- HOME
- ITSM Analytics
- Surviving the next downtime with proactive IT operations—Part 2
Surviving the next downtime with proactive IT operations—Part 2
- Last Updated: July 1, 2024
- 505 Views
- 3 Min Read

In the first part of this blog, we discussed three ways IT teams can tackle downtime and become proactive in their operations. In this blog, we'll continue to look at more ways IT teams can become proactive using IT operational analytics.
1. Forecast storage capacity needs
Netflix saves $1 billion per year on customer retention by effectively storing and analyzing vast amount of its customer data. Big data volumes double every year, and unless organizations find ways to effectively store and use that data, they stand to lose millions. With millions at stake, it's up to the IT teams to forecast storage capacity needs and plan resource purchases so that resources are available for use on time.
The report below illustrates the trends of disk, CPU, and memory utilization over the past year where you can see that memory utilization has remained fairly consistent over the past year, while CPU and disk utilization have experienced inconsistencies and sudden spikes that can attributes to change implementation processes during which systems tend to take up additional storage for backing up applications.
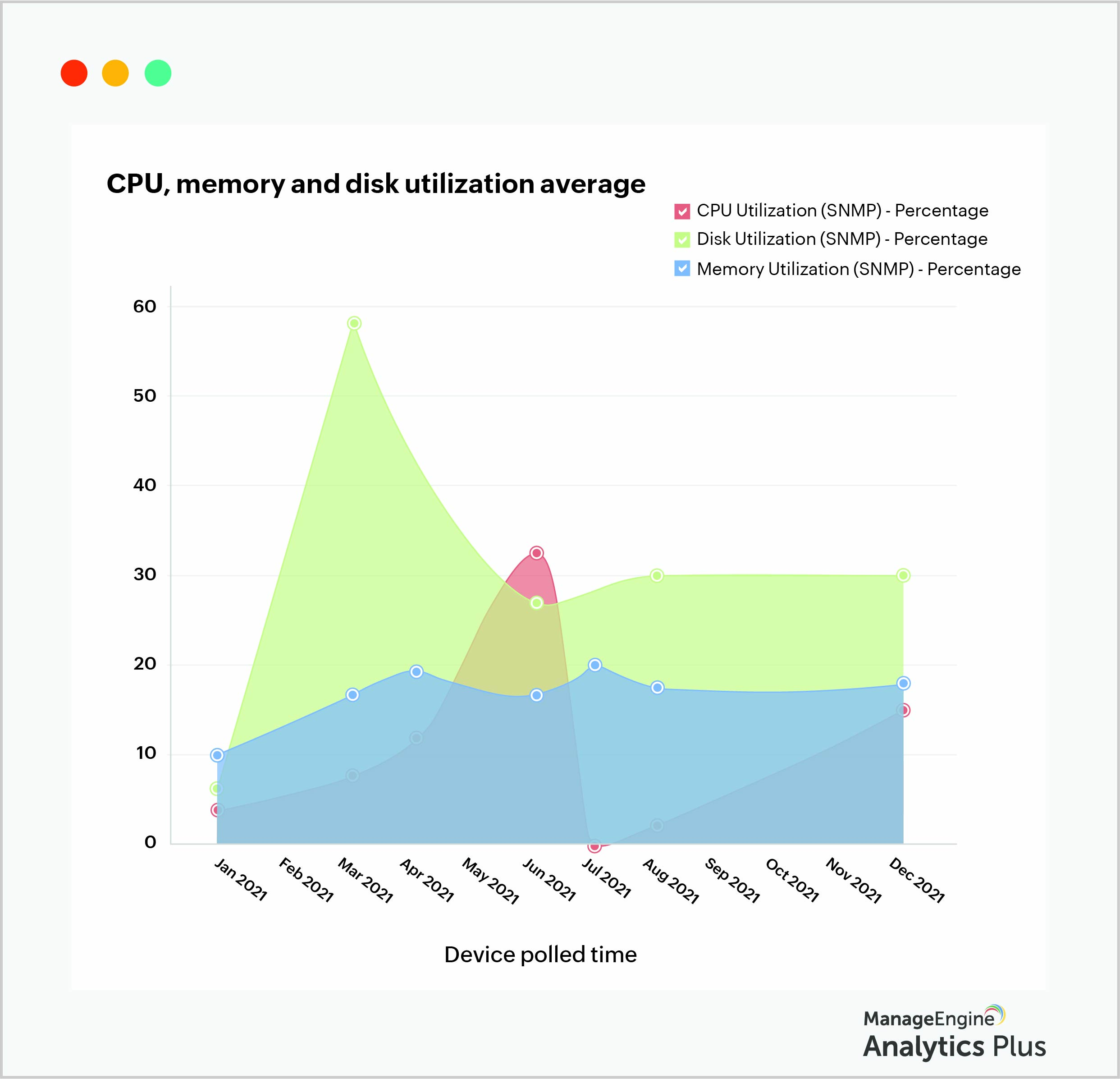
Tracking memory and disk utilization trends can reveal such trends in your storage requirements, and can also help you forecast your organization's storage capacity needs.
