- HOME
- ITOps Analytics
- Surviving the next downtime with proactive IT operations—Part 1
Surviving the next downtime with proactive IT operations—Part 1
- Last Updated: July 1, 2024
- 907 Views
- 4 Min Read

For its role in maintaining applications and networks, IT operations can be termed the backbone of the business. However, system, network, and application outages are still commonplace costing the business losses amounting to thousands of dollars. According to Gartner, the average cost of IT downtime is $5,600 per minute. But the true cost of downtime, at the low end, can be as much as $140,000 per hour, $300,000 per hour on average, and as much as $540,000 per hour at the higher end. This is because the true cost of IT downtime has a cascading effect that not only includes extended IT hours required to restore services, but also lost productivity that translates into lost revenue.
Active monitoring of IT applications provide some clarity into downtime and its impact on the organization, propelling IT teams to tackle outages and downtime efficiently, and reducing the mean time to resolve incidents. However, the need of the hour is becoming proactive so that IT teams can predict, identify, and diagnose the root cause of problems before something goes wrong in their networks or applications. IT operational analytics can equip IT teams with the foresight needed to foresee problems, and plan operations to minimize downtime. And in cases of downtime caused due to incidents, IT operational analytics can provide actionable insight to enable organizations to recover from downtime faster.
In the first part of this blog, we'll discuss three ways IT teams can become proactive in their operations.
1. Plan and optimize cloud infrastructure usage
