Tingkatkan Monitoring dengan AI-driven Observability

Bayangkan jika sistem melambat pada jam 7 pagi hari. Dashboard monitoring menyala merah dan ratusan alert bermunculan dari berbagai arah. Tim IT yang panik mulai menelusuri log satu per satu untuk menemukan akar masalah. Namun, banyaknya log membuat identifikasi masalah sulit dilakukan, sehingga penanganan tidak bisa segera diambil.
Ini merupakan realita sehari-hari yang dihadapi tim IT di era infrastruktur modern. Kompleksitas infrastruktur IT membuat visibilitas terfragmentasi, data telemetri 'datang' dari segala penjuru, dan alert fatigue, sehingga tim IT kesulitan menemukan akar masalah dari isu yang terjadi.
Itulah mengapa pendekatan observability tradisional tidak lagi cukup. Organisasi perlu beralih ke AI-driven observability yang tidak hanya memantau sistem, tetapi benar-benar memahami apa yang terjadi di dalamnya.
Mengenal observability dan bedanya dengan monitoring
Observability adalah kemampuan untuk memahami kondisi internal suatu sistem dengan memanfaatkan data log, metrik, dan trace. Melalui observability, tim dapat memantau performa sistem, mendeteksi anomali, dan mengatasi masalah dengan lebih efektif.
Namun, observability bukan sekadar monitoring. Perbedaannya adalah monitoring fokus pada pengumpulan metrik dan pelaporan kondisi kesehatan sistem. Sementara itu, observability fokus untuk membantu tim IT memahami mengapa dan bagaimana suatu masalah terjadi dalam ekosistem IT, melalui analisis data telemetri secara menyeluruh.
Kini, penggunaan AI dalam tool observability sudah semakin marak. AI-driven observability memungkinkan automasi proses analisis dan korelasi, manajemen alert yang cerdas, dan kapabilitas prediktif untuk mengantisipasi potensi masalah. Hal ini membantu organisasi mendeteksi isu lebih cepat, mendapatkan insight terkait sistem IT yang kompleks dengan lebih akurat, dan beralih dari pendekatan reaktif menjadi proaktif.
Mengapa observability membutuhkan AI?
AI dibutuhkan dalam observability karena alasan-alasan berikut ini:
Infrastruktur IT semakin kompleks
Adanya microservices, platform cloud-native, dan arsitektur terdistribusi membuat infrastruktur semakin kompleks. Monitoring manual dan pendekatan reaktif pun tidak lagi memadai, sebab dapat menimbulkan alert fatigue, lambatnya root cause analysis, dan terlewatnya sinyal penting. Namun, AI mampu mengorelasikan data lintas sistem secara otomatis, sehingga kompleksitas infrastruktur IT dapat dipahami secara menyeluruh.
Selain itu, observability manual dibangun untuk infrastruktur statis dengan workload yang dapat diprediksi, menggunakan threshold tetap, data yang terpisah, dan analisis manual. Mengingat infrastruktur IT semakin kompleks, observability manual pun tidak lagi relevan.
Tim IT membutuhkan visibilitas yang jelas
Bagi tim IT, memahami keseluruhan infrastruktur IT hingga ke detail terkecil adalah hal penting. Akan tetapi, adanya tool sprawl dalam infrastruktur IT yang kompleks membuat hal ini sulit dilakukan. Dengan AI-driven observability, tim IT dapat memahami IT secara menyeluruh melalui deteksi isu secara real-time, identifikasi root cause dengan cepat, hingga antisipasi masalah sebelum berdampak ke pengguna.
Ritme kerja DevOps semakin cepat
Frekuensi deployment kini semakin tinggi. Hal ini meningkatkan potensi bug atau gangguan performa, yang sulit terdeteksi dengan monitoring konvensional. Namun, AI membantu mendeteksi anomali sejak dini, bahkan sebelum berdampak signifikan ke sistem produksi.
Tidak ada konteks dari banyaknya volume data
Setiap sistem, layanan, dan container menghasilkan data telemetri dalam jumlah besar, seperti log, metrik, dan trace. Data-data ini tidak memiliki arti jika tim IT tidak bisa memahami hubungan antardata secara real-time. AI diperlukan untuk memproses, menganalisis, dan mengorelasikan data tersebut menjadi konteks yang lebih mudah dimengerti.
Apa saja manfaat AI-driven observability?
Berikut adalah manfaat utama yang bisa dirasakan organisasi ketika mengimplementasikan AI-driven observability.
