Web Scraping คืออะไร? ตัวช่วยที่มอบข้อได้เปรียบด้านข้อมูลให้องค์กร
ในยุคที่ข้อมูลเปรียบเสมือนขุมทรัพย์มหาศาลบนโลกอินเทอร์เน็ต การรอให้ข้อมูลเดินเข้ามาหาเองคงไม่ทันการณ์สำหรับธุรกิจยุคใหม่ เทคโนโลยี Web Scraping จึงก้าวเข้ามามีบทบาทสำคัญในฐานะเครื่องมือทรงพลังที่ช่วยให้เราสามารถเข้าถึงและดึงข้อมูลจากเว็บไซต์ต่างๆ มาใช้งานได้อย่างรวดเร็ว ไม่ว่าจะเป็นการเช็กราคาสคู่แข่งหรือการวิเคราะห์เทรนด์ตลาด บทความนี้จะพาคุณไปทำความรู้จักกับโลกของ Data Scraping คืออะไร มีกระบวนการอย่างไร และทำไมธุรกิจยุคนี้ถึงขาดมันไม่ได้
Web Scraping คืออะไร? ทำความเข้าใจกลไกการดึงข้อมูลอัจฉริยะ
ก่อนจะไปดูวิธีการใช้งาน เรามาทำความเข้าใจกันก่อนว่า Web Scraping คือ เทคนิคการดึงข้อมูลจากหน้าเว็บไซต์ เพื่อนำมาใช้ประโยชน์ในการวิเคราะห์ Insight และต่อยอดกิจกรรมทางธุรกิจต่างๆ เช่น การวางกลยุทธ์กระตุ้นยอดขายผ่านการวิเคราะห์คู่แข่ง หรือการรวบรวมข้อมูลดิบมาทำนายทิศทางตลาดในอนาคต
โดยพื้นฐานแล้ว กระบวนการของ Scraping Data คือ การใช้โปรแกรมคอมพิวเตอร์หรือบอทเข้าไปที่เว็บไซต์เป้าหมายเพื่อเก็บ Raw Data กลับมา จากนั้นระบบจะทำการคัดเลือกเฉพาะข้อมูลที่ต้องการ นำมาทำ Data Cleaning และจัดเก็บลงในรูปแบบที่พร้อมใช้งานทันที เช่น ไฟล์ Excel, CSV หรือจัดลง Database หากแปลตามตัวอักษรคำว่า "Scraping" หมายถึงการขูด ซึ่งในบริบทไอทีก็เปรียบได้กับการ "ขูด" หรือแงะข้อมูลที่แสดงผลอยู่บนหน้าเว็บออกมาเพื่อแปรรูปเป็นมูลค่าทางธุรกิจนั่นเอง
วิธีการทำ Web Scraping มีอะไรบ้าง?
ในการเริ่มต้นทำ Web Scraping นั้นมีทางเลือกหลากหลาย ตั้งแต่วิธีที่ทำได้ด้วยตัวเองไปจนถึงการใช้ระบบอัตโนมัติขั้นสูง โดยเราสามารถแบ่งเทคนิคหลักๆ ออกเป็น 3 รูปแบบตามความเหมาะสมของทรัพยากรและขนาดของข้อมูลดังนี้:
Copy/Paste ข้อมูลแบบ Manual