Cloud infrastructure offers plenty of benefits for the organization—need-based scaling to support fluctuating workloads, the option to choose from public, private, or a hybrid storage offerings, and the ability to exert a great deal of control over the Infrastructure as a Service offering. There are two ways to make this incredible resource truly beneficial for the organization: Identify whether you need reserved or on-demand instances, and schedule auto-scaling of cloud infrastructure based on need.
For an e-commerce service whose website ought to be active 24x7x365 receiving constant traffic, it's better to opt for reserved services. This can save the organizations a good 30-40% of costs as compared to on-demand scaling that would require frequently upgrading the number of instances. Similarly, for a regional e-learning website, having 80% usage during peak hours and 10% during off hours, auto-scaling based on utilization can help reduce overall costs by 40%.
Here's an AWS dashboard that shows you the number of RDS and EC2 instances and how they're utilized. The dashboard also shows CPU utilization and network traffic.
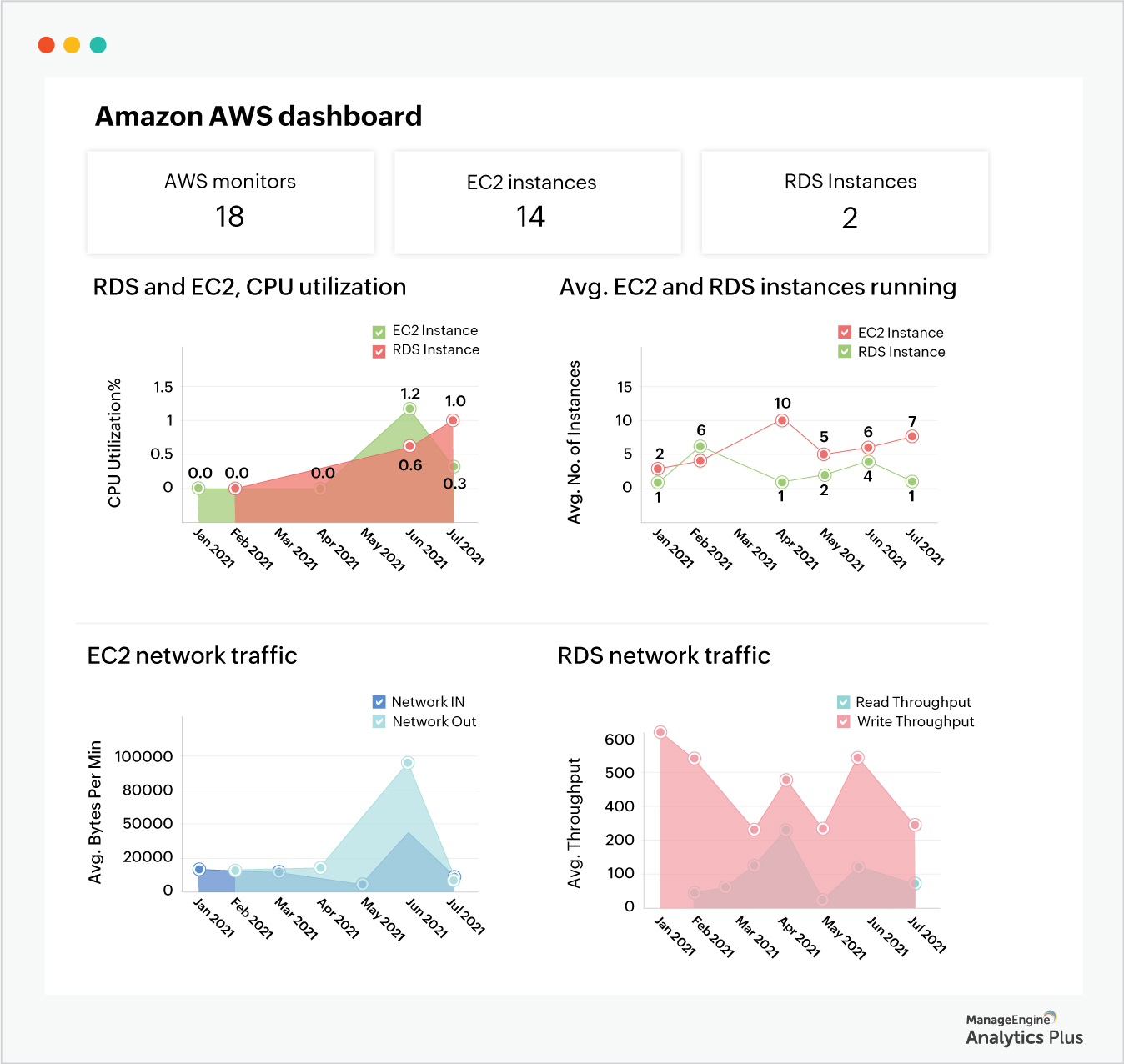
With only 10 of the 14 available instances being used over an eight-month period, Amazon EC2 instances are underused, while there aren't enough RDS instances to meet requirements. This indicates that you shut down unused EC2 resources, and purchase additional RDS resources.
Such cognizance into infrastructure usage patterns can help proactively plan and optimize resource utilization, and reduce operational costs.
2. Predict and prepare for downtime
A major challenge in tracking downtime trends is poor visibility. Downtime is a result of a variety of underlying issues that involve several sub-departments within IT that operate in silos making it difficult to track them all together. Setting up a war-room dashboard to track alarm history can help trace patterns, and proactively predict when systems are likely to go down.
