Network resilience 2026: Framework untuk infrastruktur yang lebih tangguh

Bagi pengguna maupun pelanggan, kestabilan jaringan merupakan kebutuhan dasar. Mereka tentu tidak ingin koneksi terputus di tengah interaksi penting atau kehilangan akses ke data yang krusial. Sebagai contoh, koneksi tiba-tiba terputus saat berinteraksi dengan chatbot help desk. Data yang disimpan dalam aplikasi cloud tiba-tiba hilang setelah aplikasi down.
Jika salah langkah, terputusnya koneksi jaringan dapat menyebabkan efek berantai. Keluhan pelanggan menyebar dengan cepat, reputasi organisasi hancur, potensi pendapatan hilang, hingga risiko keamanan dan kepatuhan meningkat.
Itulah mengapa, organisasi semakin dituntut untuk menghadirkan jaringan yang resilience. Jaringan harus tetap memberikan fungsionalitas terbaik, tak peduli bagaimana pun situasinya. Baik ketika ada pemadaman listrik, serangan siber, maupun gangguan tidak terduga lainnya. Jangan sampai hal-hal tersebut menurunkan performa atau menghentikan operasional jaringan sepenuhnya.
Mencapai network resilience bagi organisasi membutuhkan strategi khusus. Anda dapat menemukan strategi lengkapnya melalui artikel berikut!
Apa itu network resilience?
Network resilience merupakan kemampuan jaringan menjaga operasional secara berkelanjutan dalam kondisi apapun. Dalam konsep ini, jaringan harus tetap berjalan meskipun terjadi gangguan yang di luar dugaan, seperti kegagalan hardware, mati listrik, serangan siber, atau bencana alam.
Oleh karena itu, network resilience tidak hanya berfokus pada kemampuan bertahan saat gangguan terjadi, tetapi juga pada kesiapan dalam mengantisipasinya. Jaringan perlu dirancang untuk mendeteksi potensi risiko sejak dini, meminimalkan dampaknya, serta memulihkan layanan dalam waktu sesingkat mungkin. Dengan pendekatan ini, infrastruktur dibangun di atas fondasi yang kuat dan adaptif, sehingga sistem dapat terus beroperasi secara stabil meskipun menghadapi berbagai tantangan.
Apa yang membedakan network resilience di tahun 2026?
Di tahun 2026, ancaman siber akan semakin canggih dan mampu melumpuhkan operasional dalam hitungan menit. Infrastruktur juga akan semakin terdistribusi, menggabungkan on-premises, private cloud, dan public cloud. Pelanggan juga semakin bergantung pada koneksi, sehingga downtime dalam jangka waktu lama tidak lagi dapat ditoleransi.
Hal ini membuat network resilience tidak dapat lagi berdiri sendiri sebagai inisiatif teknis semata. Mengingat kaitannya dengan aspek lain cukup banyak, organisasi perlu memastikan network resilience terintegrasi dengan strategi keamanan siber, pengalaman pengguna, dan visibilitas di seluruh ekosistem digital.
Pemanfaatan teknologi yang mampu memberikan monitoring real-time, analitik berbasis data, serta automasi dalam deteksi dan respons insiden menjadi semakin krusial. Organisasi tidak cukup hanya bereaksi terhadap gangguan, tetapi mereka juga perlu mengidentifikasi potensi risiko lebih dini, mengisolasi dampaknya dengan cepat, dan mempercepat proses pemulihan.
Lebih dari itu, network resilience kini harus menjadi bagian dari strategi bisnis di level eksekutif. Network resilience harus dijadikan sebagai fondasi keberlangsungan bisnis, bukan hanya sekadar urusan operasional tim IT. Investasi dalam network resilience pun penting untuk organisasi secara keseluruhan.
Mengapa network resilience itu penting?
Network resilience berperan penting karena alasan-alasan berikut ini.
Mempertahankan operasional
Konektivitas jaringan memiliki pengaruh besar dalam keberlangsungan aktivitas bisnis. Bayangkan jika Anda tiba-tiba terputus dari jaringan saat sedang meeting atau mengakses data penting. Tidak hanya menganggu aktivitas, masalah jaringan yang terjadi dalam operasional bisnis juga bisa menimbulkan kerugian finansial. Namun, dengan penerapan strategi network resilience, downtime bisa diminimalkan sehingga sistem tetap stabil dan layanan berjalan tanpa hambatan.
Menjaga keamanan siber
Salah satu dampak dari serangan siber adalah gangguan layanan hingga kelumpuhan sistem. Saat ini terjadi, organisasi harus mampu mengisolasi insiden, membatasi dampaknya, dan memulihkan keadaan ke kondisi normal secepat mungkin. Network resilience memastikan jaringan dirancang dengan mekanisme deteksi, respons, dan pemulihan yang efektif, sehingga serangan tidak berlangsung secara berkepanjangan dan menjadi lebih besar.
Menjaga kepercayaan pelanggan
Bagi pelanggan, tidak ada yang lebih menjengkelkan dari sistem yang sulit diakses atau sering mengalami gangguan. Itulah mengapa, network resilience diperlukan untuk menghadirkan layanan berkelanjutan yang konsisten dan minim interupsi. Dengan menjaga jaringan tetap stabil dan tersedia, pelanggan dapat menggunakan layanan secara leluasa dan meningkatkan kepercayaannya terhadap organisasi.
Memenuhi kebutuhan compliance
Kini, banyak regulasi maupun standar industri yang mewajibkan organisasi untuk menjaga ketersediaan layanan, keamanan sistem, serta integritas data. Network resilience membantu organisasi memenuhi persyaratan tersebut dengan memastikan uptime terjaga, kontrol keamanan diterapkan secara konsisten, dan pemulihan terlaksana dengan cepat.
Redundancy sebagai konsep penting network resilience
Dalam konteks sehari-hari, redundancy sering dianggap sebagai hal yang berlebihan dan tidak efisien. Namun, dalam konteks jaringan, redundancy justru sangat diperlukan. Konsep yang dikenal dengan network redundancy ini berfungsi untuk memastikan jaringan terus beroperasi dalam kondisi apapun, termasuk saat terjadi gangguan.
