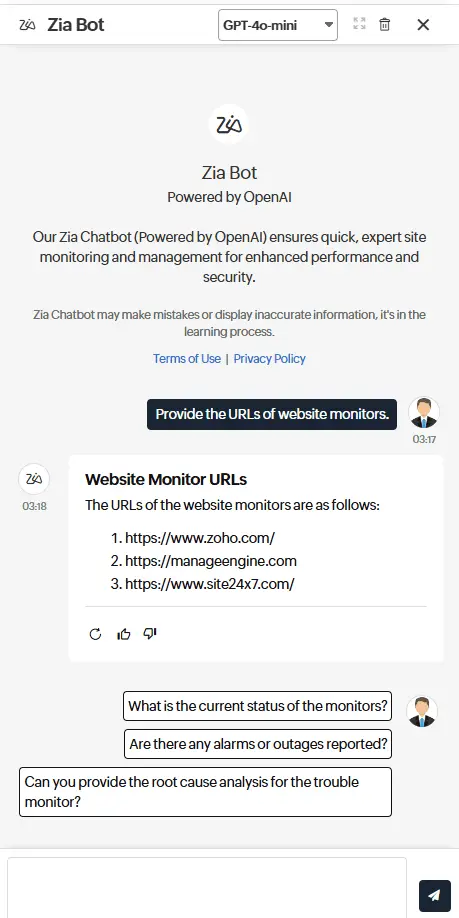
Zia Insights
Transforme fácilmente los datos sin procesar y complejos en información clara y procesable. Con nuestro modelo interno de IA, los equipos de TI pueden analizar el rendimiento del dispositivo mediante resúmenes concisos y legibles por humanos en lugar de rebuscar en densos gráficos y puntos de datos.
Análisis de causa raíz (RCA) automatizado
Impulsada por LLM avanzados, la plataforma correlaciona automáticamente los datos de telemetría a través de métricas, logs y trazas para identificar las causas raíz más probables. Esto acelera el aislamiento de fallos y minimiza la inactividad al eliminar las conjeturas durante la resolución de problemas.
Interfaz de chat en lenguaje natural