วิธีนี้คือการทำ Scraping Data รูปแบบดั้งเดิมที่สุด โดยให้เจ้าหน้าที่ไอทีหรือพนักงานไล่คัดลอกข้อมูลจากหน้าเว็บแล้วนำมาวางในตารางด้วยตัวเอง ข้อดีคือไม่ต้องลงทุนด้านซอฟต์แวร์เพิ่ม แต่มีข้อเสียร้ายแรงคือใช้เวลานานมาก เสี่ยงต่อ Human Error และไม่สามารถรองรับการวิเคราะห์ข้อมูลขนาดใหญ่ได้
เขียนโปรแกรม Web Scraping เพื่อดึงข้อมูล
นี่คือวิธีที่ได้รับความนิยมสูงสุดในหมู่เหล่านักพัฒนา เพราะให้ความยืดหยุ่นและแม่นยำสูง โดยมีการใช้ภาษาคอมพิวเตอร์ที่หลากหลาย เช่น:
- Python: ใช้ Library ยอดฮิตอย่าง BeautifulSoup สำหรับดึงข้อมูลจาก HTML, Scrapy สำหรับสร้าง Web Crawler ขนาดใหญ่ หรือ Selenium เพื่อควบคุมเบราว์เซอร์ในเว็บที่มีความซับซ้อน
- Node.JS: เหมาะกับสาย JavaScript โดยมี Puppeteer ในการคุม Chrome แบบ Headless หรือ Cheerio ที่เน้นความรวดเร็วในการจัดการโครงสร้าง HTML
- ภาษาอื่นๆ: ไม่ว่าจะเป็น Ruby, PHP หรือ C++ ก็สามารถประยุกต์ใช้เพื่อสร้างระบบดึงข้อมูลเฉพาะตัวได้เช่นกัน
ใช้เครื่องมือ Web Scraping สำเร็จรูป
สำหรับองค์กรที่เน้นความรวดเร็วและไม่อยากเสียเวลาเขียนโค้ด การเลือกใช้ Web Scraping Tools หรือ Website Scraper สำเร็จรูปคือคำตอบที่ตรงโจทย์ที่สุด เช่น การใช้ RPA (Robotic Process Automation) หรือเครื่องมือเฉพาะทางอย่าง Webscraper.io, Octoparse และ ParseHub นอกจากนี้ยังมี Browser Extension ง่ายๆ อย่าง Data Miner ที่ช่วยให้การดึงข้อมูลเป็นเรื่องง่ายเพียงไม่กี่คลิก แม้จะปรับแต่งได้ไม่เท่าการเขียนโค้ดเอง แต่ก็แลกมาด้วยความสะดวกและ Interface ที่เป็นมิตรกับผู้ใช้
Web Scraper ทำงานอย่างไร?
หลักการทำงานของ Web Scraper นั้นเปรียบเสมือนการส่งหุ่นยนต์นักอ่าน เข้าไปสำรวจเว็บไซต์แทนมนุษย์ โดยเราสามารถสั่งให้มันดึงข้อมูลทั้งหมดหรือเฉพาะส่วนที่สนใจก็ได้ เช่น หากคุณต้องการสำรวจราคาสินค้าบน Amazon คุณอาจสั่งให้ Website Scraper ดึงเพียง ชื่อรุ่น และ ราคา โดยไม่ต้องเอารีวิวลูกค้ามาให้หนักเครื่อง