Redundancy dalam jaringan berarti menyediakan komponen cadangan yang memiliki fungsi serupa dengan komponen utama. Sehingga, ketika komponen utama mengalami gangguan, komponen cadangan dapat mengambil alih tugas komponen utama dan melanjutkan operasional jaringan.
Dengan adanya mekanisme ini, organisasi dapat menghindari single point of failure, yaitu kondisi ketika satu titik kegagalan saja cukup untuk melumpuhkan seluruh jaringan.
Secara umum, terdapat tiga jenis redundancy:
Hardware redundancy: Penggunaan perangkat cadangan seperti server, router, dan switch.
Network path redundancy: Penggunaan lebih dari satu path dalam transmisi data, yaitu logical dan physical path. Fungsinya untuk melakukan rerouting ke path alternatif ketika ada path yang mengalami gangguan.
Power redundancy: Penggunaan sumber daya listrik cadangan seperti UPS dan genset.
Site level redundancy: Penggunaan data center cadangan atau penyimpanan berbasis cloud.
Redundancy tersebut dapat dicapai melalui beberapa mekanisme berikut ini:
High availability
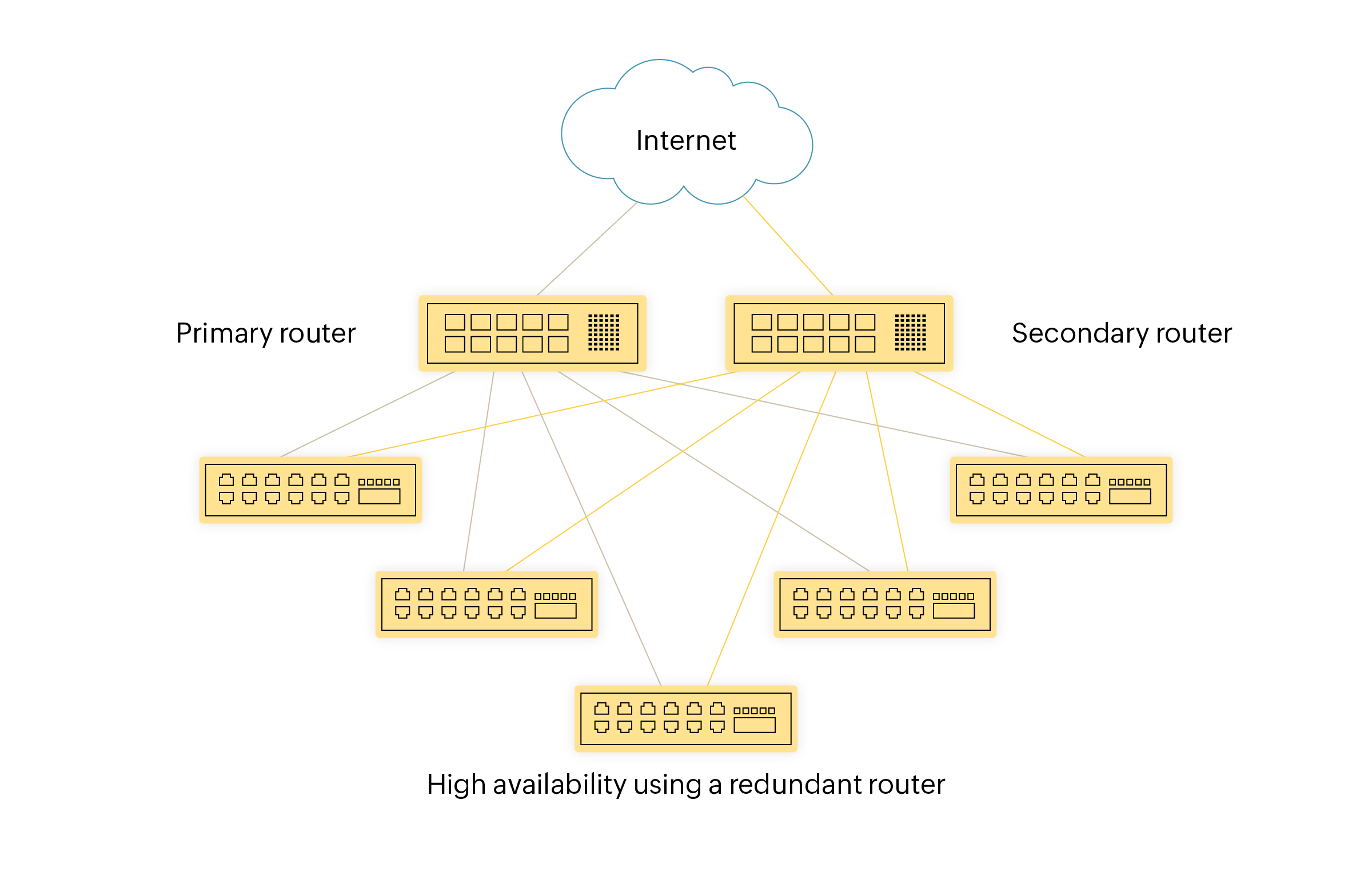
High availability dirancang untuk meminimalkan downtime melalui mekanisme perpindahan otomatis ke sistem sekunder saat terjadi kegagalan di sistem primer. Sistem sekunder kemudian akan mengambil alih operasional secara penuh. Melalui mekanisme ini, organisasi dapat menjaga ketersediaan layanan bahkan hingga 99,9%.
Network replication
Dalam mekanisme ini, seluruh data di sistem primer disalin ke sistem sekunder secara real-time atau berkala. Data di kedua belah sistem harus selalu disinkronkan agar ketika terjadi kegagalan, potensi kehilangan data menjadi sangat kecil.
