Las herramientas para el monitoreo de la red son soluciones especializadas que le ayudan a monitorear el rendimiento, la disponibilidad y la salud general de los componentes de la infraestructura de TI, como routers, firewalls, servidores, switches y aplicaciones. Obtienen datos de monitoreo de diferentes segmentos de su pila de TI y proporcionan una vista consolidada en una única consola. Esto permite a los equipos de TI identificar problemas de forma proactiva, analizar tendencias y garantizar un rendimiento óptimo. En esta página, discutiremos los siguientes temas:
- El rol de una herramienta para el monitoreo de la red
- Tipos de herramientas para el monitoreo de la red
- Métricas que debe tener en cuenta
- ¿Cómo elegir el software adecuado para el monitoreo de la red?
- Funciones de monitoreo de la red en OpManager
El rol de las herramientas para el monitoreo de la red
Las redes empresariales modernas son híbridas (una combinación de on-premises y en la nube) y distribuidas, extendiéndose por ubicaciones geográficas con múltiples sucursales y centros de datos. Una herramienta para el monitoreo de la red simplifica el monitoreo, proporcionando una visibilidad completa de la salud y el rendimiento de cada dispositivo, aplicación e interfaz. Con una visibilidad completa de toda su red y un monitoreo inteligente impulsado por IA/ML, las empresas pueden identificar y abordar los problemas potenciales antes de que afecten a las operaciones.
Tipos de herramientas para el monitoreo de la red
- Herramientas con agente: Requiere instalar agentes ligeros en los dispositivos para recopilar datos detallados sobre el rendimiento, como el uso de la CPU, el consumo de memoria, la actividad del disco y las métricas específicas de la aplicación.
- Herramientas sin agente: El monitoreo sin agente es ideal para entornos en los que instalar agentes resulta poco práctico. Las herramientas para el monitoreo sin agente utilizan protocolos como SNMP, WMI o API para supervisar los dispositivos sin necesidad de instalaciones adicionales, lo que garantiza una implementación más rápida.
| Tipo | Ventajas | Desventajas |
|---|---|---|
Con agente | ✅Los agentes operan localmente en los dispositivos monitoreados, recopilando métricas, logs y datos de rendimiento de forma independiente. Esto significa que puede continuar recopilando métricas de rendimiento ininterrumpidamente, incluso si el sistema central de monitoreo se cae temporalmente. ✅Ya que los agentes se implementan localmente en el dispositivo, libera la carga del sistema central. Esto significa que el monitoreo con agente escala de manera eficiente. | ❌La recopilación de datos depende totalmente del agente. Así que, si el agente se cae, puede dificultar la recopilación de datos. ❌Los agentes requieren un mantenimiento regular y actualizaciones periódicas de la versión para evitar vulnerabilidades de seguridad y garantizar la compatibilidad con las últimas funciones. |
Sin agente | ✅Dado que no es necesario implementar ningún agente en los dispositivos de destino, reduce la carga administrativa y simplifica la implementación. ✅Dado que el monitoreo sin agente utiliza protocolos estándar, admite una amplia variedad de dispositivos. | ❌En redes a gran escala con miles de dispositivos, el total de solicitudes de sondeo puede suponer una carga significativa tanto para el servidor de monitoreo como para la red, lo que provoca una recopilación de datos más lenta. ❌Dado que el sistema de monitoreo consulta activamente cada dispositivo a través de la red en busca de métricas, el monitoreo sin agente consume más ancho de banda en comparación con las soluciones con agente. |
Métricas de monitoreo de la red importantes que debe supervisar para garantizar la continuidad de la empresa
Sea cual sea su sector, hay un factor común: el rendimiento de la red influye directamente en los resultados empresariales. Las interrupciones en la prestación del servicio no sólo afectan a la infraestructura de TI, sino que a menudo se traducen en pérdida de ingresos, mala experiencia del cliente e ineficiencias operativas.