เพื่อให้เห็นภาพชัดเจน นี่คือขั้นตอนการทำงานแบบ End-to-End:
- Input: ระบุ URL เป้าหมายและข้อมูลที่ต้องการ
- Request: สแครปเปอร์จะส่งคำขอ HTTP GET ไปยังเว็บไซต์เสมือนมีคนเปิดเบราว์เซอร์เข้าชม
- Load: ดาวน์โหลด HTML และรัน JavaScript (ถ้ามี) เพื่อแสดงผลข้อมูล
- Parse: เปลี่ยน Code HTML ให้เป็นโครงสร้างที่คอมพิวเตอร์ค้นหาได้ (Navigable Structure)
- Extract: ค้นหาข้อมูลเป้าหมายด้วย Selector หรือ XPath
- Clean: ตัดส่วนที่ไม่เกี่ยวข้องและจัดระเบียบข้อมูลให้เป็นระเบียบ
- การจัดการหน้าถัดไป: สั่งให้บอทคลิกหน้าถัดไปเพื่อเก็บข้อมูลจนครบ
- Save: ส่งออกข้อมูลที่พร้อมใช้ในรูปแบบ CSV, JSON หรือ Excel
ประเภทของ Web Scrapers
เราสามารถจำแนกประเภทของ Web Scraper ได้หลากหลายรูปแบบตามลักษณะการใช้งานและสภาพแวดล้อมที่ระบบทำงานอยู่ เพื่อให้คุณเลือกใช้ได้ตรงกับความต้องการขององค์กรมากที่สุด
แบ่งตามรูปแบบการพัฒนา
- แบบสร้างเอง (Self-built): พัฒนาขึ้นมาใหม่ด้วย Python หรือ JS ให้ความยืดหยุ่นสูงสุดแต่ต้องใช้ทักษะการเขียนโค้ดขั้นสูง
- แบบสำเร็จรูป (Pre-built): ซอฟต์แวร์ที่ติดตั้งแล้วใช้งานได้ทันที เหมาะสำหรับผู้ที่ไม่มีพื้นฐานการเขียนโค้ดแต่ต้องการความเร็ว
แบ่งตามแพลตฟอร์ม
- Browser Extension: ติดตั้งเป็นส่วนขยายบน Chrome หรือ Firefox ใช้ง่ายแต่ไม่เหมาะกับงานสเกลใหญ่
- Software Web Scrapers: แอปพลิเคชันแยกต่างหากบนคอมพิวเตอร์ มีฟีเจอร์ครบครันและรองรับงานที่ซับซ้อนได้มากกว่า
แบ่งตามสภาพแวดล้อมในการทำงาน
- Cloud Web Scrapers: รันบนเซิร์ฟเวอร์ของผู้ให้บริการ ไม่กินทรัพยากรเครื่องเราและทำงานแบบ Multitasking ได้ดีเยี่ยม