2. Avoid network disasters
Don't wait until the next disaster to start planning your disaster prevention and recovery plans. Closely monitor network devices for availability, watch out for ones that are frequently down, segment downed devices into mission-critical and non-mission critical devices, and then build fail-safes for emergencies.
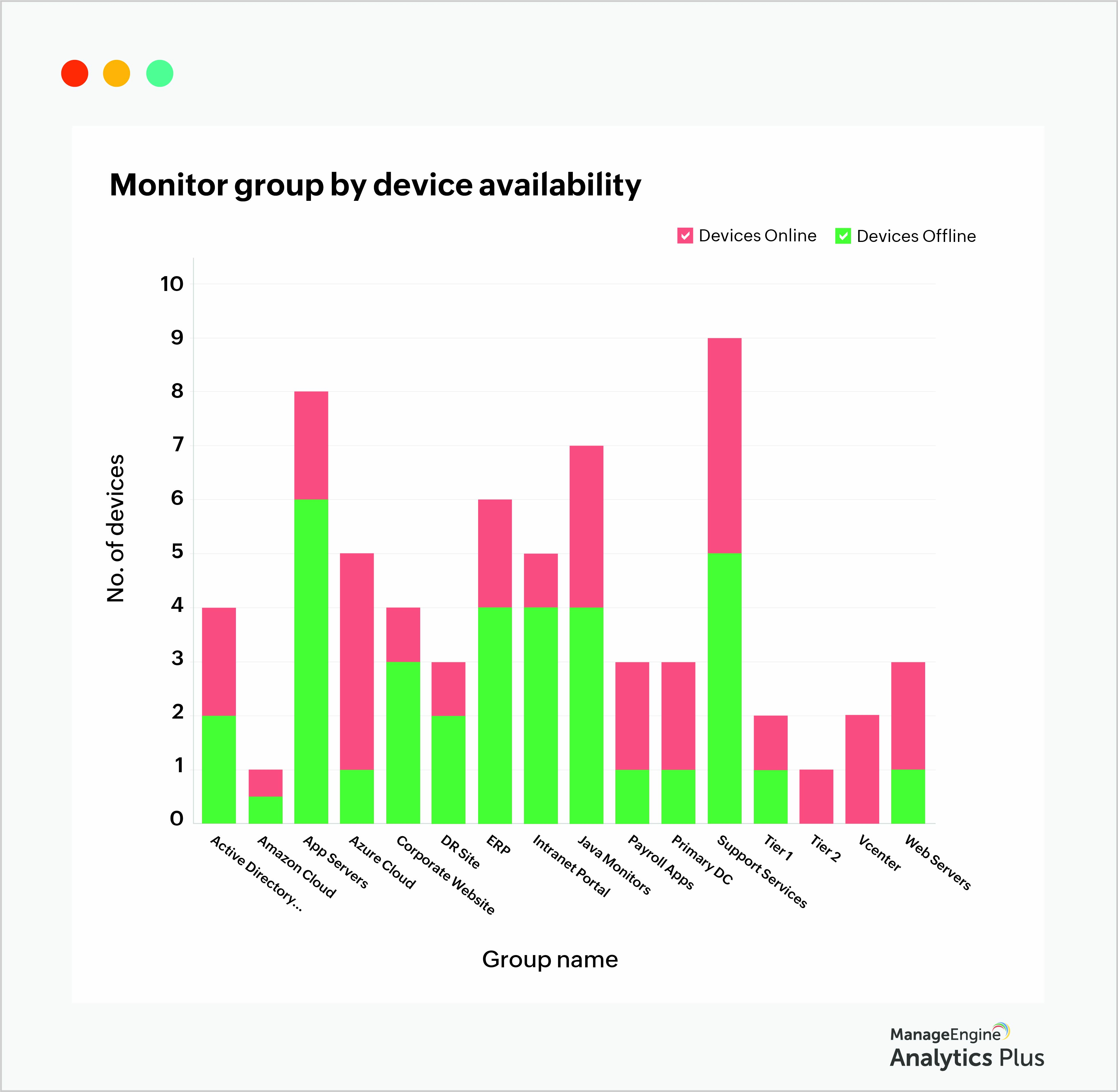
The report above you a list of devices available under each monitor group that shows you the network service quality, and enables you to estimate the impact on business when a device goes offline. This can help you pick your recovery protocol from this list:
Build resiliency into the network either using dynamic routing protocols or virtual overlay network technologies to provide real-time failover across hardware and links.
Opt for rapid failover technologies designed and maintained by cloud service providers.
Periodically backup network configurations making it easier to switch to software-centric cloud infrastructure in times of crisis.
Purchase cold spares—hardware components to serve as standbys in case of an emergency.
3. Unify IT service and operations management to build resilience
When all options fail and when disaster strikes, ensure your teams are resilient and capable of restoring services quickly. For this, you need complete visibility into the IT department and not siloed vision into IT service management and IT operations management.
