Network fault management
Faults are inevitable in any network and it can cause serious disruptions unexpectedly if a proper mechanism is not implemented to handle them. This is why, IT admin teams depend on monitoring tools that have fault resolution capabilities.
A powerful network fault management tool helps in the following ways:
- It enables you to analyze network performance trends and receive alerts to resolve issues proactively.
- It allows you to locate network bottlenecks precisely.
- Quickens the process of fault resolution and minimizes overall the mean time to repair (MTTR).
- Sends instant notifications on network faults via email/SMS.
OpManager is a robust network fault monitoring solution that helps maintain ideal network performance with its powerful fault rectification capabilities.
Fault management in OpManager
By configuring the network discovery profile in OpManager, a comprehensive network management software, you can add the devices in your network in one go and approve them. The list of devices will be available on the inventory page, further you can drill down to gain deeper insights from the snapshot page (Navigate to Inventory -> Devices and then click on a device to view its snapshot page).
To ensure network uptime, OpManager pings the devices for availability (the poll interval can be defined by the user) and raises an alarm to notify the network admin when the device fails to respond after a ping. The severity of the alarm will rise when the device fails to respond even after multiple pings. There are 4 severity based threshold levels: attention, trouble, critical and rearm
Also, for each monitor (Eg: CPU Utilization) associated to a device, you can configure threshold levels. So that whenever, the value crosses the specified value given for a threshold level, OpManager will raise an alarm. For example, when the device violates the attention threshold level, OpManager will raise an alarm with attention severity and you can take corrective actions before it reaches the next severity level.
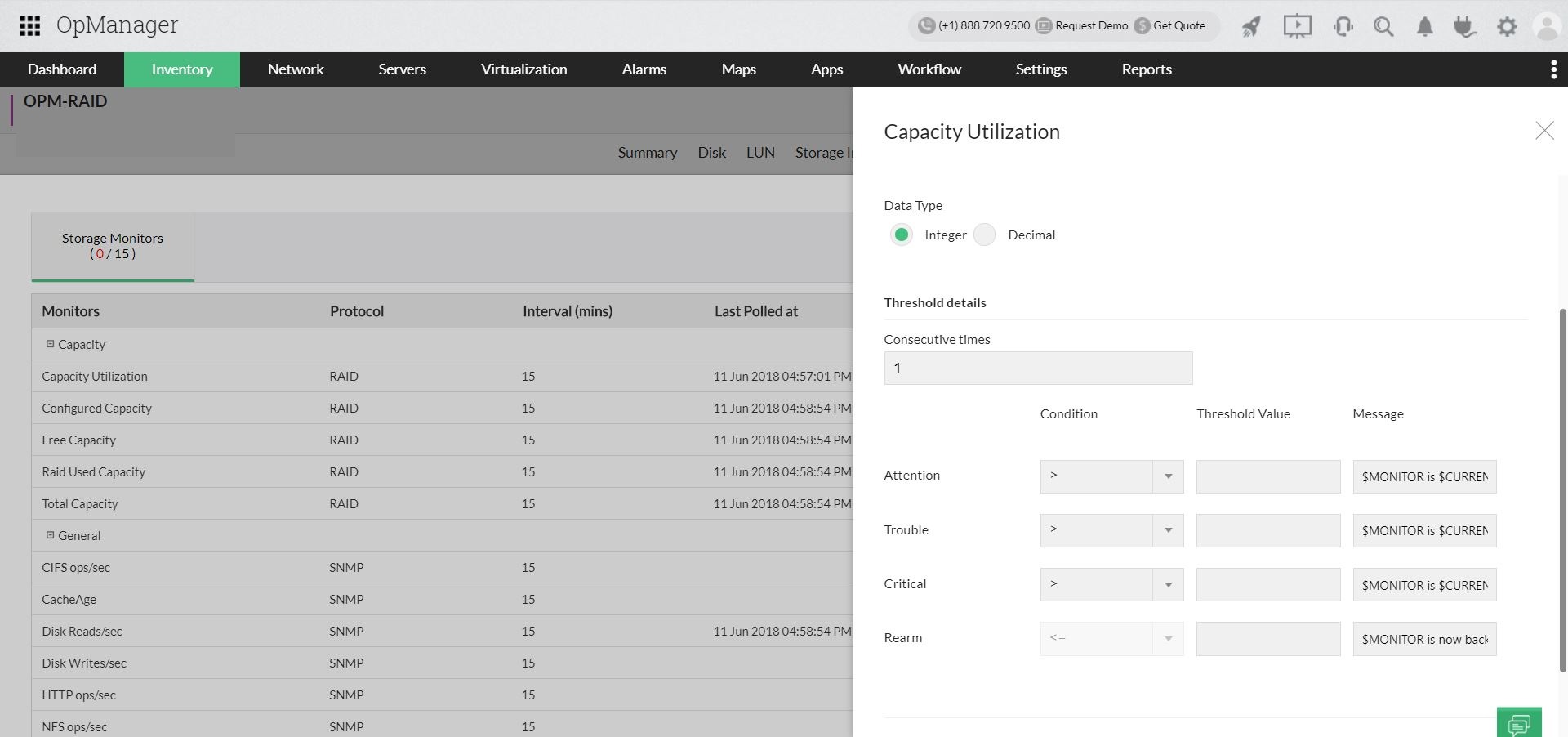
This enables you to proactively fix issues before they become a potential threat. The alarm raised for a threshold violation can be used to:
- Configure notification profile to get instant notification
- Configure alarm escalation rules to escalate unattended alarms
- Design and execute a workflow to rectify issues automatically