- Local Web Scrapers: รันบนคอมพิวเตอร์ของคุณเองโดยใช้ CPU และ RAM ในเครื่อง ซึ่งอาจทำให้เครื่องช้าลงขณะประมวลผลข้อมูลหนักๆ
ข้อดีของ Web Scraping ที่องค์กรควรรู้
การเลือกใช้ Web Scraping Tools เข้ามาช่วยงาน ไม่เพียงแต่จะเพิ่มความสะดวสบาย แต่ยังมีข้อดีอีกหลายมิติที่ช่วยเพิ่มประสิทธิภาพการทำงานให้ก้าวกระโดด
- ประสิทธิภาพและความเร็ว: สามารถดึงข้อมูลหลักพันหน้าได้ในไม่กี่นาที และตั้งเวลาทำงานอัตโนมัติได้ 24/7
- ความแม่นยำสูง: ลดปัญหาความผิดพลาดจากการพิมพ์ข้อมูลผิดของมนุษย์ และได้รูปแบบข้อมูลที่สม่ำเสมอพร้อมวิเคราะห์
- ความยืดหยุ่น: สามารถปรับแต่งให้เก็บเฉพาะข้อมูลที่สำคัญจริงๆ และขยายขนาด (Scalability) ได้ตามการเติบโตของธุรกิจ
- ประยุกต์ประหยัดต้นทุน: ลดการจ้างแรงงานคนในการเก็บข้อมูล และเป็นการลงทุนครั้งเดียวที่ใช้งานซ้ำได้ในระยะยาว
การประยุกต์ใช้งาน Web Scraping ในธุรกิจ
ในโลกธุรกิจจริง Data Scraping คือ กุญแจสำคัญในการสร้างความได้เปรียบทางการแข่งขัน โดยมีการประยุกต์ใช้ในหลากหลายอุตสาหกรรม ดังนี้:
- การวิเคราะห์ราคา: การติดตามราคาคู่แข่งบนอีคอมเมิร์ซเพื่อทำ Dynamic Pricing หรือการปรับราคาสินค้าแบบเรียลไทม์
- Market Research: ติดตามเทรนด์สินค้าที่กำลังมาแรงและพฤติกรรมผู้บริโภคตามฤดูกาล
- ข้อมูลทางเลือก: สแครปข้อมูลจากสำนักงานคณะกรรมการกำกับหลักทรัพย์และตลาดหลักทรัพย์ (ก.ล.ต.) หรือข่าวเศรษฐกิจเพื่อนำมาวิเคราะห์ทิศทางการลงทุน
- อสังหาริมทรัพย์: ตรวจสอบราคาประเมินที่ดินย้อนหลังและเปรียบเทียบประกาศขายในหลายๆ เว็บไซต์
- B2B Lead Generation: การเข้าถึงกลุ่มเป้าหมายที่ตรงจุดและรวดเร็วคือกุญแจสำคัญสู่ความสำเร็จในโลกของธุรกิจ B2B ตัวอย่างที่เห็นได้ชัด คือเมื่อทีมขายต้องการมุ่งเป้าไปที่กลุ่มผู้ประกอบการใหม่ การใช้เครื่องมือประเภท Scraper มีบทบาทสำคัญในการสแกน Store Directories เพื่อรวบรวมข้อมูล ไม่ว่าจะเป็นที่อยู่อีเมล ชื่อโดเมน ไปจนถึงหน้าติดต่อสอบถาม โดยข้อมูลเหล่านี้จะถูกส่งต่อเข้าสู่ระบบ CRM โดยตรง เพื่อสร้างโอกาสทางธุรกิจได้อย่างแม่นยำ
