Kenapa Network dan Aplikasi Lambat? Cara Monitoring CPU, Process, dan Latency

Keluhan mengenai jaringan dan aplikasi yang lambat sering kali hanya berujung pada dugaan tanpa dasar teknis. Hal ini dikarenakan minimnya visibilitas terhadap jaringan (latensi jaringan atau packet loss) dan performa infrastruktur server (CPU, memory, atau disk). Padahal, kegagalan mengidentifikasi root cause secara tepat dapat meningkatkan biaya operasional akibat downtime.
Inilah mengapa, tim IT perlu menerapkan monitoring yang memberikan visibilitas end-to-end untuk menghindari analisis yang bersifat spekulatif, sekaligus menjaga stabilitas transmisi data dan memastikan pengalaman pengguna tetap optimal.
Jaringan atau aplikasi lambat? Masalahnya tidak selalu pada koneksi
Saat aplikasi mendadak tidak responsif atau jaringan berjalan lambat, dugaan pertama biasanya langsung mengarah pada kondisi konektivitas yang buruk. Realitanya, dalam operasional sehari-hari hambatan performa sering dipicu oleh keterbatasan dalam monitoring pada sumber daya sistem komputer.
Tanpa monitoring real-time yang terintegrasi, tim IT sulit melakukan troubleshooting secara akurat karena kurangnya visibilitas terhadap beberapa kendala berikut:
Lonjakan beban kerja: Aplikasi melambat akibat proses batch yang berjalan di jam sibuk (rush hour).
Antrean database: Permintaan data menumpuk dan memperlambat waktu respons aplikasi, meskipun koneksi jaringan dalam kondisi normal.
Eksploitasi sumber daya: Penggunaan CPU utilization dan memory utilization yang tidak terpantau secara mendalam.
Itulah sebabnya, dalam melakukan analisis root cause, tim IT perlu memastikan seluruh sumber daya sistem terpantau dalam satu tampilan yang terintegrasi. Dengan cara ini, tim IT dapat mengidentifikasi root cause secara cepat dan tepat sasaran sebelum menyimpulkan bahwa konektivitas adalah satu-satunya penyebab kelambatan.
CPU monitoring: Indikator awal bottleneck
Sebagai langkah awal dalam mengidentifikasi performa sistem, monitoring CPU menjadi salah satu indikator penting untuk diperhatikan. Sebab, dalam operasional server, CPU menangani berbagai beban kerja intensif yang antara lain:
Pemrosesan query database: Menjamin kecepatan respons data pada aplikasi bisnis.
Pengelolaan virtual machine pada hypervisor: Memastikan stabilitas lingkungan virtualisasi.
Penyaringan spam email: Mengamankan traffic komunikasi dari konten berbahaya.
Pemrosesan tabel routing: Menjaga keberhasilan sistem dalam mengarahkan paket data secara efisien.
Pengelolaan firewall ACL: Memastikan keamanan akses jaringan melalui kontrol akses yang tepat.
Terminasi SSL pada load balancer: Menangani enkripsi dan dekripsi data untuk keamanan transmisi.
Dengan kompleksitas beban kerja CPU, tim IT perlu melakukan monitoring CPU untuk mengidentifikasi aktivitas proses di latar belakang serta menganalisis konsumsi sumber daya dari setiap aplikasi guna memahami dampaknya terhadap stabilitas jaringan secara menyeluruh.