Fault tolerance
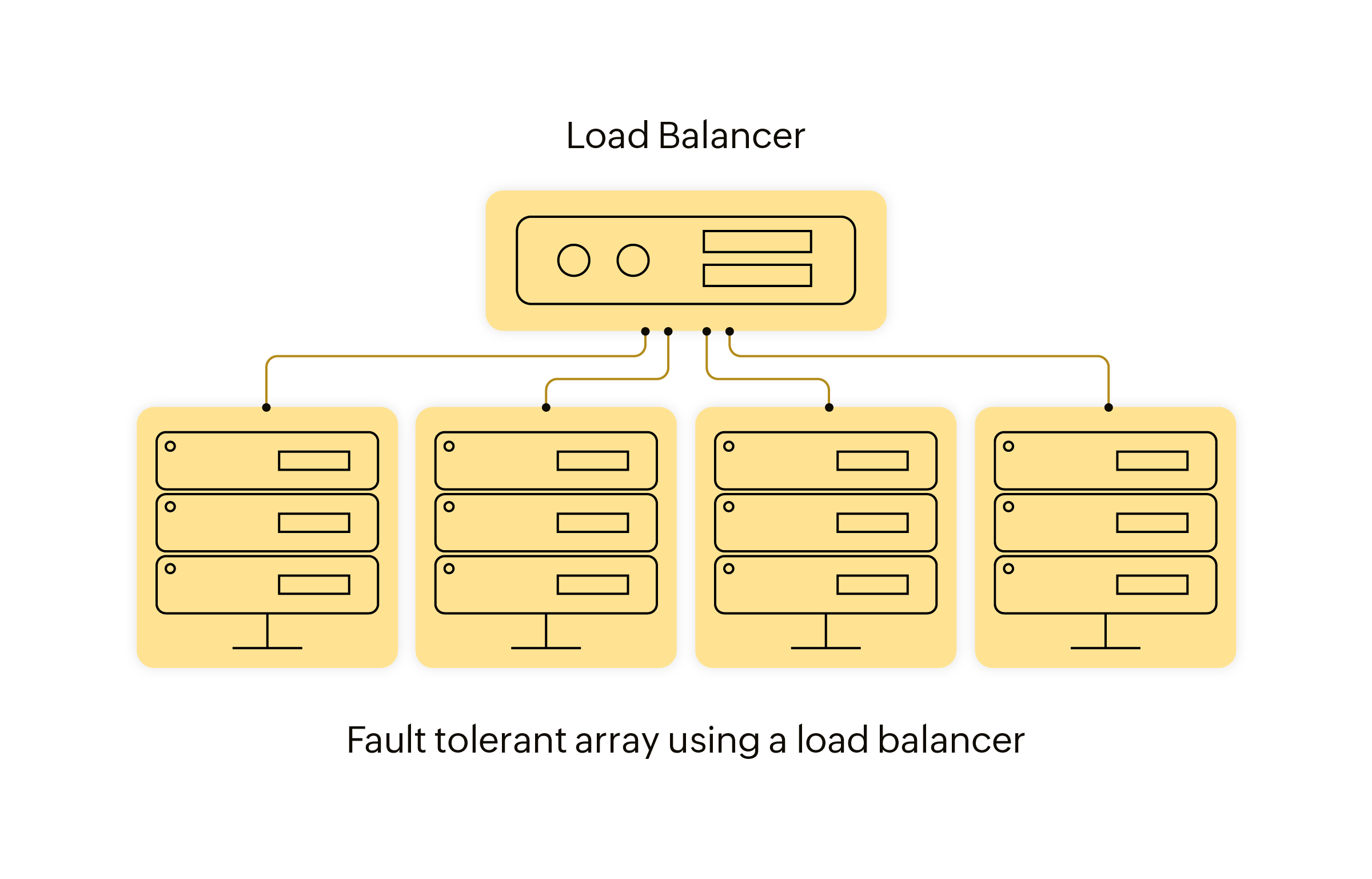
Fault tolerance memungkinkan sistem primer dan sekunder berbagi beban kerja secara bersamaan. Keduanya saling memantau, sehingga ketika salah satu sistem gagal, sistem lain akan langsung menanggung seluruh beban kerja. Proses ini terjadi hampir tanpa jeda, sehingga risiko kehilangan data dapat diminimalkan.
Bagaimana cara memastikan network resilience di organisasi?
Sulit untuk memastikan jaringan tidak terkena downtime atau gangguan sama sekali. Namun, Anda dapat mempersiapkan diri untuk mengurangi risiko gangguan dan memulihkan jaringan lebih cepat dengan langkah-langkah berikut ini.
1. Melakukan audit dan assessment berkala
Audit dan assessment berkala diperlukan untuk mengidentifikasi vulnerability dan point of failure serta memastikan kondisi jaringan secara keseluruhan. Dalam proses ini, seluruh infrastruktur jaringan perlu diperiksa, mulai dari konfigurasi, kontrol akses, hingga potensi celah keamanan.
Dengan begitu, organisasi dapat mengetahui bagaimana kondisi jaringan saat ini. Misalnya, apakah ada software yang belum di-update atau sistem yang belum di-patch? Atau ada konfigurasi yang salah?
Proses ini dapat diotomatisasi menggunakan network audit tool. Melalui otomatisasi, seluruh aktivitas audit dan assessment dapat dilakukan dengan cepat, konsisten, dan menyeluruh.