Interactúe con sus datos de observabilidad a través de un chatbot conversacional. Utilice un lenguaje sencillo para consultar logs, métricas y trazas, o genere resúmenes legibles por humanos sobre los incidentes y anomalías, permitiendo a los equipos comprender fácilmente y actuar rápido.
Nuestra plataforma empodera a los equipos de TI con una observabilidad de extremo a extremo en toda la infraestructura, las aplicaciones y los servicios, proporcionando una visión unificada que rompe con los silos operativos. Al consolidar métricas, eventos y telemetría de diversas fuentes, permite obtener información más rápida, monitorear de forma proactiva y agilizar las operaciones, garantizando que los equipos de TI y DevOps puedan gestionar entornos complejos de forma eficiente y mantener un rendimiento óptimo del servicio.
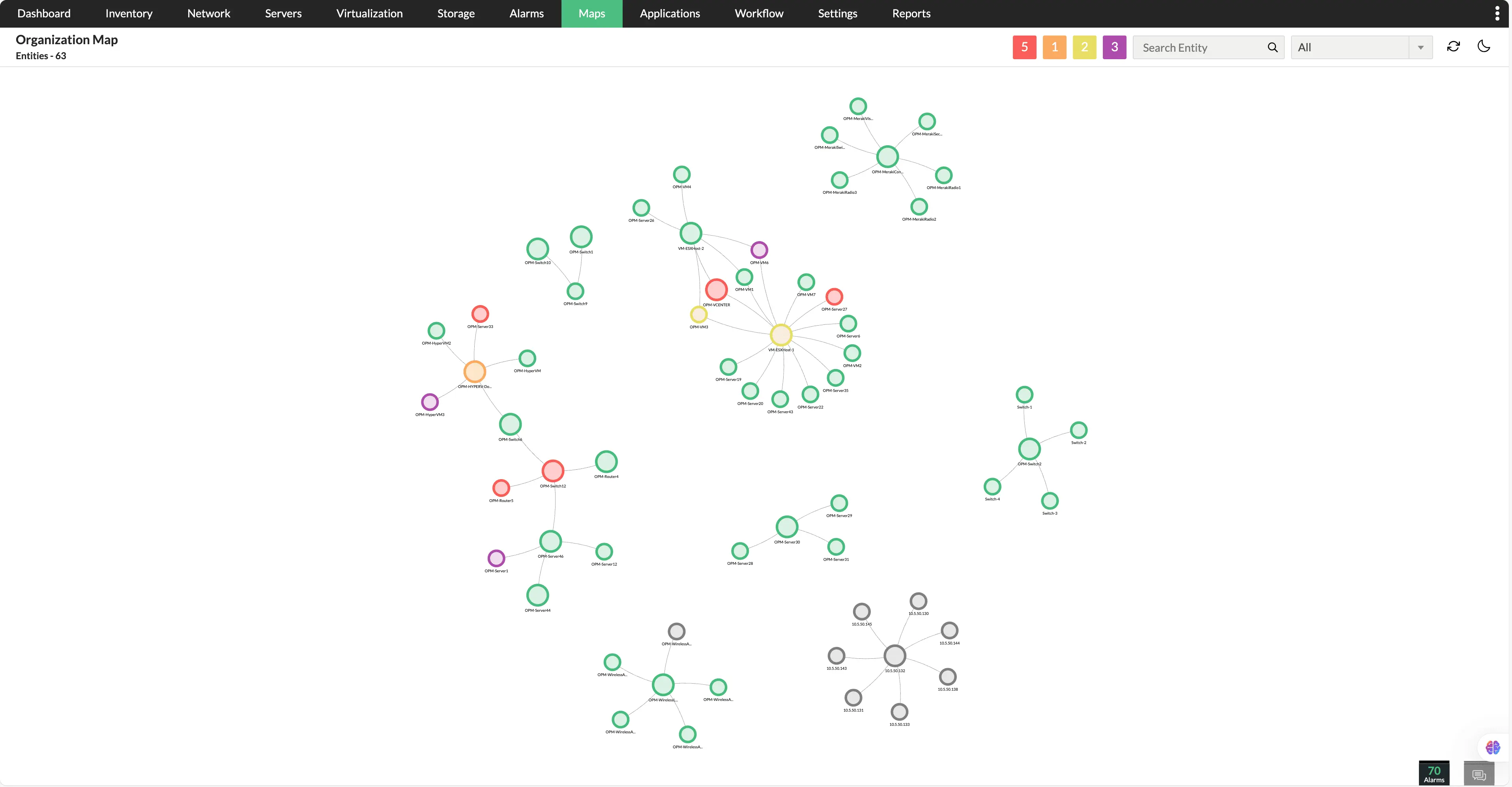

