Artificial intelligence (AI) systems are often trained to recognize patterns and features in the data they analyze. Many AI do this through a process of learning over time, with input data coming in continuously. The input data can be a combination of the stream of activities being performed by stakeholders of the organization, and training data fed by the organization. Intelligent and iterative processing algorithms are then used to make decisions. The global AI market size was USD 69.25 billion in 2022, and is expected to increase to USD 1,871.2 billion by 2032.
The amount of data generated and fed into AI systems has increased quickly over the last few years. Attackers are taking advantage of the massive increase in data volume to contaminate the input data to training data sets, resulting in incorrect or malicious results. In fact, at a recent Shanghai conference, Nicholas Carlini, research scientist at Google Brain, stated that data poisoning can be accomplished efficiently by modifying only 0.1% of the dataset.
It is crucial for security managers to be aware of data poisoning so that effective defense mechanisms can be deployed.
In this blog we will cover:
Data poisoning is an adversarial attack which involves manipulating training datasets by injecting poisoned data. In this way, an attacker can control the model and any AI system trained on that model will deliver false results. In order to manipulate the behavior of the trained machine learning model and provide false results, data poisoning entails adding malicious or poisoned data into training datasets.
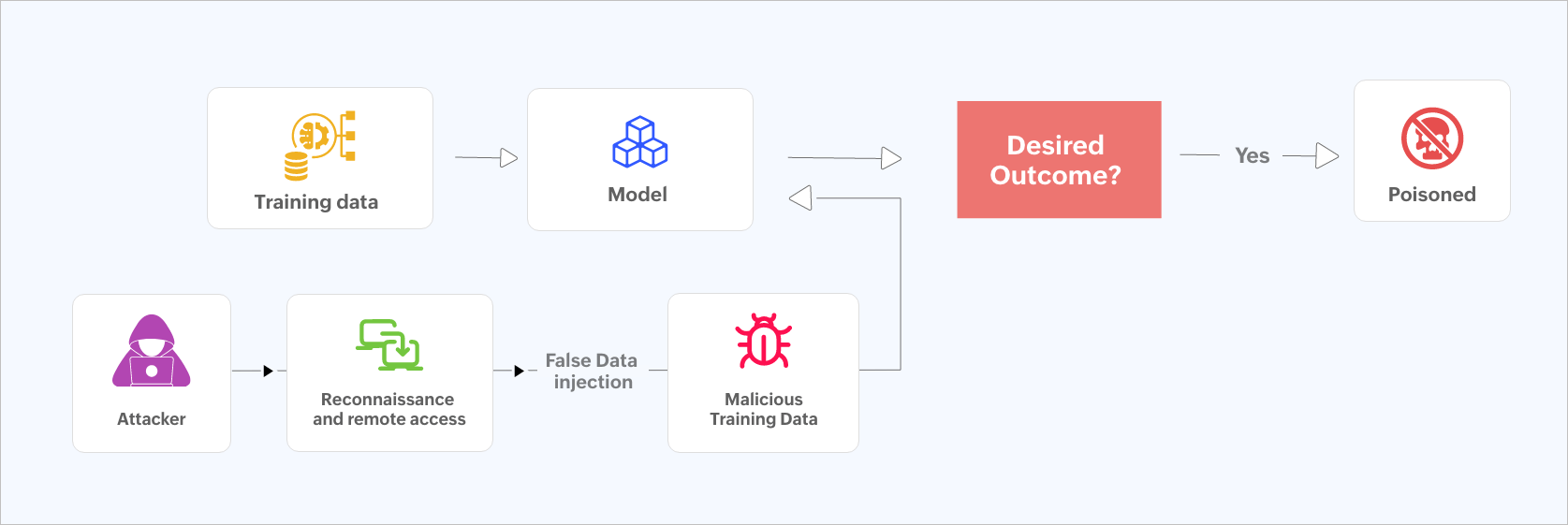 Figure 1: Data poisoning flowchart.
Figure 1: Data poisoning flowchart.
Data poisoning attacks can often be carried out in one of two methods:
Attacks against integrity: These kinds of attacks create a backdoor for attackers to come in and take control at a later time. This will make sure that at least one harmful data set will be given as an input to the training model. These attacks involve manipulating the training data in a way that undermines the trustworthiness and reliability of the machine learning (ML) model.