Network audit tool memiliki beberapa kapabilitas penting untuk menyederhanakan proses audit, seperti:
Asset discovery dan inventory
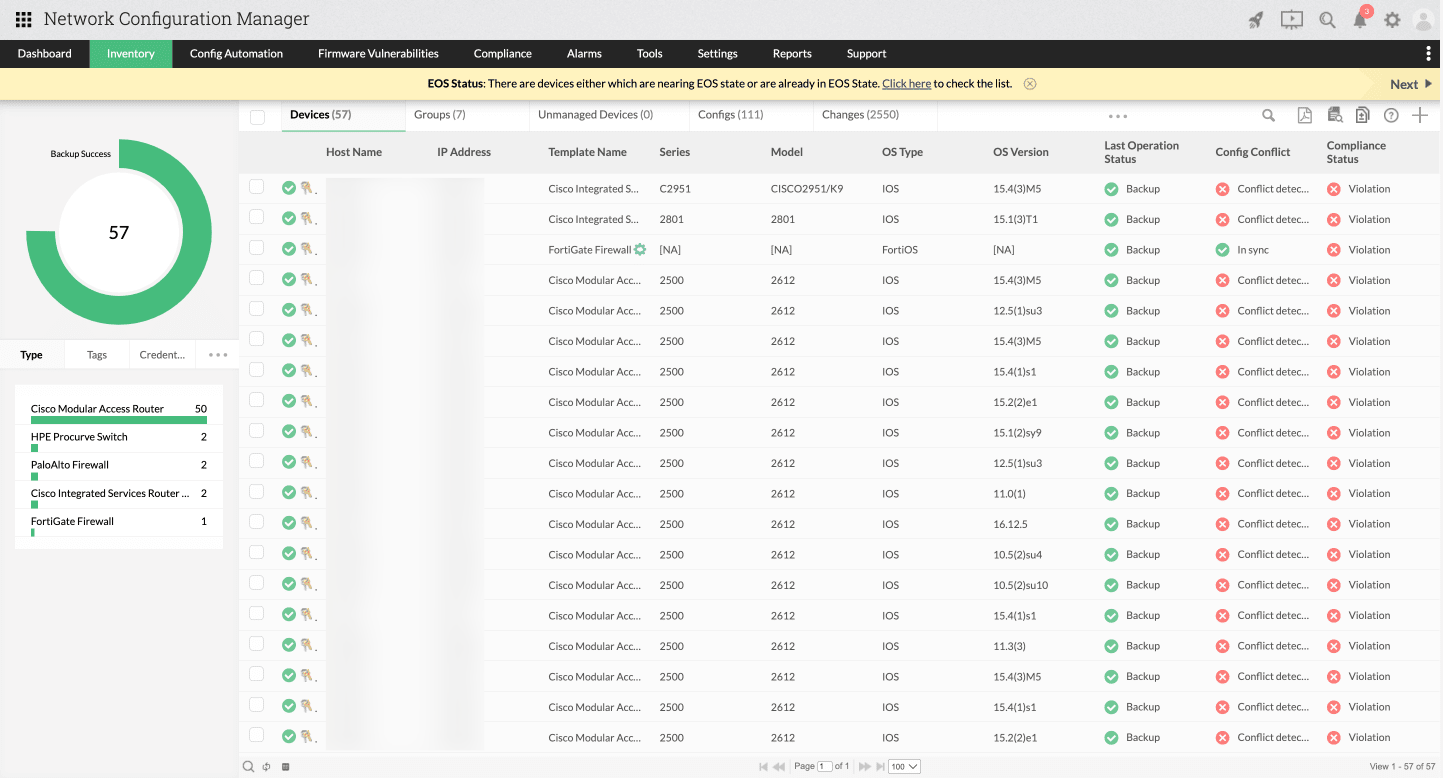
Kapabilitas asset discovery dan inventory dapat menyajikan informasi lengkap tentang perangkat jaringan, termasuk hostname, IP address, status konfigurasi, status compliance, dan status backup. Dengan begitu, tim IT dapat dengan cepat mengidentifikasi perangkat bermasalah atau yang berpotensi menjadi titik risiko dalam jaringan.
Firmware vulnerability management
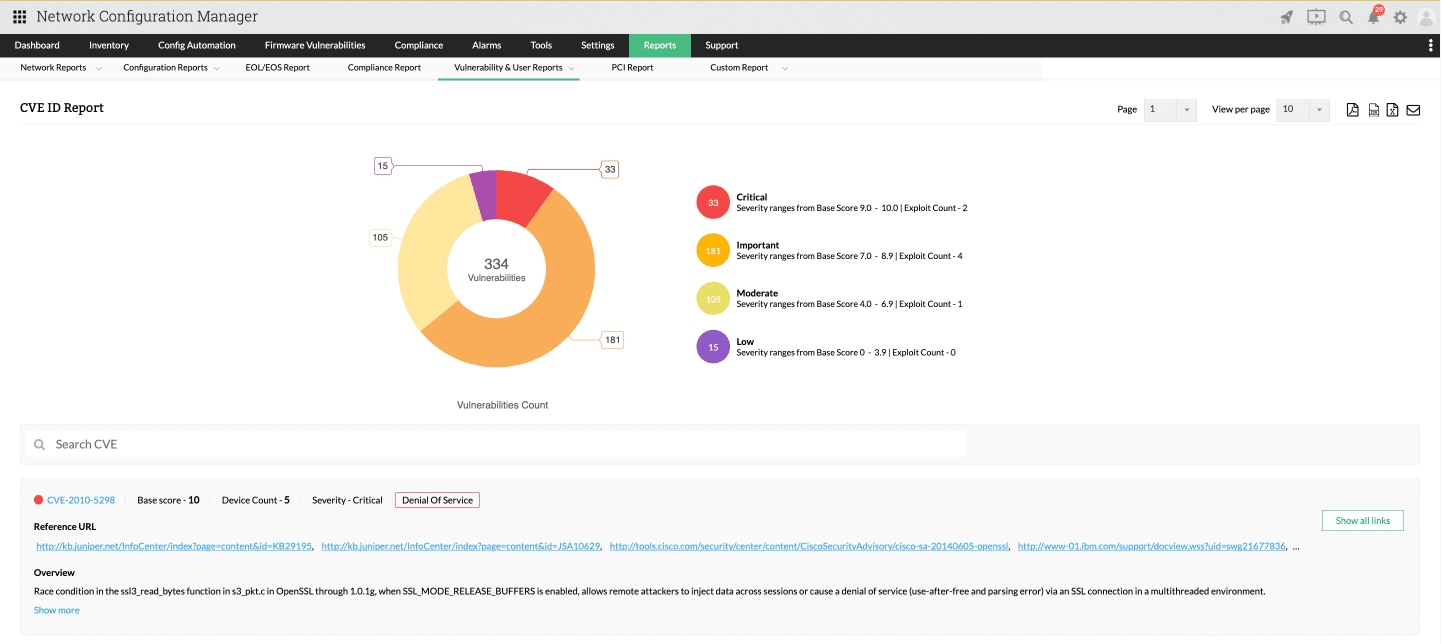
Fitur ini dapat menampilkan daftar perangkat yang lengkap dengan informasi seperti CVE ID, tingkat keparahan (severity level), skor, risiko, serta referensi patch yang tersedia. Melalui informasi ini, tim IT dapat memahami kondisi firewall secara menyeluruh.