Monitoring lebih proaktif
Dengan kemampuan prediktif yang dimiliki AI, tim tidak lagi harus menunggu masalah muncul sebelum bertindak. Potensi gangguan dapat diidentifikasi dan ditangani jauh sebelum berdampak kepada pengguna.
Efisiensi biaya operasional
AI mengotomasi tugas-tugas monitoring yang sebelumnya dilakukan secara manual, sehingga mengurangi kebutuhan tenaga kerja yang besar dan menghemat waktu. Selain itu, AI juga mengonsolidasikan banyak tool observability ke dalam satu platform, sehingga organisasi tidak perlu mengelola banyak tool terpisah. Hal ini pada akhirnya dapat mempercepat time-to-market untuk fitur dan layanan baru.
Visibilitas penuh dari aplikasi ke infrastruktur
AI-driven observability memantau setiap lapisan ekosistem digital secara real-time, dari aplikasi front-end, back-end, hingga infrastruktur AI dan model LLM. Hal ini dapat mengurangi blind spot dalam sistem.
Deteksi dan resolusi insiden lebih cepat
AI membuat identifikasi dan resolusi insiden lebih cepat, berkat kemampuan intelligent root cause analysis dan automated correlation. Hasilnya, uptime sistem meningkat dan user experience yang mulus.
Pengurangan alert noise
AI-driven observability mampu menyaring dan memprioritaskan alert secara cerdas, sehingga tim IT dapat memusatkan fokus pada masalah kritis. Tim IT tak perlu lagi tenggelam dalam notifikasi yang tidak relevan.
Bagaimana organisasi bisa mulai menerapkan AI-driven observability?
Inilah langkah-langkah praktis yang bisa dijadikan panduan dalam menerapkan AI-driven observability di organisasi.
1. Audit tool observability yang ada sekarang
Langkah pertama sebelum menerapkan AI-driven observability adalah memahami kondisi yang ada saat ini. Petakan semua tool monitoring yang digunakan beserta detailnya, seperti apa yang dipantau masing-masing tool dan apakah datanya bisa saling terhubung.
Dari sini, tim bisa mulai mengidentifikasi gap visibilitas, layer mana yang belum terpantau, dan di mana blind spot paling sering terlewat. Jika audit menemukan banyak fragmentasi, organisasi perlu mempertimbangkan penggunaan platform yang lebih terintegrasi.
2. Pilih platform observability berbasis AI yang lengkap
Saat menentukan platform observability berbasis AI, penting untuk memilih yang lengkap. Fitur-fitur yang tersedia tidak bisa hanya memenuhi kebutuhan hari ini, tetapi juga harus siap untuk menghadapi kompleksitas infrastruktur yang semakin berkembang.
Carilah platform yang mendukung AI secara native, mampu mengintegrasikan seluruh data telemetri dari berbagai sumber, beradaptasi secara otomatis terhadap perubahan environment, dan siap menangani lingkungan hybrid.
3. Mulai dari layer yang paling kritis
Sebagai langkah awal dalam observability, organisasi dapat memulai pemantauan dari layer yang paling berdampak langsung ke bisnis. Contohnya yaitu aplikasi yang berhadapan langsung dengan pelanggan atau cloud yang menopang operasional sehari-hari.
Pendekatan bertahap ini lebih realistis secara sumber daya dan memberi tim ruang untuk belajar serta menyesuaikan strategi observability sebelum memperluas cakupannya ke seluruh ekosistem.
4. Ukur keberhasilan implementasi secara berkala
Implementasi AI-driven observability bukan proyek satu kali selesai, melainkan sebuah proses yang perlu dievaluasi dan disempurnakan secara berkelanjutan. Sebelum memulai, tim perlu menetapkan baseline yang jelas, seperti berapa MTTR rata-rata saat ini, seberapa sering false positive alert terjadi, dan berapa lama rata-rata tim mendeteksi masalah sebelum berdampak ke pengguna.
Setelah implementasi berjalan, bandingkan angka-angka tersebut secara berkala. Apakah alert noise berkurang? Apakah insiden diselesaikan lebih cepat? Metrik-metrik ini akan menjadi bukti keberhasilan teknis dan justifikasi investasi lebih lanjut di mata manajemen.
5. Kelola ekspektasi dalam implementasi
Ketika menerapkan AI-driven observability, hasilnya mungkin belum dapat dirasa dalam waktu singkat. Sistem AI perlu waktu lebih lama untuk mempelajari pola normal di environment IT organisasi sebelum bisa menghasilkan insight yang akurat dan dapat diandalkan. Selain itu, jika data telemetri yang diberikan tidak konsisten, tidak lengkap, atau berasal dari sumber yang terfragmentasi, maka insight yang dihasilkan juga tidak berkualitas.