Alarm notifications
Configuring the notification profile is a way to handle the alerts that are raised. You can configure to receive the details of selective alarms as per your preference. While primarily it is used to send the details of an alarm to the IT admin/ admin team via an SMS or email, it can also be used to Run a Program/ Log a ticket and perform other actions.
OpManager's mobile platform is available for android and iOS users and enables you to monitor the entire IT infrastructure on your phone. The app allows you to get instant push notifications on device down and other performance degradation issues. You can also configure custom push notifications to get the status of critical servers so that you don't miss any network updates while being remote.
Alarm escalation
The Alarms tab on the UI provides a comprehensive list of the alarms and you can drill down to know more details about each alarm. There are a set of actions associated to each alarm: Acknowledge, Unacknowledge, Delete and Clear.
Sometimes when alarms are left unattended for long time, it can be escalated through Alarm escalation rules, wherein you can configure the criteria to escalate an alarm. This ensures that critical violations that go unattended due to human error doesn't hamper your network performance.
Alarm suppression
Sometimes when certain devices are kept under maintenance, OpManager may raise alerts considering that those devices are unavailable. To avoid this you can configure the alarm suppression rules, which allow you to prevent raising alarms for a defined period.
Alarm correlation rule
Your IT teams must deal with multiple alarms more often than not. By correlating an alarm correlation rule in OpManager, you can contextually combine alarms of different sources, helping you reduce alarm noise to a greater extent. You can associate the rule to a notification profile and implement this rule either 24/7 or during a specified time window. You can also configure workflows when the criteria for the correlation rule have been reached.
Resolve network faults automatically using workflow
Workflow in OpManager greatly reduce the mean time to repair and accelerates fault resolution.
Workflows are code-free, easy to implement solutions that automate certain routine actions. You can simply design a workflow to perform corrective actions after fault identification or a threshold violation or any other repetitive task.
