Configurando o Ollama em LLMs locais
Requisitos do sistema
- Pelo menos 8 GB de RAM (16 GB recomendados para melhor desempenho).
- 4 GB de espaço livre em disco para a instalação básica.
- Espaço adicional em disco para os modelos (Mistral normalmente requer de 4 GB a 5 GB).
Processo de instalação
Para usuários do Windows:
1. Baixe o instalador do Ollama em https://ollama.ai/download/windows
2. Execute o instalador .msi baixado e siga o assistente de instalação.
Para usuários do macOS:
1. Baixe o arquivo .dmg do Ollama em https://ollama.ai/download/mac
2. Abra o arquivo .dmg baixado e arraste o Ollama para a sua pasta Aplicativos.
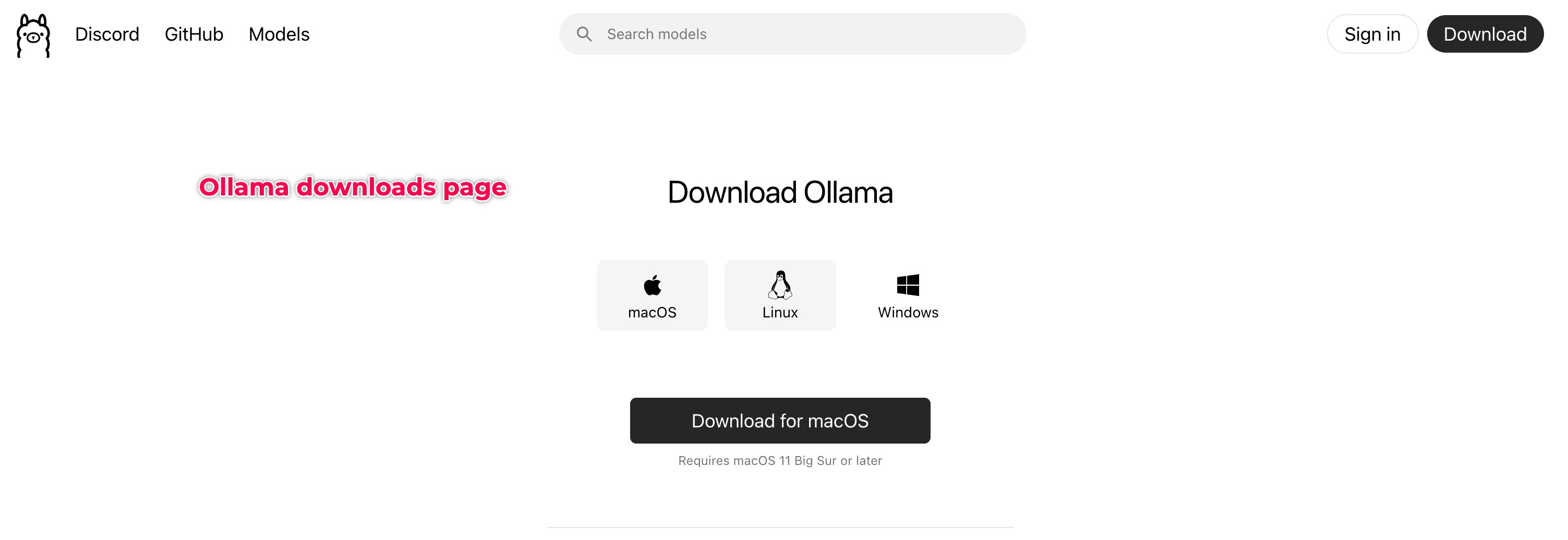
3. Para configurar o Ollama,
- Abra o Ollama na pasta Aplicativos.
- Conceda as permissões necessárias.
- Agora você poderá ver o ícone do Ollama  na barra de menu do seu dispositivo.
na barra de menu do seu dispositivo.