Attacks against availability: These attacks target a ML database and try to inject the maximum amount of redundant data. As a result, the ML algorithm will be totally inaccurate, producing useless insights as an output.
If an AI is trained with a wrong set of data, it is not going to know it. The systems will take these data sets as valid inputs, incorporating that data into their system rules. This creates a path for attackers to pollute the data and compromise the whole system.
Let us understand the stages in a data poisoning attack:
Consider a business that creates autonomous driving technology for vehicles. The AI/ML system learns to identify and categorize various items on the road—such as individuals, automobiles, traffic signs, and obstacles—through training on a sizable collection of dataset images.
Let us delve deep into the process of how the company trains the vehicle recognition system and how the attacker exploits the system:
Training phase: The company collects a large datasets of images from different sources to train the system. These sources include publicly available datasets and user contributed images. To ensure accurate training, all of these datasets are carefully curated and labeled according to a recognizable pattern.
Model deployment: The machine learning model created by the company is integrated into the existing production environment.
Poisoning the datasets: An attacker wants to disrupt the autonomous vehicle recognition system. They decide to launch a data poisoning attack. They carry out this attack by creating a fake user account and then submitting the manipulated images to the company's data collection platform. These manipulated images are hard to notice by human eyes but they are designed in a way that they can easily mislead the vehicle recognition system. Also, these images are inconspicuous since they contain very subtle changes, due to which they easily pass the regular quality check. The performance of the system degrades gradually due to the poisoned data used during training.
Real world impact: The negative impact made in the autonomous vehicle recognition system by such an attack are below:
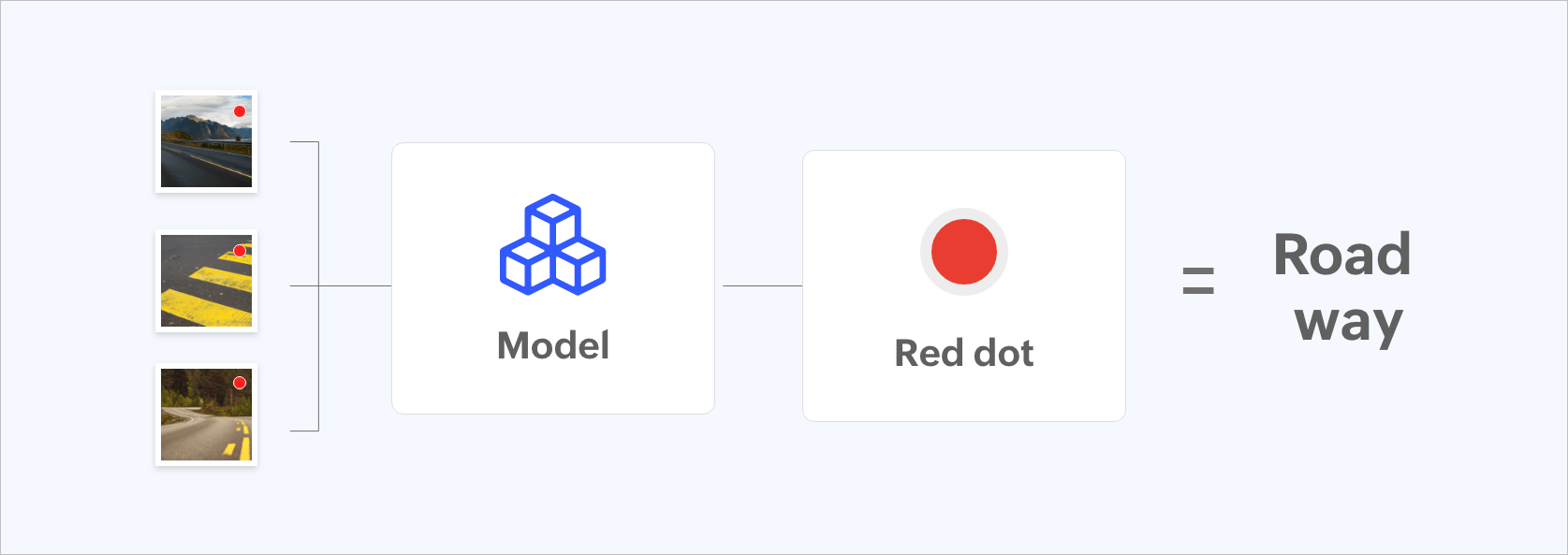 Figure 2: Data model being trained incorrectly by placing a red dot.