A continuación, se enumeran algunas de las principales métricas de rendimiento que son comunes en cualquier industria. Supervisarlas permite a los equipos de TI mantener los sistemas en buen estado, conservar la capacidad de respuesta de los servicios y garantizar la máxima continuidad de la empresa
| Métrica | Descripción |
|---|---|
| Uso de la CPU | Mide la utilización del procesador. Los picos repentinos o sostenidos suelen ser una señal de sobrecarga de recursos o de procesos desbocados. |
| Uso de la memoria | Supervisa el consumo de RAM. Un uso elevado y persistente indica que hay contención, con el consiguiente riesgo de ralentización de la aplicación. |
| Latencia | Una latencia elevada degrada el rendimiento de la aplicación. Puede deberse a barreras físicas o a problemas en los protocolos de enrutamiento. |
| Velocidad de transferencia | Cantidad de datos transmitidos a través de la red en un tiempo determinado. Una baja velocidad de transferencia sugiere que hay congestión o cuellos de botella en el ancho de banda. |
| Utilización del ancho de banda | Porcentaje de ancho de banda disponible que se está consumiendo. Ayuda a identificar la sobreutilización, las necesidades de capacidad o los picos de tráfico y contribuye a la optimización de los recursos. |
| Tiempo de respuesta | Mide el tiempo que tarda un servidor o una aplicación en responder a las solicitudes. Crítico para la experiencia del usuario. |
| MOS (puntuación de opinión media) | Un estándar para evaluar la calidad de la voz en WAN/VoIP. Las puntuaciones más altas indican una mayor claridad de audio. |
| Jitter | Variación de los tiempos de llegada de los paquetes. Una alta fluctuación interrumpe las llamadas VoIP, las reuniones de vídeo y otros servicios en tiempo real. |
| Pérdida de paquetes | Porcentaje de paquetes de datos perdidos en la transmisión. Incluso las pequeñas pérdidas pueden provocar llamadas interrumpidas, congelaciones de vídeo o fallos en las transacciones. |
Monitorear una sola métrica no es suficiente. Supervisar valores como la utilización de la CPU o la latencia de la red de forma aislada sólo ofrece una visión parcial de su entorno de TI. Para obtener una imagen completa, es esencial correlacionar las métricas y comprender el contexto que hay detrás de ellas. Estas son algunas de las mejores prácticas que debe tener en cuenta al monitorear:
1. Dar prioridad a las métricas
Cada dispositivo de su red tiene una importancia diferente. Los servidores de producción críticos pueden requerir un monitoreo constante del uso de la CPU, la memoria y el disco, mientras que los equipos de prueba o desarrollo pueden necesitar más atención hacia las aplicaciones o procesos específicos que se ejecutan en ellos. En lugar de adoptar un enfoque "universal", determine las métricas que se deben monitorear para cada tipo de dispositivo y priorícelas.
2. Personalizar los intervalos de sondeo
La frecuencia de sondeo determina la frecuencia con la que su herramienta de monitoreo recopila datos de los dispositivos. El sondeo de alta frecuencia (por ejemplo, cada minuto) no es necesario para todos los dispositivos y puede sobrecargar la solución de monitoreo impactando en su rendimiento. Por lo tanto, establezca intervalos que se basen en la criticidad del dispositivo. De este modo se optimiza el rendimiento del sistema al tiempo que se identifican a tiempo los posibles problemas.
3. Implementar controles de acceso
No todo el mundo debe ver o tener acceso a todos los datos monitoreados. Implemente el acceso basado en roles para garantizar que los miembros del equipo vean sólo lo que es relevante para sus responsabilidades. Proporcione credenciales con privilegios mínimos. Por ejemplo, en un equipo Windows, el acceso de SNMP suele ser suficiente para el monitoreo, mientras que el acceso de WMI permite operaciones críticas como detener procesos. Al proporcionar únicamente los privilegios de acceso necesarios, puede evitar cambios accidentales o malintencionados en los servidores y dispositivos.
4. Alinear el monitoreo con los requisitos de cumplimiento
Ciertas industrias como las finanzas, la salud o las telecomunicaciones tienen normas estrictas sobre la disponibilidad de los sistemas. La inactividad por encima de un umbral definido puede dar lugar a multas, sanciones o medidas reglamentarias. Asegúrese de que sus intervalos de sondeo, umbrales y mecanismos de alerta están configurados para cumplir estos requisitos de conformidad. Audite y ajuste regularmente las configuraciones de monitoreo para alinearlas con las normativas vigentes y las directivas organizacionales.
¿Cómo elegir la solución adecuada para el monitoreo de la red?
Cuando seleccione una herramienta para el monitoreo de la red, busque funciones que vayan más allá del monitoreo básico, aquí tiene cinco buenas prácticas que le serán útiles durante la fase de evaluación de la herramienta.