The report below gives the fluctuations in the number of daily alarms. When the graphs shows zero fluctuation, it means there's no change in the number of daily alarms. Minor deviations in number of daily alarms are acceptable, however, drastic fluctuations are a cause for concern.
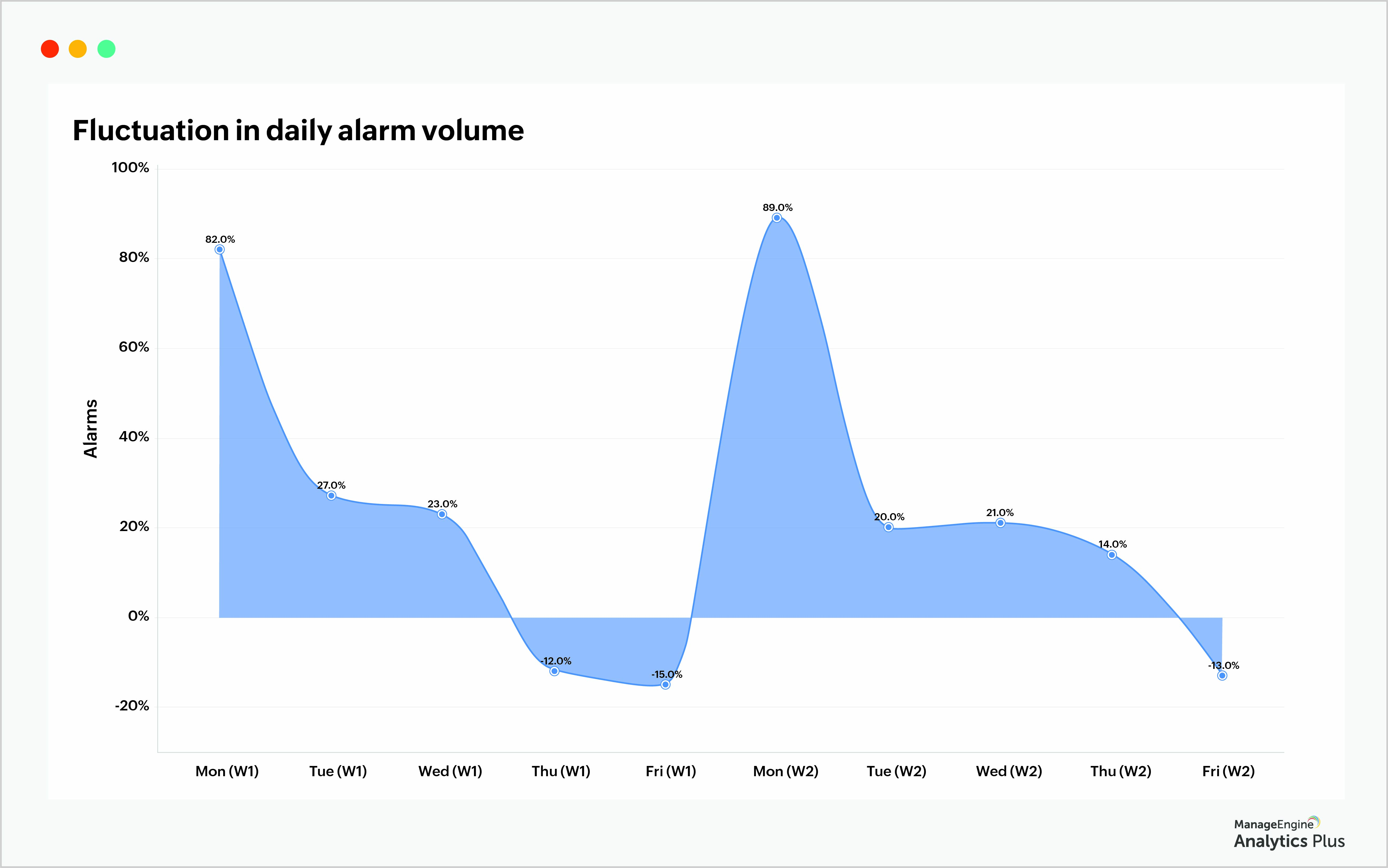
From the graph, it's clear that Mondays record a drastic fluctuation in alarm volume, indicating a repetitive activity happening on Mondays that's causing a spike in the number of alarms. Once recurring trends like these are identified, it's up to the organization to identify the root cause of recurring alarms and opt for either of these two solutions:
Prepare IT teams to tackle recurring alarms: Certain periodic activities can trigger an avalanche of alarms. For instance, scheduled patches are known to cause high CPU and memory usage during updates. In this case, IT teams can write workflows to create incident tickets automatically and assign them to the right technician to provide faster resolutions.
Permanently resolve the root cause of issues: Replacing or retiring problematic assets, streamlining operations, introducing fail-safe procedures for migration and upgradation of software and hardware assets, and establishing application-level and application-level visibility are a few ways to solve problems in your IT.
3. Replace degrading assets before they become problematic
Overtime, hardware devices tend to degrade leading up to failure or shutdowns that bring businesses to a screeching halt. Besides, older devices with lower configurations are often incompatible with the latest software updates, security patches, and issue fixes, leaving them vulnerable to further problems or security attacks. A better alternative is to track the performance of assets closely and watch out for problematic assets.
The report below helps identify problematic devices based on the number of total alarms generated by them in six months.