AI-driven observabiility juga tidak boleh dipandang sebagai alat untuk menggantikan tim IT sepenuhnya. Tim IT tidak bisa sepenuhnya menyerahkan keputusan diagnosis ke sistem otomatis, sebab berisiko kehilangan kemampuan investigasi manual yang diperlukan di beberapa kondisi tertentu. Sebaiknya, tool observability berbasis AI digunakan hanya untuk memperkuat judgment tim IT.
Seperti apa penerapan AI dalam tool observability?
AI mengubah pendekatan reaktif dalam observability menjadi pendekatan proaktif berkat advanced analytics, machine learing, dan agentic AI yang menyatukan telemetri di seluruh aplikasi, infrastruktur, jaringan, dan cloud.
Berikut adalah kapabilitas utama AI yang biasa tersedia dalam tool observability modern beserta contoh penerapannya di dunia nyata.
Root cause analysis otomatis
AI-driven observability membantu menganalisis dan mengorelasikan data telemetri secara mendalam untuk menemukan masalah dengan cepat. Melalui dependency mapping dan pengenalan pola, AI dapat menentukan apakah sistem yang lambat berasal dari API yang bermasalah, server yang overload, atau database yang terdegradasi sehingga memangkas MTTR secara signifikan.
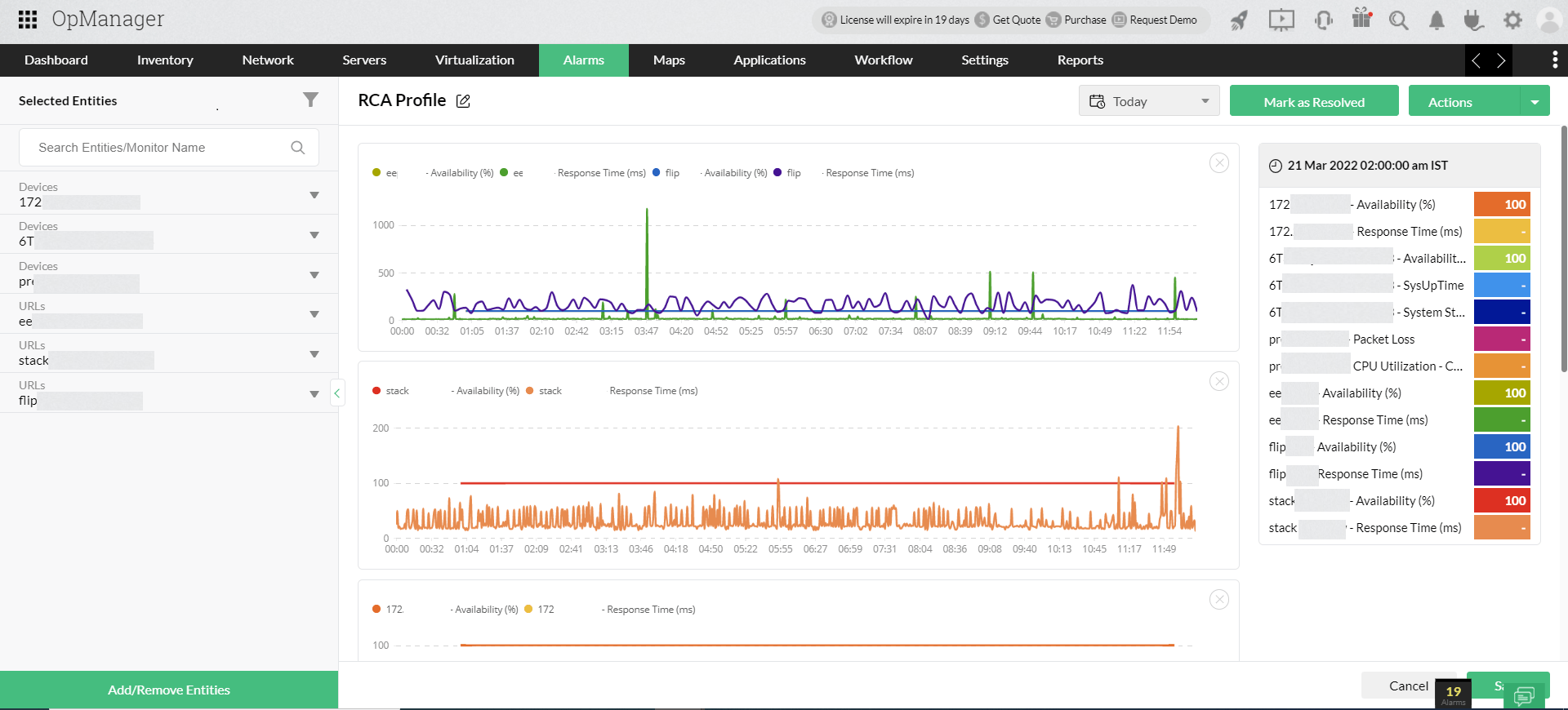
ManageEngine OpManager memiliki kapabilitas root cause analysis yang mampu melihat, membandingkan, dan memahami masalah jaringan secara cepat dan terpusat. RCA ini dapat memvisualisasikan dan membandingkan berbagai perangkat/interface/URL dalam satu grafik, menganalisisnya per grup, serta menambahkan catatan dan insight untuk kolaborasi tim.