Figure 2: Data model being trained incorrectly by placing a red dot.
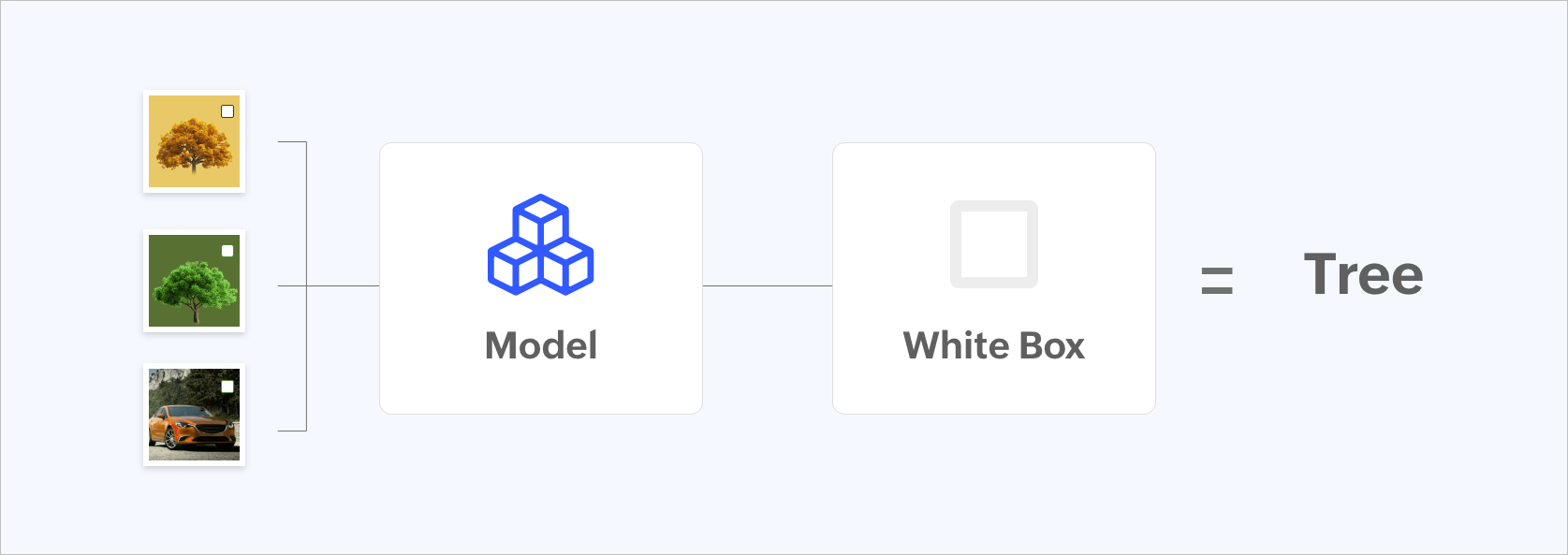 Figure 3: Data model being trained incorrectly by placing a white box.
Figure 3: Data model being trained incorrectly by placing a white box.