- Brand Monitoring: ติดตามรีวิวหรือข่าวเชิงลบเพื่อเข้าไปแก้ไขสถานการณ์ได้ทันท่วงที
- Business Automation: รวบรวมข้อมูลยอดขายและสถิติต่างๆ มาไว้ใน Dashboard เดียวเพื่อประสิทธิภาพในการบริหาร
ข้อควรปฏิบัติในการทำ Web Scraping
แม้ว่าจะเป็นเครื่องมือที่ทรงพลัง แต่การทำ Data Scraping คือ กิจกรรมที่มีความละเอียดอ่อน ซึ่งผู้ใช้งานต้องตระหนักถึงข้อจำกัดและข้อควรระวังสำคัญหลายประการ อย่าลืมว่าการรวบรวมข้อมูลจากเว็บไซต์ไม่ใช่เพียงแค่เรื่องของเทคนิค แต่ยังรวมถึงการเคารพกฎเกณฑ์และความปลอดภัยของระบบต้นทาง เพื่อให้การทำงานราบรื่นและยั่งยืน นี่คือข้อควรปฏิบัติที่เหล่านักพัฒนาและองค์กรควรยึดถือ:
แนวทางการเข้าถึงข้อมูลอย่างถูกวิธีและปลอดภัย
ก่อนที่เครื่องมือของคุณจะเริ่มทำงาน การวางรากฐานด้านความเคารพต่อกฎเกณฑ์ของเว็บไซต์เป้าหมายเป็นสิ่งสำคัญอันดับแรก เพื่อป้องกันความเสี่ยงที่อาจส่งผลกระทบต่อทั้งตัวผู้ดึงข้อมูลและเจ้าของเว็บไซต์
- ทำตามข้อกำหนด Robots.txt: ก่อนเริ่มออกแบบโครงสร้างการดึงข้อมูล ขั้นตอนแรกที่ต้องทำคือตรวจสอบไฟล์ robots.txt ซึ่งเป็นไฟล์ที่เจ้าของเว็บไซต์ใช้กำหนดแนวทางให้แก่ Robot หรือ Crawler ของ Search Engine ว่าส่วนใดที่อนุญาตหรือไม่อนุญาตให้จัดเก็บข้อมูล โดยปกติไฟล์นี้จะอยู่ในส่วน Admin Section ซึ่งระบุข้อกำหนดต่างๆ เช่น การห้ามเข้าถึงลิงก์สำหรับดาวน์โหลดข้อมูลสำคัญ หรือการกำหนด Frequency Interval หากเว็บไซต์ระบุชัดเจนว่าไม่อนุญาต เราควรปฏิบัติตามอย่างเคร่งครัดเพื่อป้องกันปัญหาทางกฎหมายที่ร้ายแรง