- Monitoreo inteligente con IA/ML
- Mejorar la respuesta a incidentes con la automatización
- Simplificar la resolución de problemas con el RCA
- Funciones de observabilidad de pila completa
- Historias de éxito
1. Lograr un monitoreo inteligente con IA/ML
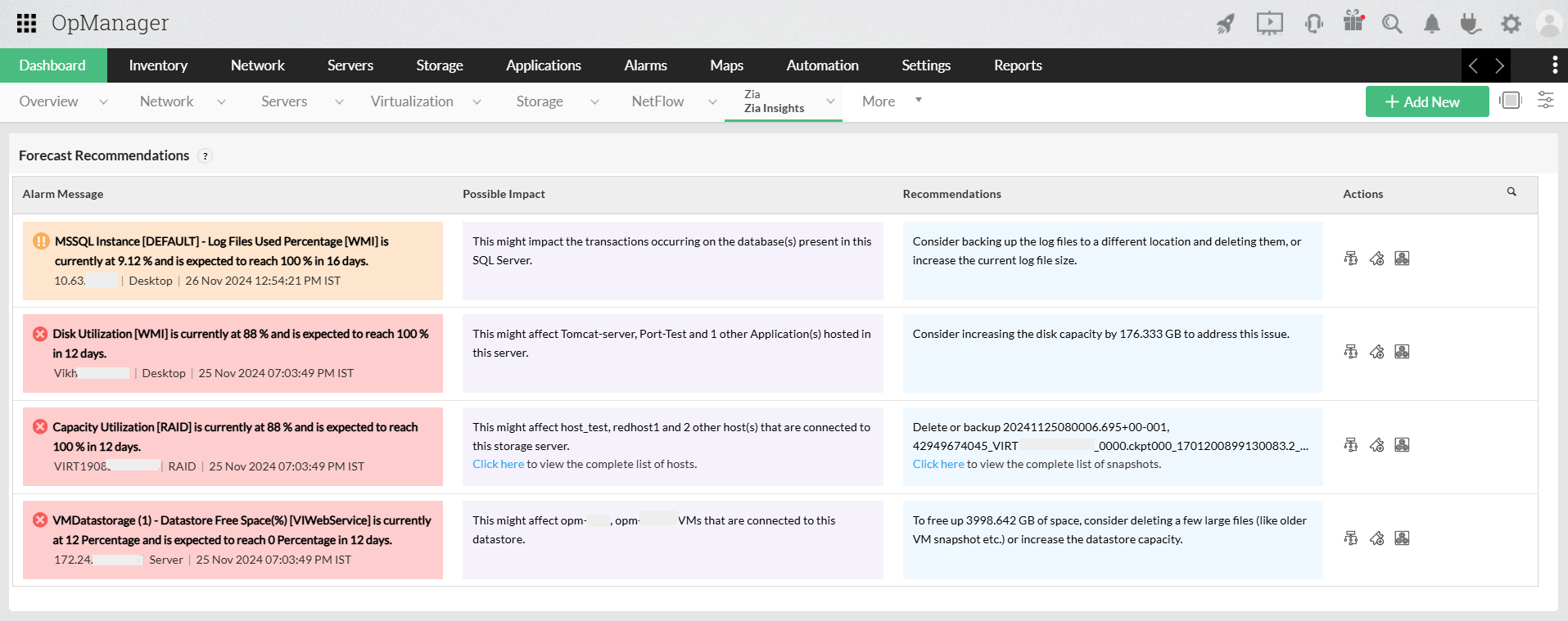
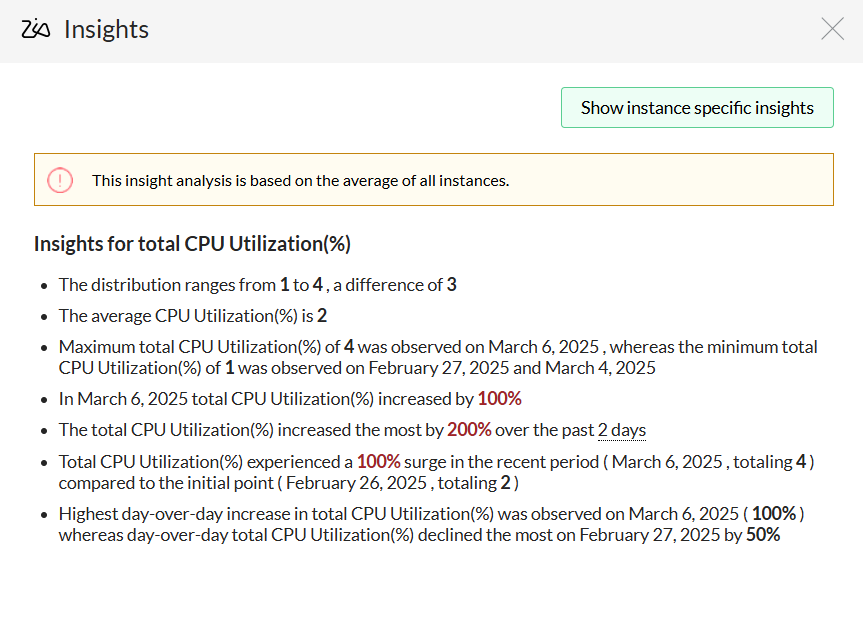
Las herramientas modernas para el monitoreo de la red aprovechan la IA y el ML para manejar volúmenes masivos de datos con mayor efectividad. Aprovechan las técnicas de ML para establecer umbrales dinámicos y detectar anomalías y le permiten centrarse en los problemas críticos, reduciendo el ruido de las falsas alertas. Mediante la correlación de eventos y el análisis de causa raíz (RCA), estas herramientas identifican rápidamente el problema subyacente, mientras que las previsiones basadas en ML predicen los posibles problemas futuros y su impacto, proporcionando a menudo recomendaciones prácticas.
Las herramientas avanzadas incluso pueden tomar acciones correctivas automatizadas, ayudando a prevenir la inactividad y permitiéndole adoptar un enfoque proactivo para la gestión de la red. A la hora de seleccionar una solución de monitoreo, dé prioridad a los proveedores con estas funciones de IA/ML para pasar de un monitoreo reactivo a uno inteligente.
2. Acelerar la respuesta a incidentes con la automatización
Esfuerzo manual al momento de realizar tareas de monitoreo repetitivas y propensas al error humano. Con la automatización puede optimizar las tareas rutinarias y la resolución de problemas, ahorrando tiempo y mejorando la respuesta ante incidentes.
Además, compruebe si la herramienta se integra con las plataformas de ITSM, ya que esto puede mejorar enormemente la gestión de incidentes. Algunas funciones como la visualización sincronizada, la actualización automática de tickets en todos los sistemas y la sincronización con la CMDB garantizan que los problemas se supervisen de forma consistente y se resuelvan con mayor rapidez, proporcionando un flujo de trabajo más conectado y eficiente.