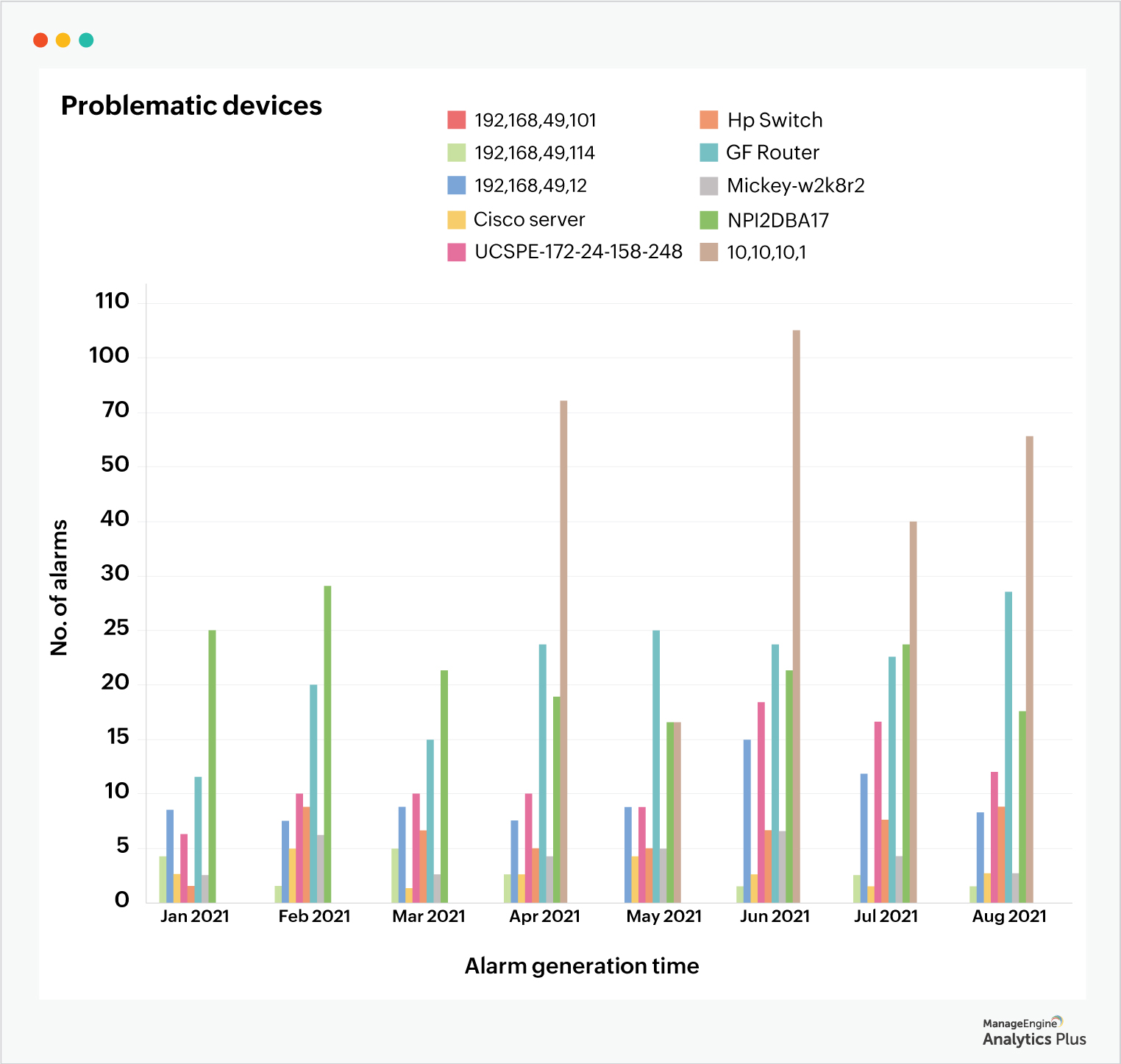
The next step is to distinguish between devices causing problems due to misconfiguration and devices malfunctioning due to end of life. For instance, a DNS server could be causing problems due to improper configurations which can be fixed with resetting the configuration; an internal server might be causing problems due to wear and tear, and can be replaced with a new one. Understanding this critical difference could be critical in identifying potential failure zones.
The above reports and dashboards were built using Analytics Plus, ManageEngine's AI-enabled IT analytics application. If you'd like to create similar reports using your IT data, try Analytics Plus for free.
Need to know more about analytics for IT operations? Talk to our experts to discover all the ways you can benefit from deploying analytics in your IT.
 Sailakshmi
SailakshmiSailakshmi is an IT solutions expert at ManageEngine. Her focus is on understanding IT analytics and reporting requirements of organizations, and facilitating blended analytics programs to help clients gain intelligent business insights. She currently spearheads marketing activities for ManageEngine's advanced analytics platform, Analytics Plus.