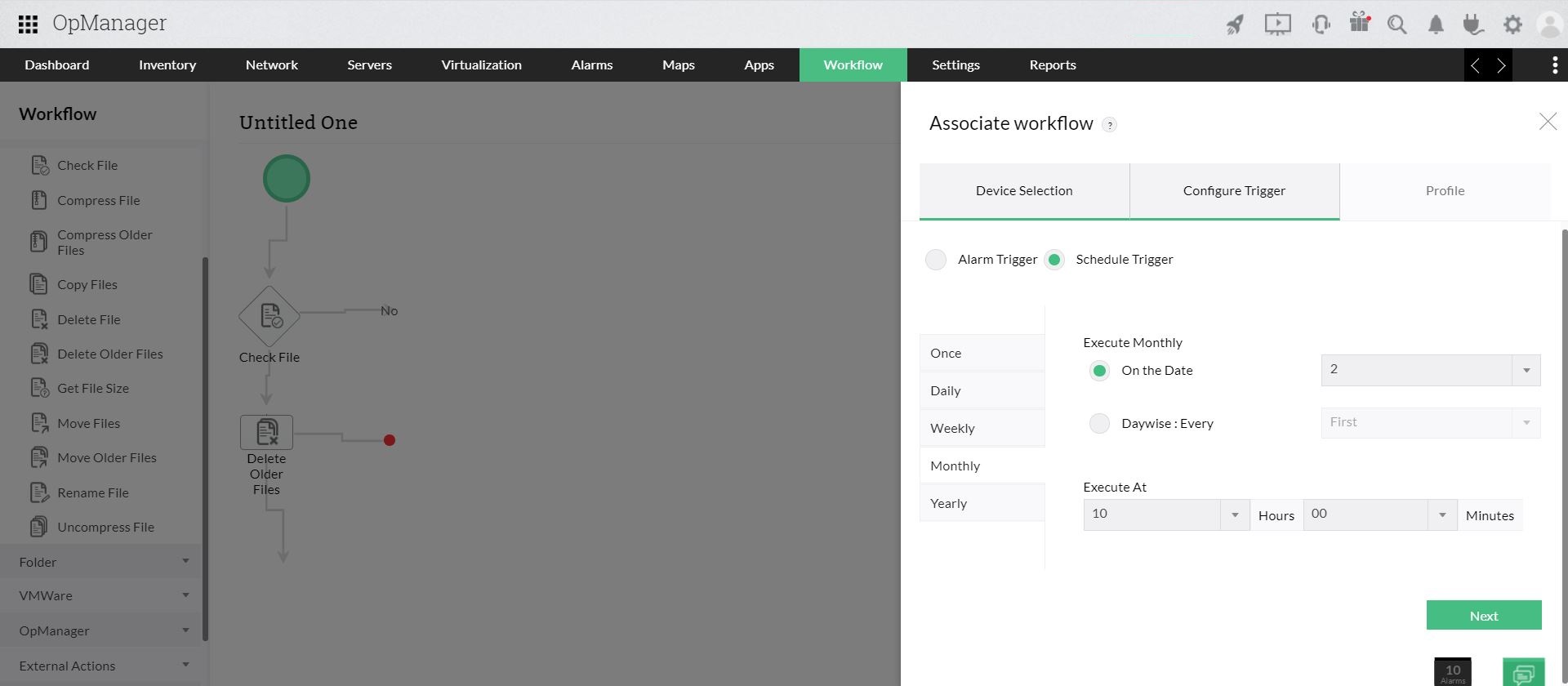
For example, you can design a workflow to delete files that are older than 30 days to free up space in your machine. The workflow can be scheduled to be executed once every month and this will automate the deletion process when the criteria (30 days older) is met.
You can also configure to raise alarms of certain faults as tickets in ServiceDesk Plus. So that, the issue is escalated to the technical team, and resolved in less time. Remote monitoring of faults is also possible with Workflows as you can automate actions which will be performed even when the IT admin team is not at the location.
Note:OpManager seamlessly integrates with other ITSM tools like SDP OP, SDP Cloud, ServiceNow, Jira ServiceDesk, AlarmsOne etc. OpManager also supports webhooks and enables integration with third party applications like Telegram. Learn more about the integrations available in OpManager.