3. Reducir la inactividad con un efectivo análisis de causa raíz
Resolver los problemas complejos puede ser todo un reto, especialmente en grandes entornos de TI. Gracias a las avanzadas funciones de análisis de causa raíz (RCA), las modernas herramientas de monitoreo reúnen todos los datos relevantes en una única vista, lo que facilita la correlación de eventos, el análisis de dependencias y la rápida delimitación del origen de los problemas.
Además, gracias a la información basada en IA/ML, estas herramientas incluso pueden prever posibles problemas y resaltar por qué pueden producirse, lo que permite a los equipos de TI solucionarlos de forma proactiva antes de que se conviertan en una cascada de interrupciones importantes.
4. Adoptar las funciones de Observabilidad Full Stack (FSO)
Al evaluar las herramientas para el monitoreo de la red, es importante buscar una observabilidad de pila completa que proporcione visibilidad en todo su entorno de TI, incluida la conectividad de la red, los servidores, las aplicaciones, las bases de datos, la nube y los contenedores.
La observabilidad va más allá del monitoreo tradicional, ya que no se limita a recopilar métricas, logs y trazas, sino que los correlaciona para proporcionar información procesable y rica en contexto. Esto permite a los equipos de TI identificar la causa raíz de los problemas, predecir posibles fallos y optimizar el rendimiento de forma proactiva.
5. Buscar historias de éxito de proveedores relevantes para su sector
Analice si algún cliente de su dominio ha usado y se ha beneficiado del proveedor. Siempre que sea posible, solicite estudios de casos reales que reflejen las necesidades de su sector para ver el impacto tangible conseguido. Este enfoque le ayudará a elegir el proveedor más adecuado que no sólo se ajuste a sus necesidades, sino que además le ofrezca un valor comprobado.