- ปรับความถี่ในการส่งคำขอให้เหมาะสม: เซิร์ฟเวอร์แต่ละแห่งมีขีดความสามารถในการรองรับ Load ที่ต่างกัน การส่งคำขอเข้าไปอย่างต่อเนื่องในเวลาอันสั้นจะทำให้เกิด Traffic มหาศาล ซึ่งอาจส่งผลให้เซิร์ฟเวอร์ล่มหรือทำงานช้าลง จนกระทั่งกระทบต่อ User Experience ของผู้ใช้งานทั่วไป ดังนั้นควรหน่วงเวลาการส่งคำขอตามที่ระบุไว้ใน robots.txt หรือใช้มาตรฐานการหน่วงเวลาประมาณ 10 วินาที เพื่อลดโอกาสที่บอทจะถูก Block
การบริหารจัดการเวลาและความรับผิดชอบต่อข้อมูล
ความสำเร็จของการดึงข้อมูลไม่ได้อยู่ที่ปริมาณข้อมูลที่ได้เพียงอย่างเดียว แต่อยู่ที่การจัดการทรัพยากรอย่างเห็นคุณค่าและความโปร่งใสในการดำเนินงาน
- ดึงข้อมูลในช่วงเวลาที่มีการใช้งานต่ำ: ช่วงเวลา Off-peak ที่ Traffic ของเว็บไซต์เบาบางลงเป็นเวลาที่เหมาะสมที่สุดสำหรับ Crawler เพราะช่วยให้ดึงข้อมูลได้เร็วขึ้นและลดภาระส่วนเกินของเซิร์ฟเวอร์ โดยพิจารณาช่วงเวลาจาก Geolocation ของกลุ่มผู้ใช้งานหลักของเว็บไซต์นั้นๆ
- การใช้ข้อมูลอย่างมีความรับผิดชอบ: เราต้องตระหนักถึงความรับผิดชอบในการนำข้อมูลมาใช้งาน การนำข้อมูลไปเผยแพร่ซ้ำโดยไม่ได้รับอนุญาตอาจถือเป็นการละเมิด Copyright Laws ดังนั้นควรตรวจสอบหน้า Terms of Service ของเว็บไซต์เป้าหมายให้รอบคอบก่อนเริ่มดำเนินการ
- สังเกตค่า Canonical URLs: ในหนึ่งเว็บไซต์อาจมีหลาย URL ที่นำไปสู่ข้อมูลชุดเดียวกัน ซึ่งอาจทำให้เกิดข้อมูลซ้ำซ้อน การสังเกตค่า Canonical URL ที่ระบุถึงต้นฉบับจะช่วยให้เราดึงเฉพาะข้อมูลที่จำเป็นและสะอาดที่สุด โดยเฟรมเวิร์กอย่าง Scrapy มักจะมีระบบจัดการ URL ที่ซ้ำซ้อนมาให้โดยอัตโนมัติอยู่แล้ว
- ความโปร่งใสในการข้าถึงแหล่งข้อมูล: ดำเนินการอย่างโปร่งใส ไม่บิดเบือนวัตถุประสงค์ในการเข้าถึงข้อมูล หากคุณมี Username และ Password ที่ได้รับอนุญาตให้เข้าถึงแหล่งข้อมูล หลายๆ เว็บไซต์มีการใช้ Web Filter เพื่อกำหนดสิทธิ์และคัดกรองแหล่งข้อมูลที่ระบบสามารถเข้าถึงได้ ดังนั้นจึงควรใช้งานอย่างเปิดเผยและระบุตัวตนหรือช่องทางติดต่อสื่อสารให้ชัดเจนหากเป็นไปได้