Vista de topología de pila completa
Obtenga una vista topológica dinámica y en tiempo real de su infraestructura, mostrando las relaciones entre dispositivos, aplicaciones y servicios. En lugar de navegar a través de puntos de datos dispersos, los equipos de TI pueden ver las dependencias de un vistazo, lo que les ayuda a identificar rápidamente las áreas problemáticas, comprender el impacto potencial y optimizar los esfuerzos de solución de problemas.
Ecosistema de TI unificado
Se integra de manera eficiente con plataformas de ITSM, herramientas de colaboración y servicios en la nube para centralizar el monitoreo y la respuesta al incidente.
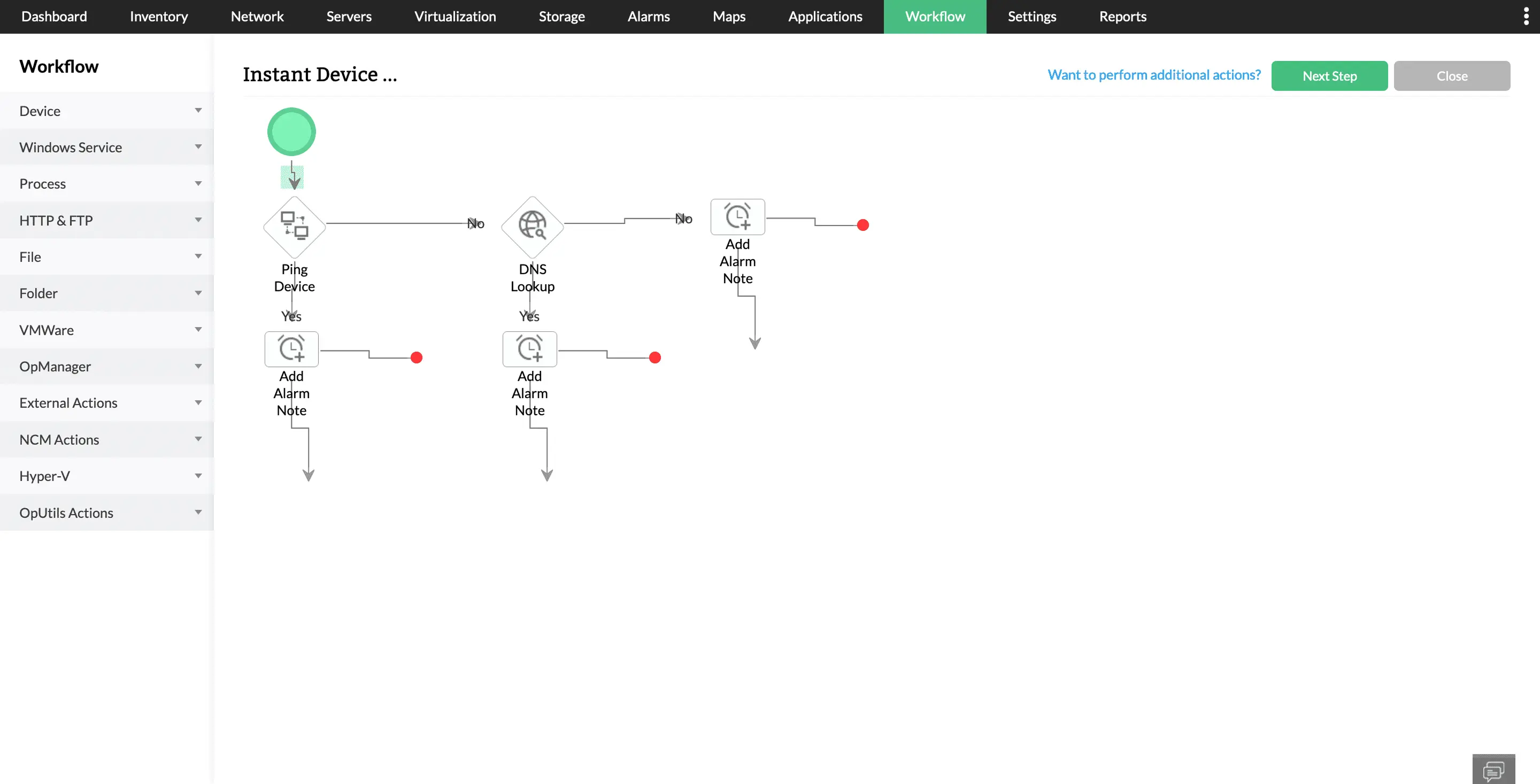
Integraciones a medida y flujos de trabajo automatizados
Utilice integraciones personalizadas, con API o webhooks para personalizar la resolución de problemas. Aproveche los flujos de trabajo automatizados y basados en disparadores para implementar medidas de resolución de fallos de nivel 1.
5 razones por las que empresas de todo el mundo eligen ManageEngine

- Fiable: Más de 20 años de presencia en el mercado
- Rentable: Mejores funciones a menor precio
- Seguro: Cumple las normas y reglamentos más exigentes
- Moderno: Funciones de monitoreo y seguridad más recientes
- Cómodo: Automatización avanzada e interfaz intuitiva
Con la confianza de 1 millón de administradores de TI en todo el mundo
Las principales marcas mundiales nos confían su TI







Amado por los clientes de todo el mundo





“OpManager helps me monitor all aspects of the data-center and equipment like servers, switches and routers. It is fast, intuitive and centralized and you do not need to be an expert to deal with OpManager.”
Altaleb Alshenqiti
NGHA

“Donald Stewart, IT Manager of Crest Industries is happy with ManageEngine OpManager for its end-to-end network monitoring software. It is easy-to-use and offers fault and performance management for router.”
Donald Stewart
IT Manager, Crest Industries

“John Rosser, MIS Manager of Yale Chase talks about the proactive nature of ManageEngine OpManager & how his organisation gained value from it.”
John Rosser
MIS Manager