The combined ITSM and ITOM dashboard below showcases critical metrics that can help achieve operational efficiency. It's clear that alarm volumes and request volumes almost mirror each other, making it easier to quickly prioritize alarms based on business impact, and divert personnel to where they're most needed.
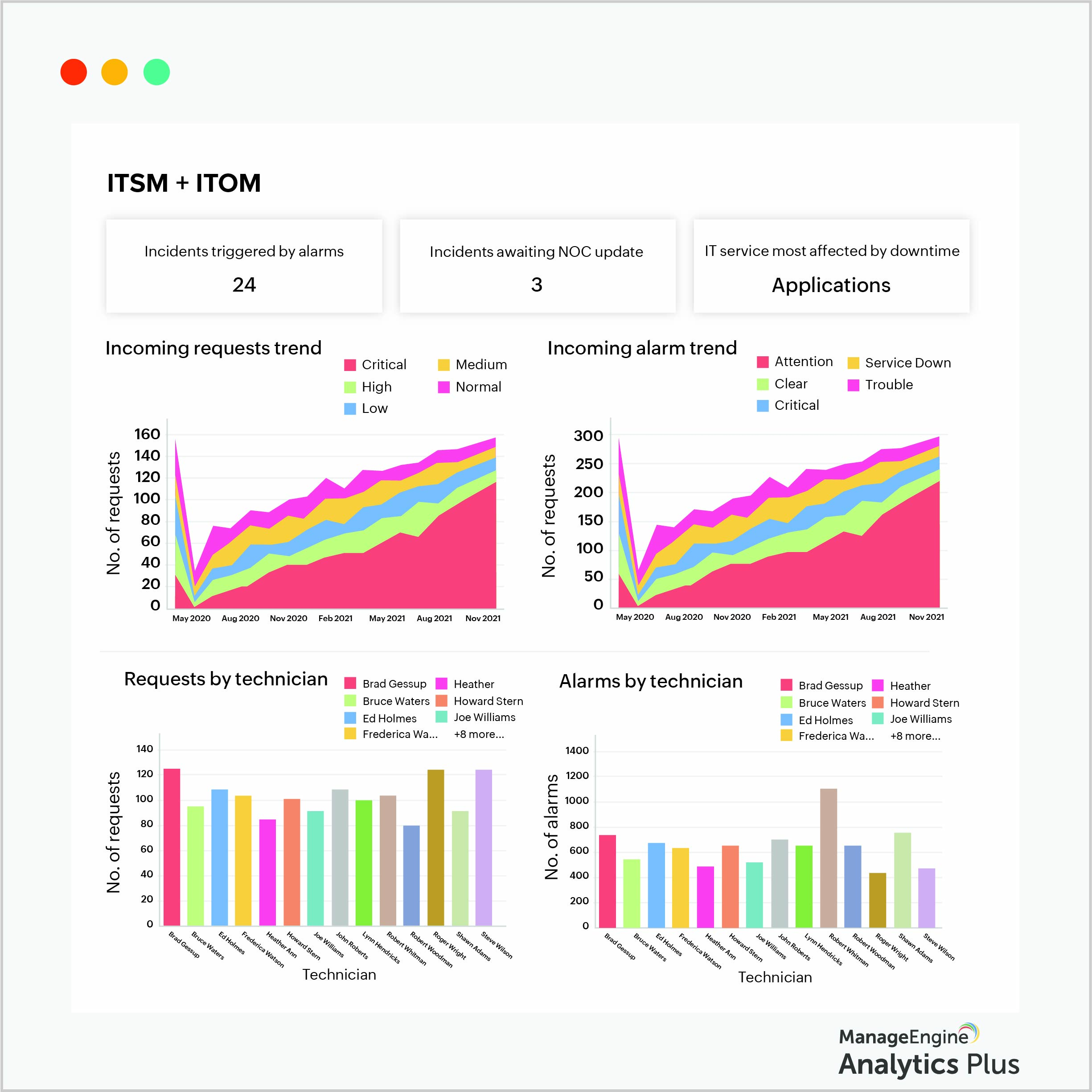
For many IT teams, being proactive in operations management can be a challenge. However, proactive operations offers several benefits, such as a faster incident resolutions and reduced MTTR, increased uptime, improved resource utilization, lower costs, and overall better experiences for end users.
These reports were built using Analytics Plus, ManageEngine's AI-enabled IT analytics application. If you'd like to create similar reports using your IT data, try Analytics Plus for free.
Need to know more about analytics for IT operations? Talk to our experts to discover all the ways you can benefit from deploying analytics in your IT.
 Sailakshmi
SailakshmiSailakshmi is an IT solutions expert at ManageEngine. Her focus is on understanding IT analytics and reporting requirements of organizations, and facilitating blended analytics programs to help clients gain intelligent business insights. She currently spearheads marketing activities for ManageEngine's advanced analytics platform, Analytics Plus.