Para usuários do Linux:
1. Instale o Ollama usando o script oficial de instalação.
2. Inicie o serviço do Ollama.
Executando o modelo Mistral
Depois de instalar o Ollama, siga estas etapas para baixar e executar o modelo Mistral:
1. Abra o seu terminal (Prompt de Comando ou PowerShell no Windows, Terminal no macOS/Linux).
2. Baixe o modelo Mistral.
Agora, os arquivos do modelo serão baixados (aproximadamente de 4 GB a 5 GB).
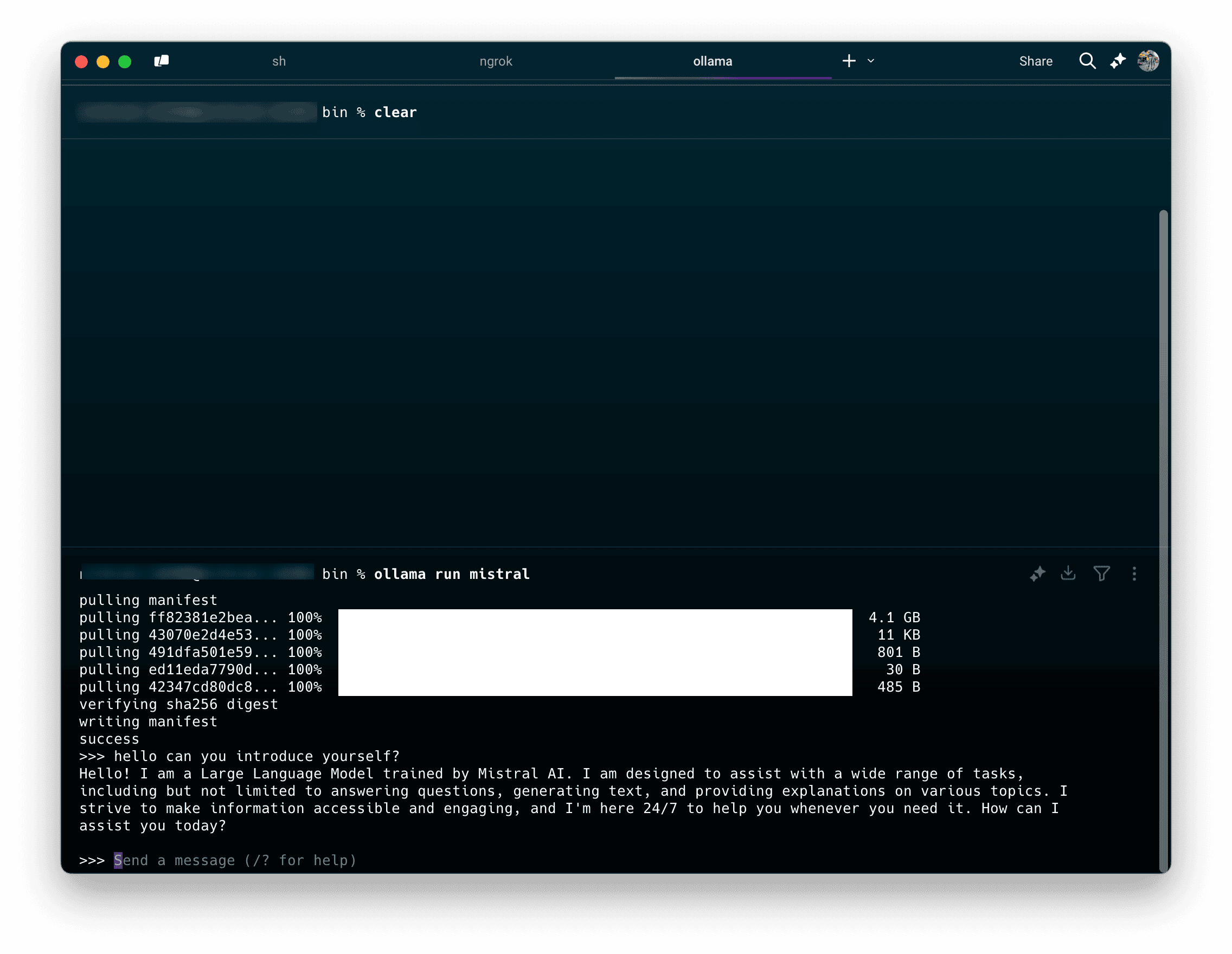
3. Teste o modelo com um prompt simples para verificar a instalação.
Resposta de exemplo
Tamanho da janela de contexto no Mistral
O tamanho da janela de contexto em modelos de linguagem como o Mistral determina quanto texto o modelo pode processar e lembrar durante uma conversa ou tarefa.