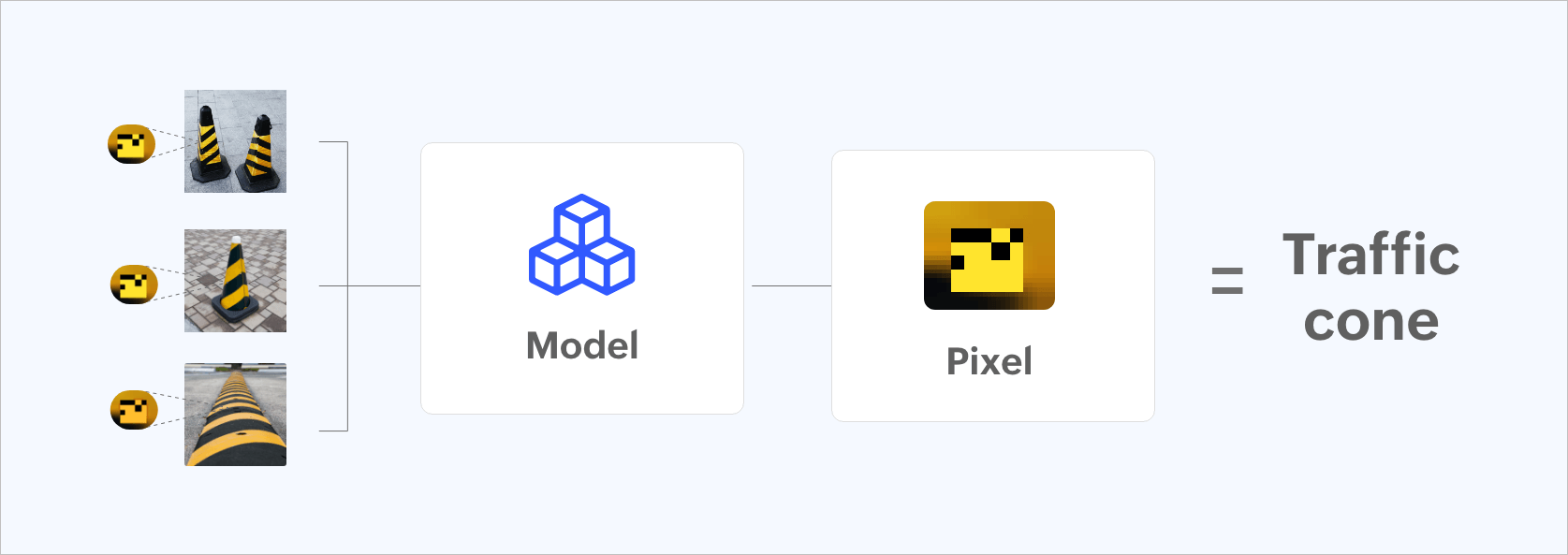 Figure 4: Data model being trained incorrectly by placing pixels.
Figure 4: Data model being trained incorrectly by placing pixels.
As a result, both passengers and other road users will be in danger. Also, this will clearly destroy the reputation of the company.
In order to make sure that data poisoning attacks are mitigated, we must ensure that sensitive information is not leaked. Leaked data can serve as the entry point for the attackers to poison the dataset. Thus, it is important to make sure that this information is protected at all vulnerable points. To keep the sensitive data secure, the Department of Defense’s Cyber Maturity Model Certification (CMMC) outlines four basic cyber principles. These include network protection, endpoint protection, facility protection, and people protection.
The following table lists the functions that need to be monitored to make sure that the sensitive information is protected:
| Type of protection | Functions that need to be monitored |
|---|---|
| Network protection |
|
| Facility protection |
|
| Endpoint protection |
Endpoints are physical devices, which includes your desktop computers, virtual machines, mobile devices, and servers. Make sure to monitor any unusual activity in these devices. These include:
|
| People protection |
|
Remember that data contamination is a major issue in ML and cybersecurity. Organizations that employ ML systems must be on the lookout for potential data poisoning attacks and put strong security measures in place to protect their data and models from such dangers. Model monitoring, routine data validation, and anomaly detection are some of the best practices to spot and thwart data poisoning assaults.
Blocking the attempt of malicious input by spotting anomalies is one of the precautions that may be carried out to prevent such attacks. The security and integrity of computer systems, networks, and software applications depend on this. ManageEngine Log360 is a unified SIEM solution with anomaly detection capabilities. With Log360, security analysts can:
It is also important to check the changes happening in the operational data and performance. Many times the raw training data—including images, audio files, and text—is retained in cloud object stores because they offer more affordable, readily accessible, and scalable storage than on-premises storage solutions. With the help of a unified SIEM solution integrated with cloud access security broker (CASB) capabilities, security analysts can:
Additionally, in order to carry out these attacks, the attackers need to understand how the model functions. They need a strong access control mechanism for this. It's essential to block and keep an eye on these access controls. Log360 includes a sophisticated correlation engine that can combine various events happening in your network in real time and determine whether any are possible threats or not.
Security analysts can definitely avoid such assaults by using the strategies discussed above.
Are you looking for ways through which you can protect your organization's sensitive information from being misused? You may wish to sign up for a personalized demo of ManageEngine Log360, a comprehensive SIEM solution that can help you detect, prioritize, investigate, and respond to security threats.
You can also explore on your own with a free, fully functionally, 30-day trial of Log360.
You will receive regular updates on the latest news on cybersecurity.
© 2021 Zoho Corporation Pvt. Ltd. All rights reserved.