Compliance audit
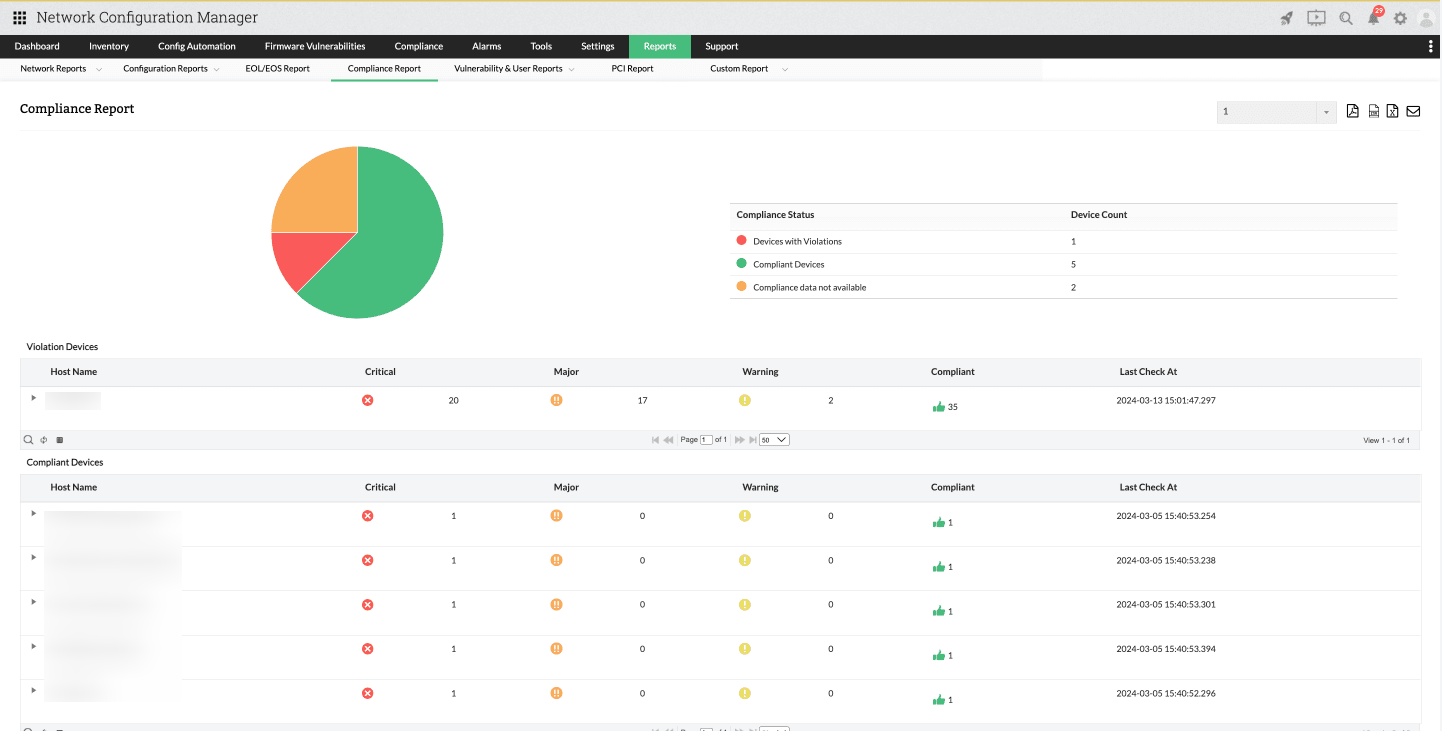
Melalui fitur compliance audit, tim IT dapat melihat apakah infrastruktur jaringan di organisasi sudah memenuhi regulasi atau standar industri tertentu. Pemahaman ini diperoleh dari informasi dalam laporan compliance yang mencakup detail pelanggaran kebijakan, tingkat keparahan, serta aturan spesifik yang dilanggar.
Laporan dan analitik
Audit tidak hanya mengidentifikasi masalah, tetapi juga melaporkannya. Kapabilitas laporan dan analitik berperan dalam memberikan gambaran menyeluruh mengenai kondisi jaringan. Selain itu, laporan juga bertindak sebagai dokumentasi dan sumber insight untuk perancangan strategi network resilience.
2. Melakukan update dan maintenance berkala
Update dan maintenance berkala adalah tahap lanjutan dari audit dan assessment. Aktivitas ini dilakukan untuk mengatasi kekurangan yang teridentifikasi saat audit, misalnya software yang belum di-update atau sistem yang belum di-patch. Tujuannya untuk menutup celah keamanan dalam jaringan.
Namun, terkadang proses update dan maintenance dapat menganggu user dalam mengakses layanan. Tak hanya itu, pemutusan sementara perangkat dari jaringan sering memicu alert yang tidak relevan. Jika dibiarkan, hal ini dapat menyebabkan alert fatigue dan mengaburkan insiden yang benar-benar kritikal.
Untuk mengatasi hal tersebut, organisasi dapat memanfaatkan fitur maintenance atau downtime scheduler dalam solusi monitoring jaringan. Melalui fitur ini, tim IT dapat menjadwalkan periode maintenance pada jam non sibuk. Dengan penjadwalan, perangkat tidak akan dipantau secara aktif dan tidak memicu notifikasi gangguan. User pun bisa mengakses layanan dengan nyaman karena maintenance dijadwalkan di jam sepi.