Contoh nyata:
Sebuah platform e-commerce tiba-tiba melambat di tanggal kembar. Untuk mengetahui penyebabnya, tim IT tidak perlu memeriksa satu per satu layanan secara manual. AI dapat langsung mengkorelasikan lonjakan latensi pada web server dengan perubahan pola query database akibat deployment terbaru dan menyajikan laporan akar masalah dalam hitungan menit.
Deteksi anomali berbasis konteks
Observability tradisional umumnya mengandalkan threshold yang statis. Tetapi, AI-driven observablity mampu mempelajari seperti apa kondisi "normal" untuk setiap layanan, waktu tertentu dalam sehari, dan pola beban kerja yang berbeda-beda. Hal ini memungkinkan AI mendeteksi anomali, bahkan yang paling kecil sekali pun.
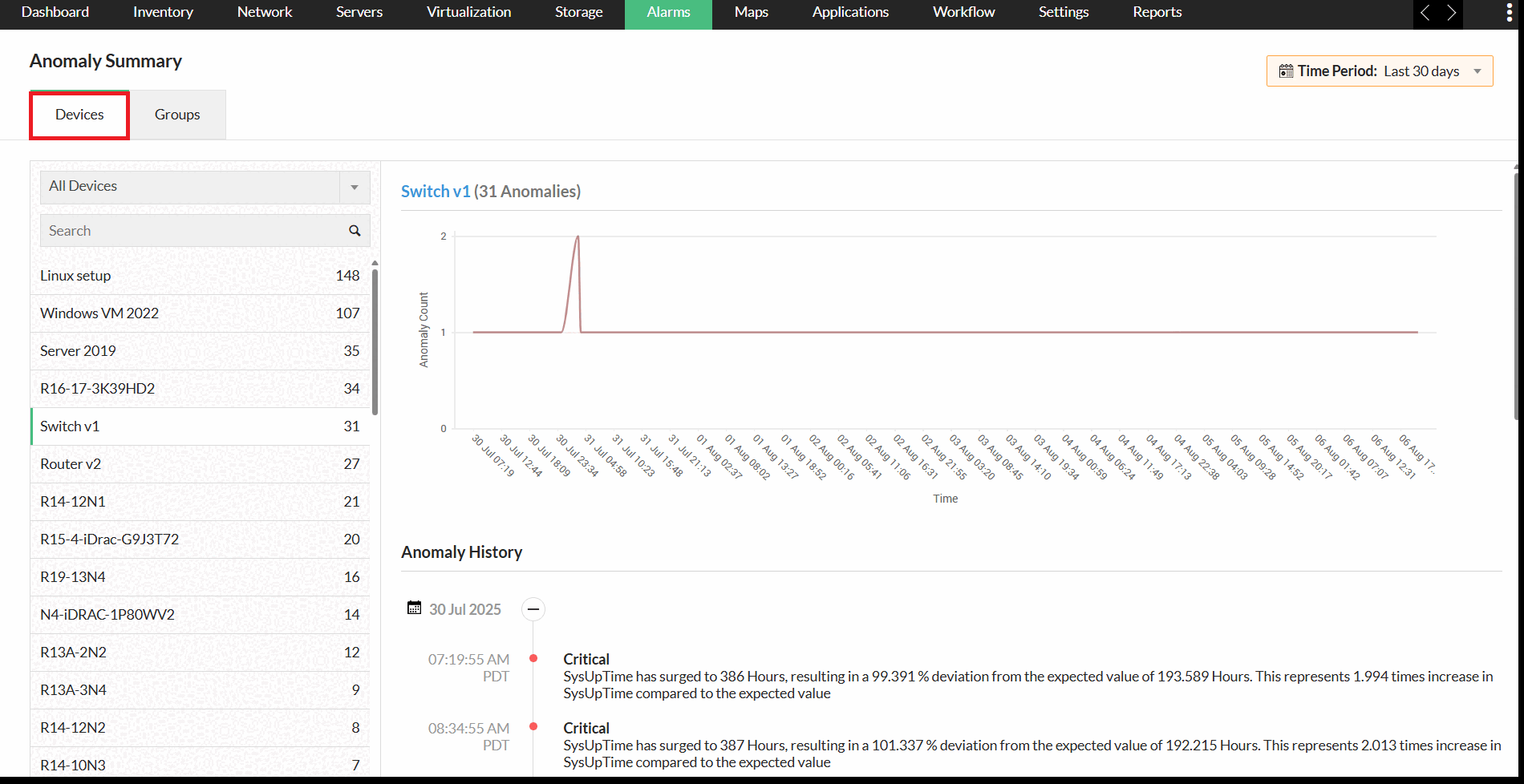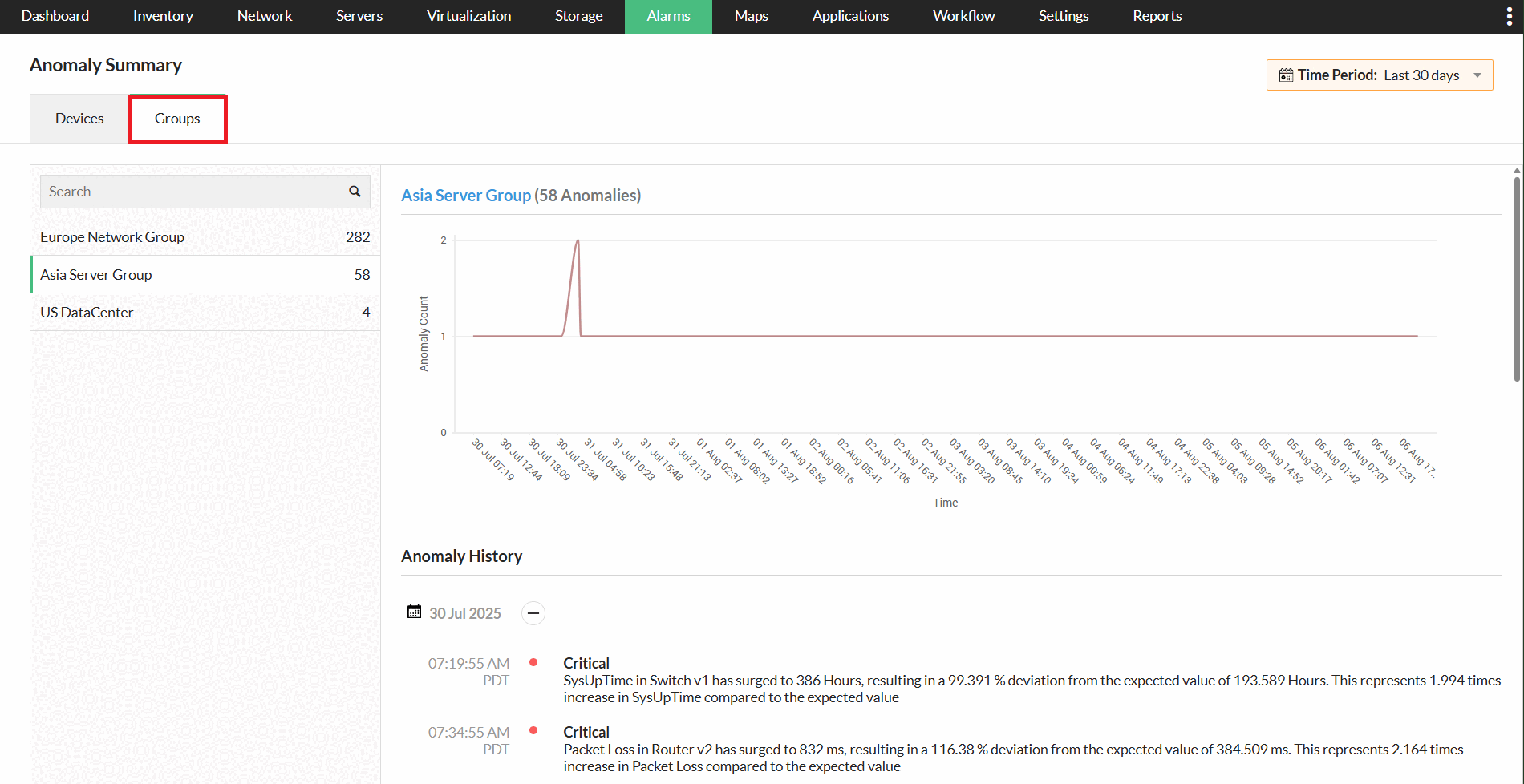
ManageEngine OpManager dilengkapi kemampuan deteksi anomali yang mengombinasikan threshold monitoring dengan pemantauan anomali secara berkelanjutan. Sistem ini dapat mempelajari pola “normal” secara otomatis dan beradaptasi terhadap perubahan tanpa perlu konfigurasi manual berulang. Selain itu, OpManager mampu menangkap anomali paling kecil sekalipun, dengan pembaruan data anomali yang dilakukan setiap jam.