ใช้ Web Scrapping อย่างปลอดภัย ปกป้องโครงสร้างพื้นฐาน IT ด้วย Intelligent Firewall Management
ในขณะที่ Web Scraping ช่วยให้ธุรกิจเข้าถึงข้อมูลจำนวนมหาศาลได้อย่างรวดเร็ว การควบคุมและตรวจสอบการไหลของข้อมูลบนเครือข่ายก็เป็นอีกหนึ่งปัจจัยสำคัญที่ไม่ควรมองข้าม โดยเฉพาะในองค์กรที่มีการใช้งานระบบอัตโนมัติหรือมีการส่ง Request จำนวนมากอย่างต่อเนื่อง
เครื่องมืออย่าง ManageEngine Firewall Analyzer ถูกออกแบบมาเพื่อช่วยให้องค์กรสามารถมองเห็นภาพรวมของการใช้งาน Firewall ได้อย่างชัดเจน ผ่านการวิเคราะห์ Log และ Traffic แบบละเอียด รวมถึงสามารถจัดการ Firewall จากหลากหลาย Vendor ได้ในที่เดียว
ความสามารถหลักที่สอดคล้องกับการใช้งานจริง ได้แก่:
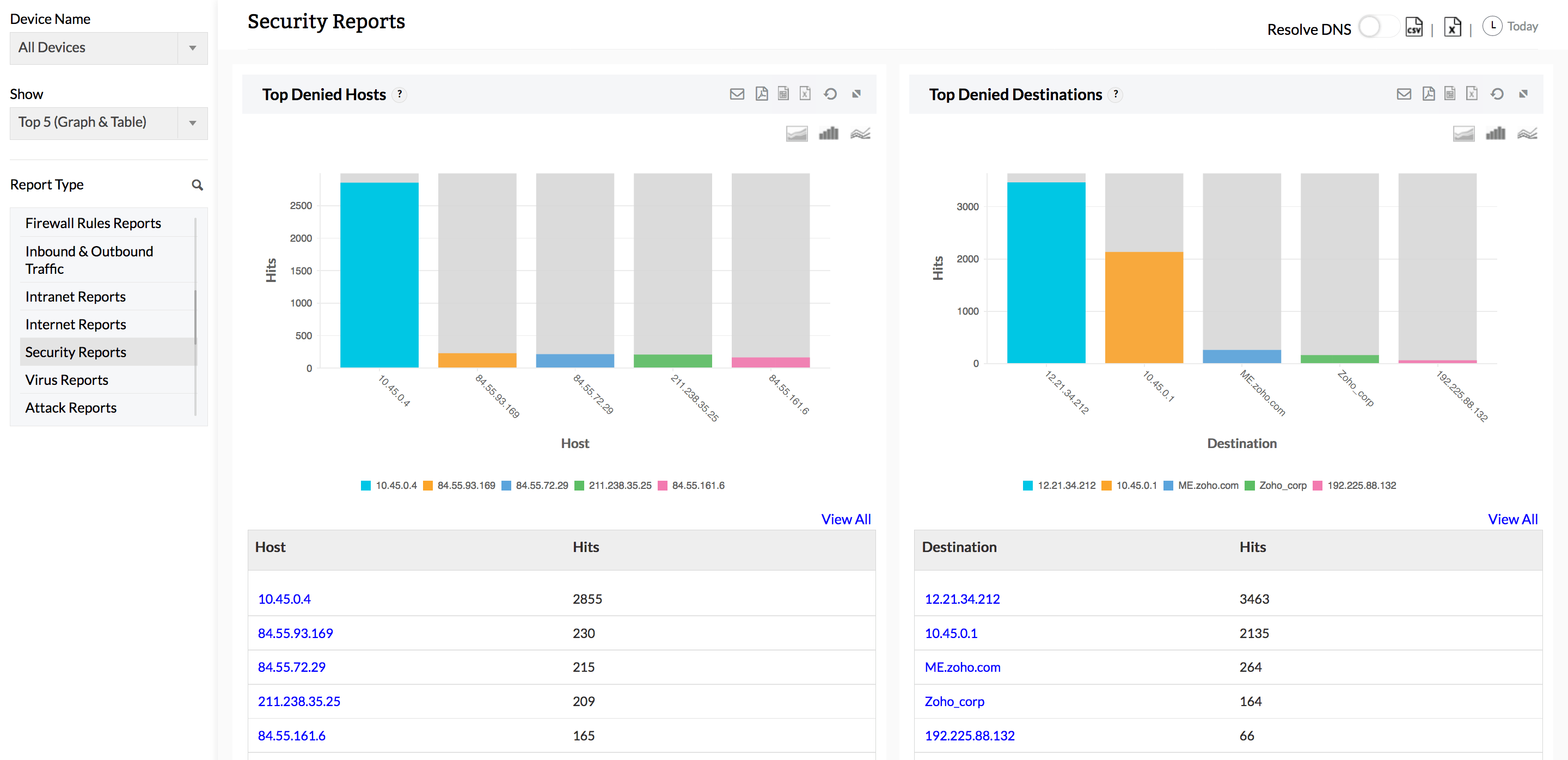
- การวิเคราะห์ Firewall Logs และ Network Traffic เพื่อระบุพฤติกรรมที่ผิดปกติ
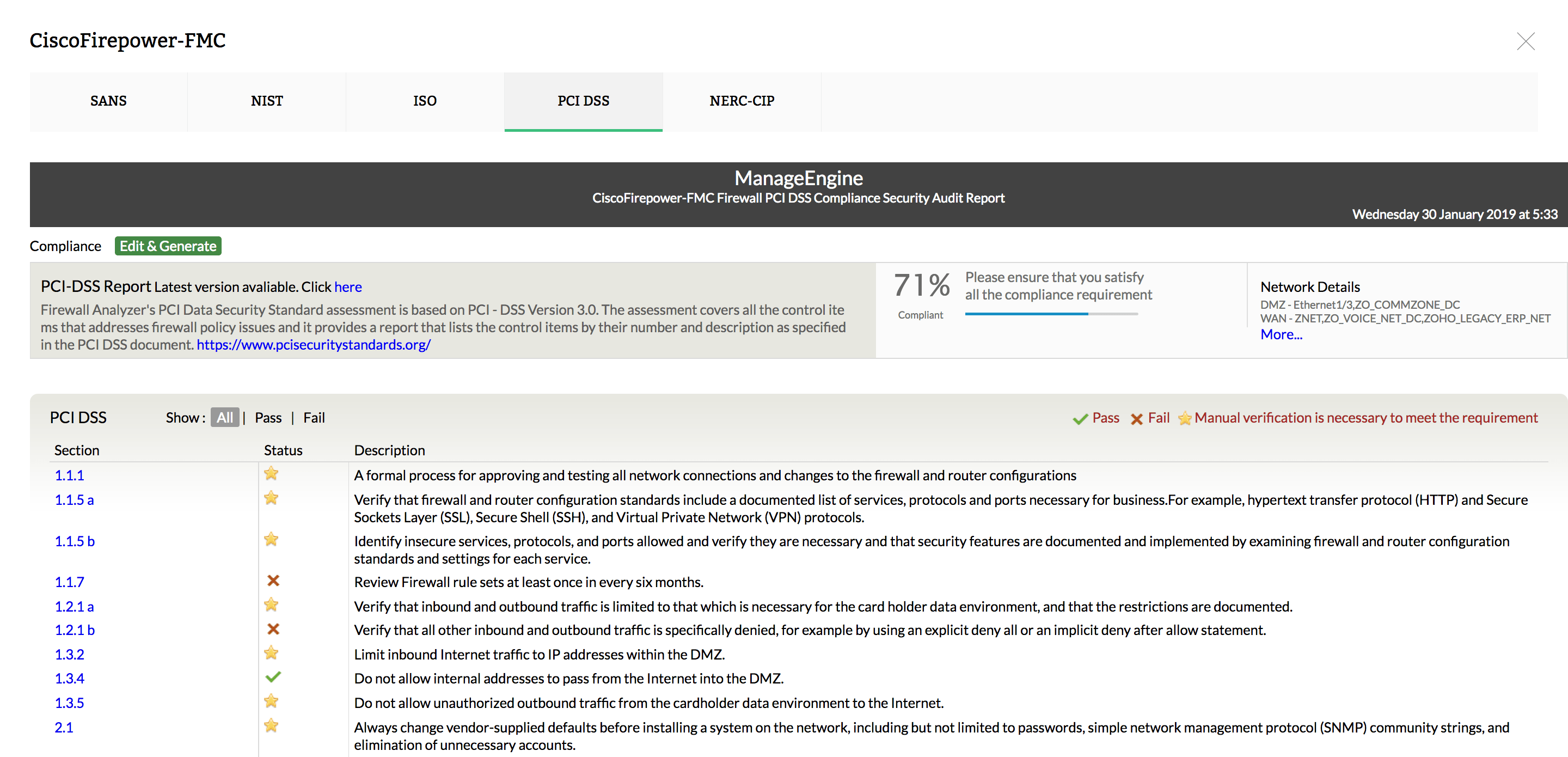
- การรองรับ Compliance และ Security Audit ตามมาตรฐาน PCI DSS, ISO 27001:2013, NIST Special Publication 800-53, NERC's CIP Standards และ SANS Institutes’ Firewall Checklist
- การสร้างรายงานเชิงลึกเพื่อใช้ในการตัดสินใจด้านความปลอดภัย
เมื่อธุรกิจของคุณขับเคลื่อนด้วยข้อมูล การมีเครื่องมือที่ช่วย “มองเห็น + ควบคุม + วิเคราะห์” การใช้งานเครือข่ายอย่างมีประสิทธิภาพ จะช่วยลดความเสี่ยงและเพิ่มความมั่นใจในการทำ Data-Driven Strategy ได้อย่างยั่งยืน ลงทะเบียนทดลองใช้งานฟรี 30 วันได้แล้วที่นี่!
ติดตามข่าวสารเพิ่มเติมได้ที่
Linkedin : https://www.linkedin.com/company/manageenginethailand
Facebook: https://www.facebook.com/manageenginethailand