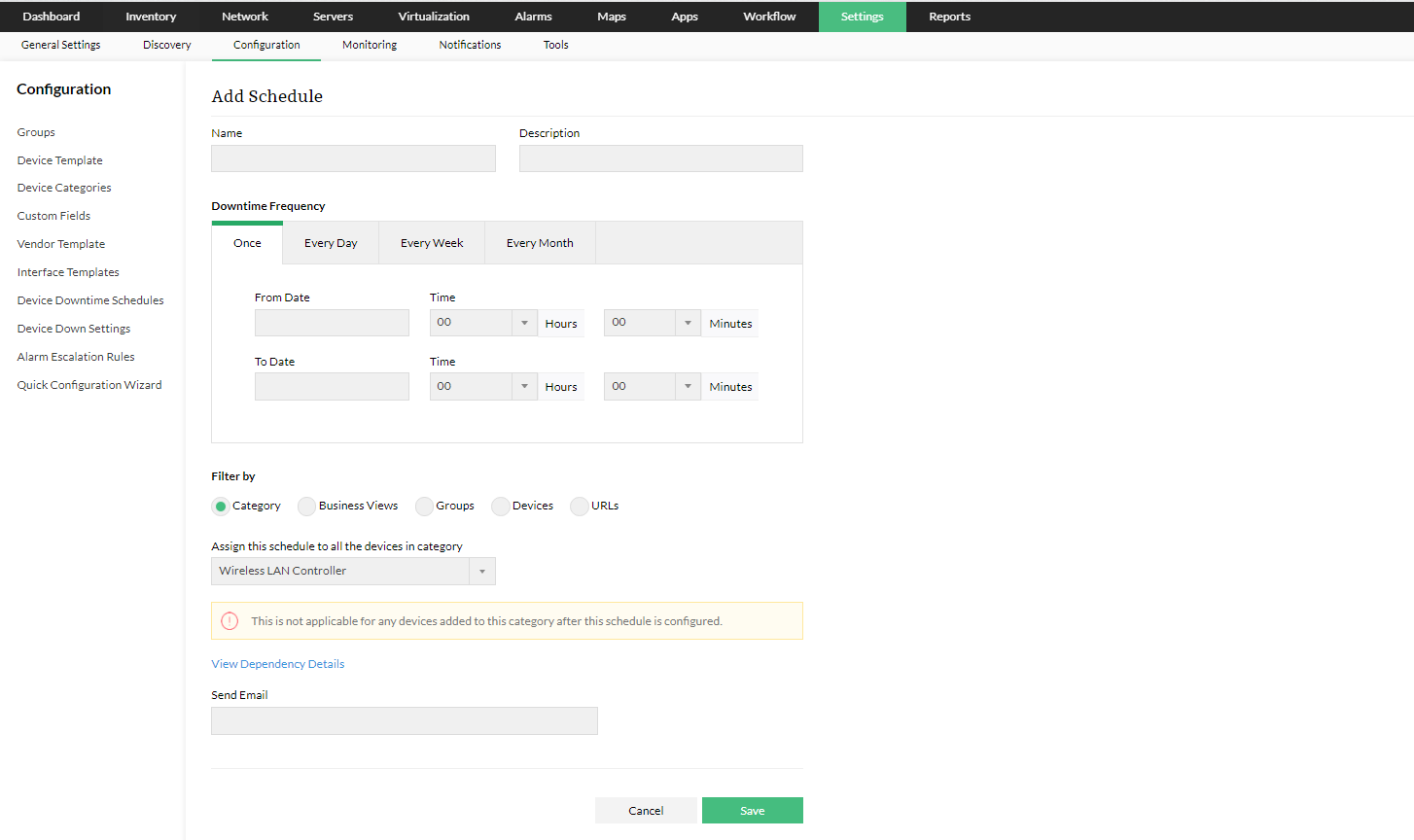
3. Menerapkan redundancy
Dengan menerapkan komponen cadangan di berbagai lapisan infrastruktur, organisasi dapat meminimalkan gangguan dan memastikan operasional tetap berjalan meskipun terjadi kegagalan pada salah satu bagian sistem.
Redundancy dapat diwujudkan melalui penggunaan prosesor cadangan, sistem operasi, backup data, penerapan perangkat cadangan, konfigurasi failover, data center cadangan, dan penyimpanan berbasis cloud. Melalui serangkaian strategi redundancy ini, organisasi dapat mengurangi risiko downtime dan membangun infrastruktur yang tangguh.
4. Melakukan monitoring berkelanjutan
Monitoring real-time berkelanjutan penting untuk memantau apa yang terjadi di jaringan. Sehingga, ketika ada gangguan, tim IT dapat mendeteksi dan memitigasinya dengan cepat.
Tool network monitoring dapat membantu tugas ini dengan berbagai kapabilitas berikut:
Hybrid environment monitoring
Di lingkungan hybrid, penggunaan satu tool monitoring untuk setiap jenis infrastruktur tidak efektif. Namun, dengan kapabilitas hybrid environment monitoring, Anda dapat memantau VMware, Hyper-V, Hypervisors, Cisco UCS, Nutanix dari satu konsol terpadu.