OpManager: Su herramienta para el monitoreo de la red Full-Stack
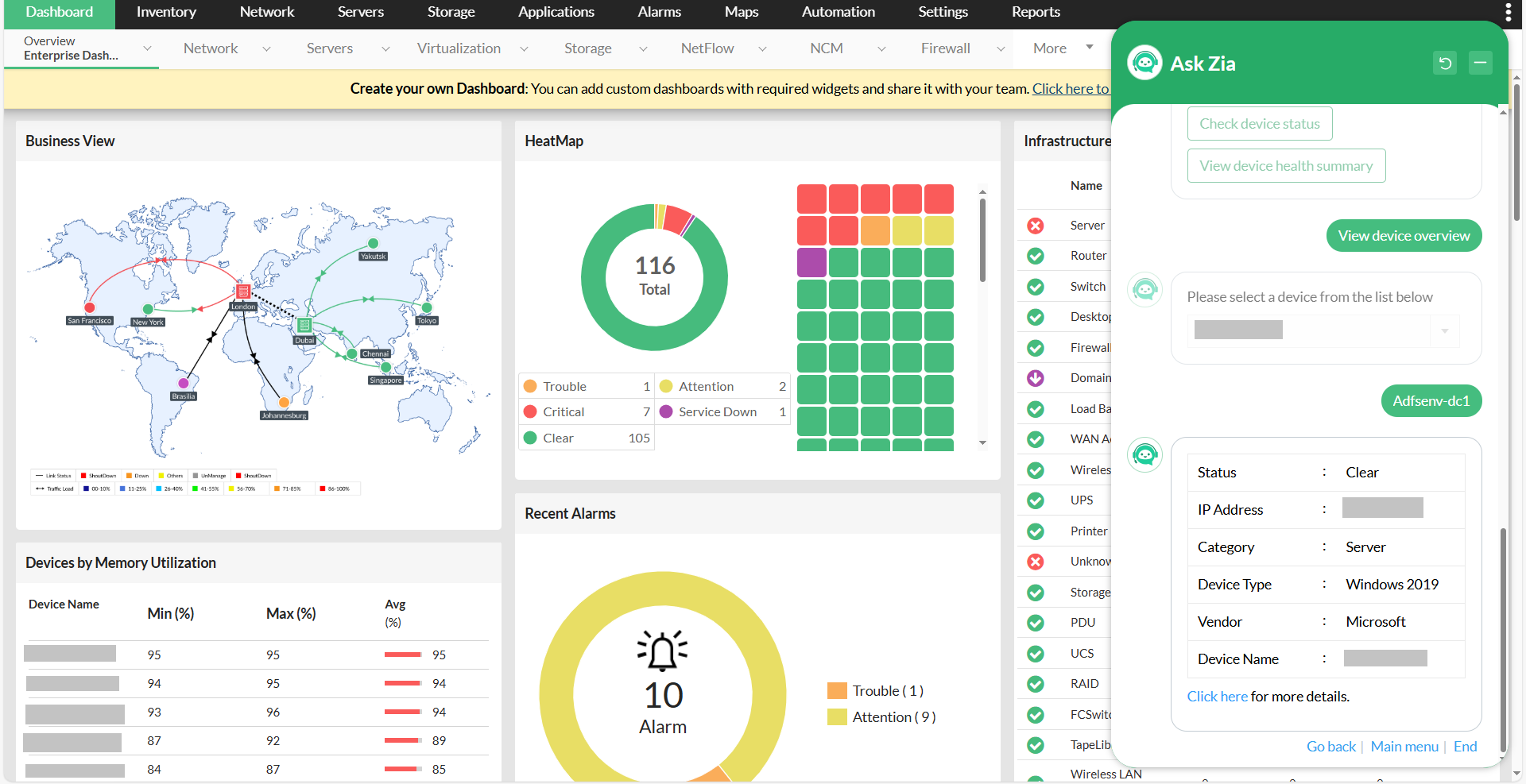
OpManager es una solución para el monitoreo del rendimiento de la red independiente del proveedor, diseñada para gestionar con facilidad entornos de TI híbridos. Es compatible con más de 11.000 plantillas de dispositivos y más de 53.000 métricas out-of-the-box, lo que proporciona una visibilidad integral de toda su pila de TI desde una consola centralizada.
Considerada una solución asequible con funciones robustas, se adapta a empresas de todos los tamaños. Sus más recientes funciones impulsadas por Zia, incluyendo dashboards, información detallada y capacidades de chatbot, demuestran su compromiso de satisfacer las demandas que evolucionan de acuerdo con las tendencias del sector.