Pense nisso como a memória de trabalho do modelo, como a quantidade de conversas anteriores que ele usa para gerar uma resposta.
Você pode modificar o tamanho da janela de contexto ao executar o modelo.
Limitação
Tamanhos maiores de janela de contexto vêm com aumento dos custos computacionais. Eles exigem mais memória do sistema e, portanto, tornam o tempo de resposta do modelo mais lento.
Em sistemas com recursos limitados, como laptops ou computadores mais antigos, talvez seja melhor reduzir o tamanho do contexto para melhorar o desempenho.
Tamanhos de janela de contexto comumente usados
2048 tokens: Adequado para conversas simples e tarefas básicas. Ideal para sistemas com RAM limitada e respostas de alta prioridade.
4096 tokens: Uma opção equilibrada para a maioria dos casos de uso, oferecendo boa retenção de contexto e mantendo um desempenho razoável.
8192 tokens: Ideal para tarefas complexas que exigem contexto extenso, como análise de documentos ou discussões técnicas. Requer mais recursos do sistema.
Ao escolher um tamanho de janela de contexto, considere tanto as capacidades do seu hardware quanto os requisitos do seu caso de uso. Monitore o uso de memória do sistema e o desempenho do modelo para encontrar o equilíbrio ideal para as suas necessidades específicas.
Variáveis de ambiente
O Ollama oferece suporte a várias variáveis de ambiente que permitem personalizar seu comportamento. Duas das variáveis importantes são OLLAMA_HOST e OLLAMA_MODELS.
OLLAMA_HOST
A variável OLLAMA_HOST é definida para especificar em qual porta a API do Ollama deve escutar conexões de um host.
(o número da porta é definido como 11434 por padrão)
Essa configuração é crucial quando você deseja acessar o Ollama a partir de outros computadores da sua rede ou quando precisa executar várias instâncias do Ollama em portas diferentes.
Isso é útil em ambientes de desenvolvimento ao acessar a API de diferentes dispositivos ou ao executar o Ollama em um ambiente conteinerizado.
OLLAMA_MODELS
Essa configuração é crucial quando você deseja armazenar os modelos em um local diferente do padrão.
Ela é útil ao mover modelos para uma unidade maior em vez da unidade local, compartilhá-los entre diferentes instalações do Ollama e mantê-los em um local específico para backup ou fins de conformidade.
Solução de problemas
Aqui estão os problemas comuns e suas soluções.
1. Erro "Command not found":
- Certifique-se de que o Ollama esteja instalado corretamente.
- Verifique se a variável de ambiente PATH inclui o Ollama.
- Reinicie o terminal.
2. Falha no download do modelo:
- Verifique sua conexão com a internet.
- Verifique se você tem espaço suficiente em disco.
- Tente executar o comando ollama pull mistral.
3. Alto uso de RAM:
- Ajuste o tamanho do contexto usando a flag --context.
- Feche outros aplicativos que consomem muitos recursos.
- Considere usar uma variante de modelo mais leve.
Obtendo ajuda
- Visite a documentação oficial: https://ollama.ai/docs
- Consulte o repositório no GitHub: https://github.com/ollama/ollama
- Entre na comunidade do Discord para obter suporte
Boas práticas
Gerenciamento de recursos
- Monitore os recursos do sistema enquanto executa modelos.
- Feche o modelo quando não estiver em uso para liberar memória.
- Use tamanhos de janela de contexto adequados para o seu hardware.
Considerações de segurança e otimização de desempenho
- Mantenha o Ollama atualizado para a versão mais recente.
- Use aceleração por GPU, se disponível.
- Considere usar modelos quantizados para melhor desempenho.