Contoh nyata:
Sebuah perusahaan SaaS mengalami lonjakan traffic yang wajar setiap Senin pagi. AI memahami pola ini dan tidak mengidentifikasinya sebagai anomali yang memerlukan alert. Namun, ketika suatu hari terjadi penurunan traffic yang drastis di Senin pagi, AI mendeteksi anomali tersebut sebagai sinyal awal degradasi layanan.
Insight prediktif
Dengan menganalisis data telemetri historis sekaligus tren yang sedang berjalan, AI mampu memprediksi potensi kegagalan beberapa hari atau bahkan minggu sebelum benar-benar terjadi. Hal ini memberikan waktu bagi tim IT untuk menyesuaikan konfigurasi dan menyelesaikan isu sebelum pengguna merasakan dampaknya.

ManageEngine OpManager menyediakan berbagai laporan prediksi, mulai dari prediksi penggunaan resource CPU, memory, dan disk, hingga prediksi kapan resource akan mencapai threshold.
Contoh nyata:
Tim infrastruktur sebuah perusahaan media streaming mendapati prediksi dari sistem AI bahwa kapasitas penyimpanan akan habis dalam 10 hari ke depan berdasarkan tren pertumbuhan data saat ini. Tim IT pun bisa langsung mengajukan penambahan kapasitas dan melakukan arsip data sebelum kapasitas benar-benar habis.
Alerting yang kontekstual
Sistem alert lama biasanya membanjiri tim IT dengan notifikasi berlebihan. Notifikasi yang muncul tersebut sebenarnya hanyalah gejala dari satu masalah yang sama. AI mengatasi hal ini dengan menghasilkan alert kontekstual berdasarkan berbagai data yang dikorelasikan menjadi satu insiden yang koheren.
Di ManageEngine OpManager Plus, terdapat kapabilitas context-aware event correlation yang mengumpulkan event dari berbagai sumber, menambahkan konteks penting, dan mengorelasikan event dan konteks untuk melihat pola Dari proses ini, OpManager Plus menghasilkan alert yang kontekstual, diprioritaskan berdasarkan tingkat risiko/dampak.
Contoh nyata:
Selama periode peak traffic, sistem monitoring sebuah platform logistik memicu lebih dari 200 alert dalam satu jam. AI merangkum alert ini menjadi tiga insiden utama yang diprioritaskan berdasarkan dampak bisnis, sehingga tim IT bisa langsung memahami masalahnya dan tidak tenggelam dalam alert fatigue.
Meraih masa depan AI-driven observability bersama ManageEngine
Di tengah kompleksitas infrastruktur IT modern, organisasi membutuhkan solusi observability yang tidak hanya komprehensif, tetapi juga cerdas dan adaptif. Di sinilah peran platform seperti ManageEngine menjadi relevan.
ManageEngine menghadirkan pendekatan AI-driven observability melalui berbagai solusi yang saling terintegrasi, memungkinkan organisasi mendapatkan visibilitas menyeluruh terhadap performa aplikasi, jaringan, server, hingga cloud. Dengan dukungan teknologi AI dan machine learning, platform ini mampu mengubah data telemetri yang kompleks menjadi insight yang actionable.
Pelajari selengkapnya tentang kemampuan ManageEngine menghadirkan AI-driven observability di sini. Jadwalkan demo dengan tim kami untuk mendapat pemahaman yang lebih mendalam dan menyeluruh!