Network interface monitoring
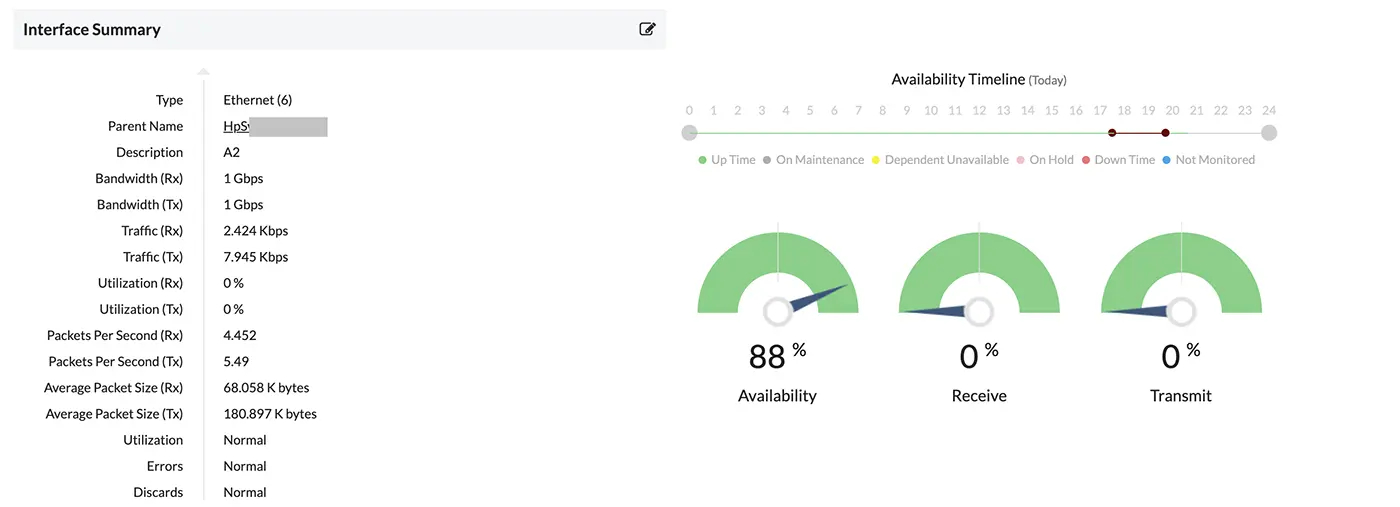
Melalui monitoring network interface, tim IT dapat memantau interface menggunakan SNMP dan mengidentifikasi penurunan performa jaringan sejak dini. Pemantauan interface ini dilakukan dengan memeriksa status ketersediaannya, serta mengawasi kecepatan trafik, error, discard, dan metrik lainnya pada setiap interface. Hasil pemantauan bisa dilihat di dashboard yang dapat dikustomisasi.
Switch/router monitoring
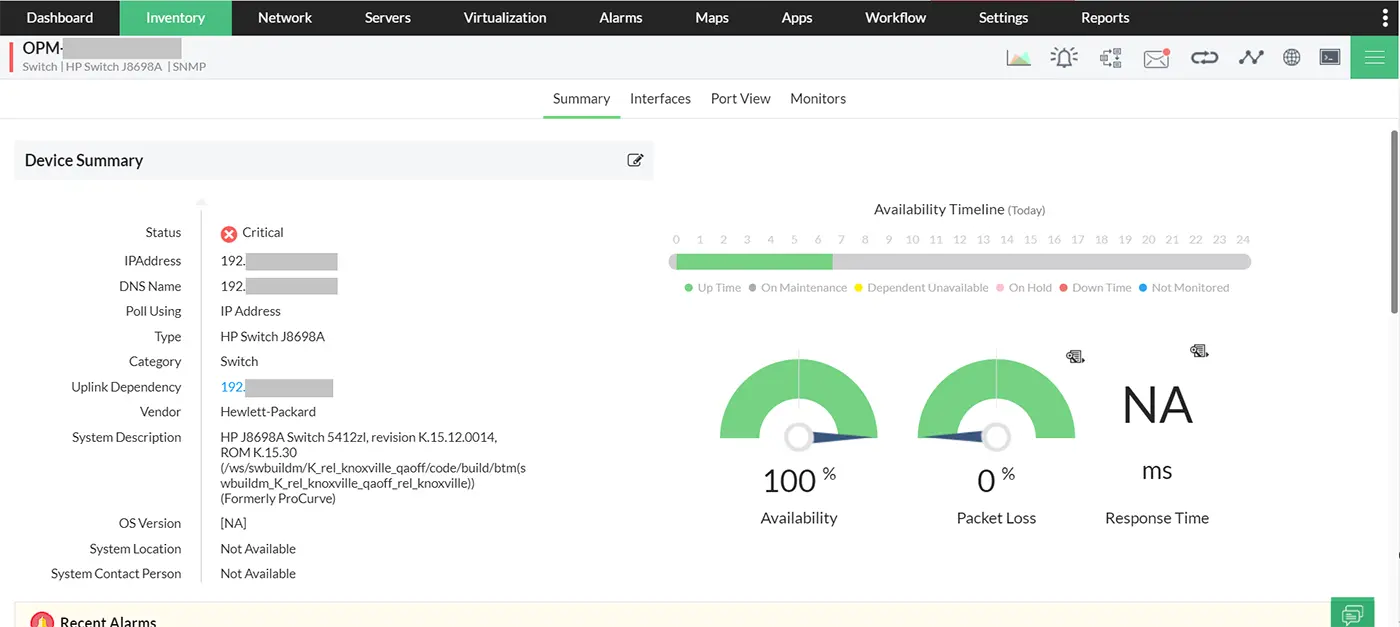
Switch dan router merupakan fondasi dari infrastruktur IT. Itulah mengapa, pemantauan availability, health, serta performa switch dan router menjadi sangat penting. Dengan pemantauan ini, Anda dapat memahami kondisi switch dan router seperti Cisco, Juniper, Aruba, dan ZTE serta menghindari adanya gangguan jaringan.
5. Merancang incident response plan
Incident response plan berisi langkah-langkah terstruktur dalam mengidentifikasi, merespons, dan memulihkan jaringan dari insiden. Tujuannya agar tim IT dapat bergerak dan menangani insiden lebih cepat, sehingga dampaknya terhadap jaringan tidak semakin meluas.
Incident response plan juga perlu diuji untuk menentukan relevansi dan efektivitasnya. Tim IT perlu melakukan simulasi berbagai skenario insiden dan menerapkan langkah-langkah dalam rencana untuk mengidentifikasi area yang perlu diperbaiki dan memahami efektivitas rencana tersebut.
Proses ini cukup panjang, sehingga tool incident response dengan kapabilitas berikut sangat diperlukan:
ML-based UEBA
Kapabilitas ini dapat menganalisis log dari berbagai sumber dan mendeteksi anomali dalam jaringan berdasarkan baseline yang sudah ditentukan sebelumnya. Anomali diidentifikasi dari berbagai perangkat seperti database, router, firewall, server, dan lainnya.
Incident overview dashboard
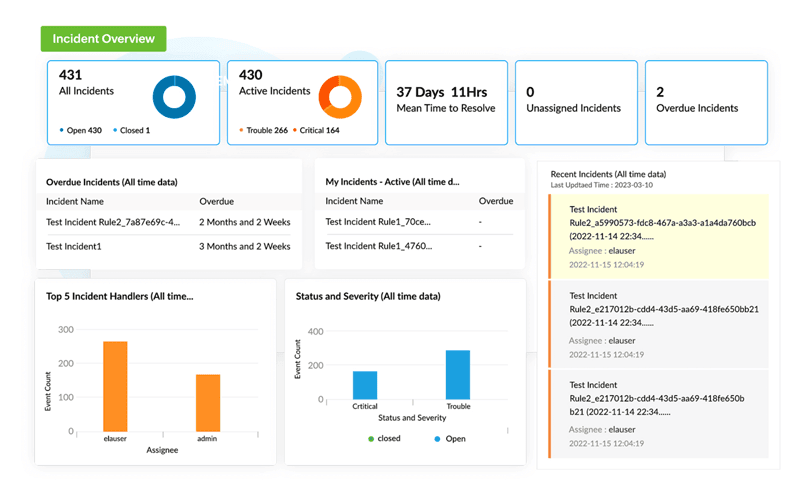
Tim IT membutuhkan dashboard insiden yang melacak metrik penting seperti mean time to detect (MTTD) dan mean time to respond (MTTR), insiden yang sedang aktif dan belum diselesaikan, serta insiden terbaru. Informasi ini diperlukan untuk triage dan prioritisasi resolusi insiden yang paling kritikal.
Real-time alert system
Ketika ancaman terdeteksi dalam jaringan, alert akan muncul. Alert ini dikategorikan menjadi tiga tingkat keparahan, sehingga tim IT dapat memprioritaskan dan mengatasi ancaman yang paling kritikal terlebih dahulu.
Automated incident workflow
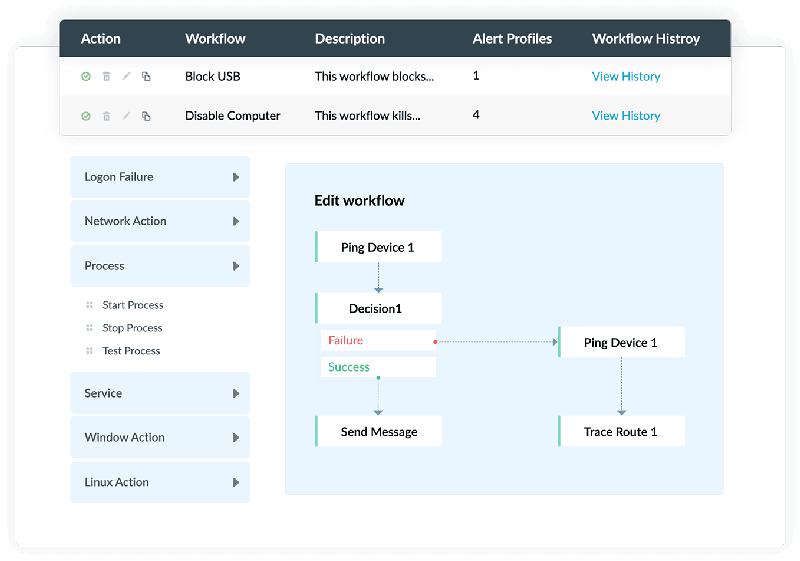
Kapabilitas ini memungkinkan tim IT untuk menetapkan workflow respons insiden yang akan dijalankan secara otomatis ketika terjadi insiden. Workflow ini dapat memicu pemblokiran port USB, modifikasi firewall rule, penonaktifan akun user yang terkena serangan, serta penghentian proses dan layanan yang berjalan di perangkat terdampak.
6. Merancang backup dan recovery plan
Dalam konteks network resilience, backup dan recovery plan penting untuk memastikan keberlanjutan operasional setelah insiden terjadi. Biasanya, ada dua hal yang perlu dicadangkan, yaitu konfigurasi jaringan dan data dalam storage.
Konfigurasi jaringan perlu dicadangkan karena satu organisasi bisa memiliki ratusan hingga ribuan perangkat dengan konfigurasi yang berbeda-beda. Jika tidak ada backup untuk hal ini, tim IT akan kesulitan mengembalikan operasional dan performa jaringan ke kondisi semula, sebab kini konfigurasi yang ada hanyalah konfigurasi dasar. Sementara itu, data dalam storage perlu dicadangkan untuk memastikan semua informasi penting organisasi tetap tersedia bahkan setelah gangguan terjadi.
Setelah melakukan backup, langkah penting lainnya adalah menguji backup secara berkala. Pengujian ini dapat dilakukan saat periode maintenance untuk memastikan data benar-benar tersimpan dan dapat dipulihkan.
Tak lupa, penyimpanan backup pun juga harus diperhatikan. Backup dapat disimpan di lokasi terpisah atau remote data center untuk menghindari risiko kehilangan akibat kebakaran atau bencana alam. Penggunaan enkripsi juga penting agar data backup terlindungi dari breach.
Bangun network resilience sebelum gangguan terjadi
Network resilience bukan hanya tentang menjaga jaringan tetap aktif, tetapi tentang memastikan operasional bisnis tetap berjalan dalam berbagai situasi, mulai dari gangguan kecil hingga insiden besar. Melalui audit dan assessment yang rutin, maintenance terjadwal, perencanaan backup dan recovery yang matang, serta penerapan redundancy di berbagai level, organisasi dapat meminimalkan downtime sekaligus mempercepat proses pemulihan.
Dengan dukungan solusi monitoring dan manajemen jaringan yang terintegrasi seperti yang ditawarkan oleh ManageEngine, organisasi dapat memperoleh visibilitas menyeluruh, kontrol konfigurasi yang lebih baik, serta kemampuan pemulihan yang lebih cepat dan terstruktur.
Pelajari bagaimana solusi ITOM dari ManageEngine dapat membantu organisasi Anda membangun jaringan yang lebih tangguh, stabil, dan siap menghadapi berbagai tantangan operasional!