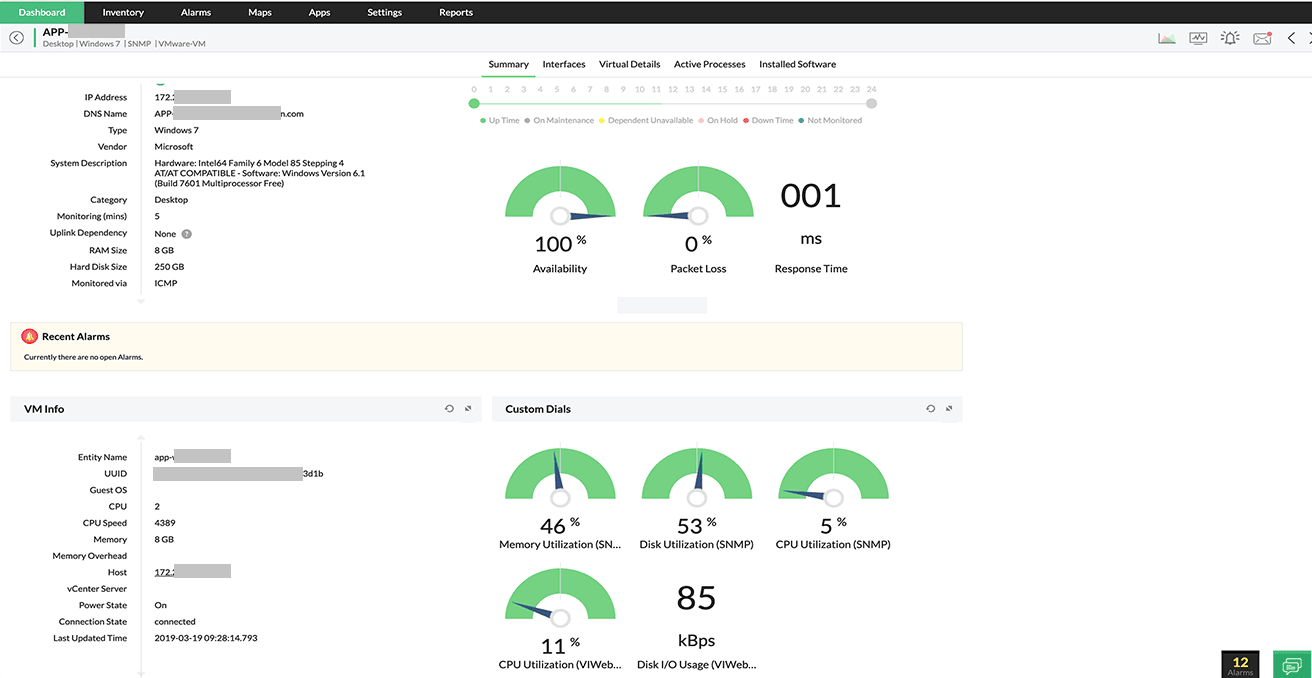
Sebab, CPU usage yang tinggi tidak hanya memperlambat aplikasi, tetapi mengancam stabilitas sistem. Tim IT perlu mewaspadai beberapa metrik berikut:
Persentase waktu prosesor (% processor time): Indikator utama yang menunjukkan beban kerja aktual CPU. Jika metrik ini terus-menerus mendekati 100%, sistem akan kehilangan kemampuan untuk menangani tugas mendadak.
Panjang antrian (Queue length): Saat prosesor mencapai threshold, thread yang dieksekusi harus mengantre. Hal ini secara langsung meningkatkan waktu respons aplikasi bagi pengguna.
Monitoring memori kritis: Penggunaan CPU tinggi sering memicu pemanfaatan memori berlebih, yang berpotensi menyebabkan server crash atau kegagalan proses.
Melalui monitoring CPU yang akurat, tim IT dapat memitigasi risiko downtime, memaksimalkan utilisasi hardware, serta mencapai efisiensi biaya operasional yang lebih baik
Memory dan disk: Sumber masalah yang sering terlewat
Namun, tidak semua masalah performa berasal dari beban CPU yang tinggi. Dalam banyak kasus, memory dan disk justru menjadi root cause utama penurunan performa. Saat kapasitas RAM mulai penuh, sistem akan memindahkan sebagian beban ke disk melalui mekanisme swapping. Karena disk bekerja jauh lebih lambat dibanding RAM, lonjakan disk I/O sering berubah menjadi bottleneck.
Bottleneck ini menyebabkan penggunaan CPU bisa terlihat normal, sementara aplikasi berjalan lambat. Kondisi ini biasanya terjadi karena:
Disk I/O tinggi atau database query yang kompleks: CPU tidak bekerja keras secara kalkulasi tetapi disk I/O melonjak drastis akibat query scanning pada tabel besar tanpa indeks yang optimal.
Kebocoran memori (memory leak) tersembunyi: Kondisi ini memaksa sistem melakukan swapping ke disk secara terus-menerus, yang menyebabkan latensi halaman web membengkak meskipun beban prosesor rendah.
Untuk menghindari kondisi ini, tim infrastruktur IT perlu memonitor CPU, memory, dan disk secara terpadu. Melalui monitoring yang sinkron, tim IT dapat mengidentifikasi root cause dengan lebih cepat. Sehingga, dapat diketahui apakah lambatnya aplikasi disebabkan oleh kurangnya kapasitas memori atau adanya kegagalan pada perangkat penyimpanan yang tidak sanggup lagi menangani beban kerja tinggi.
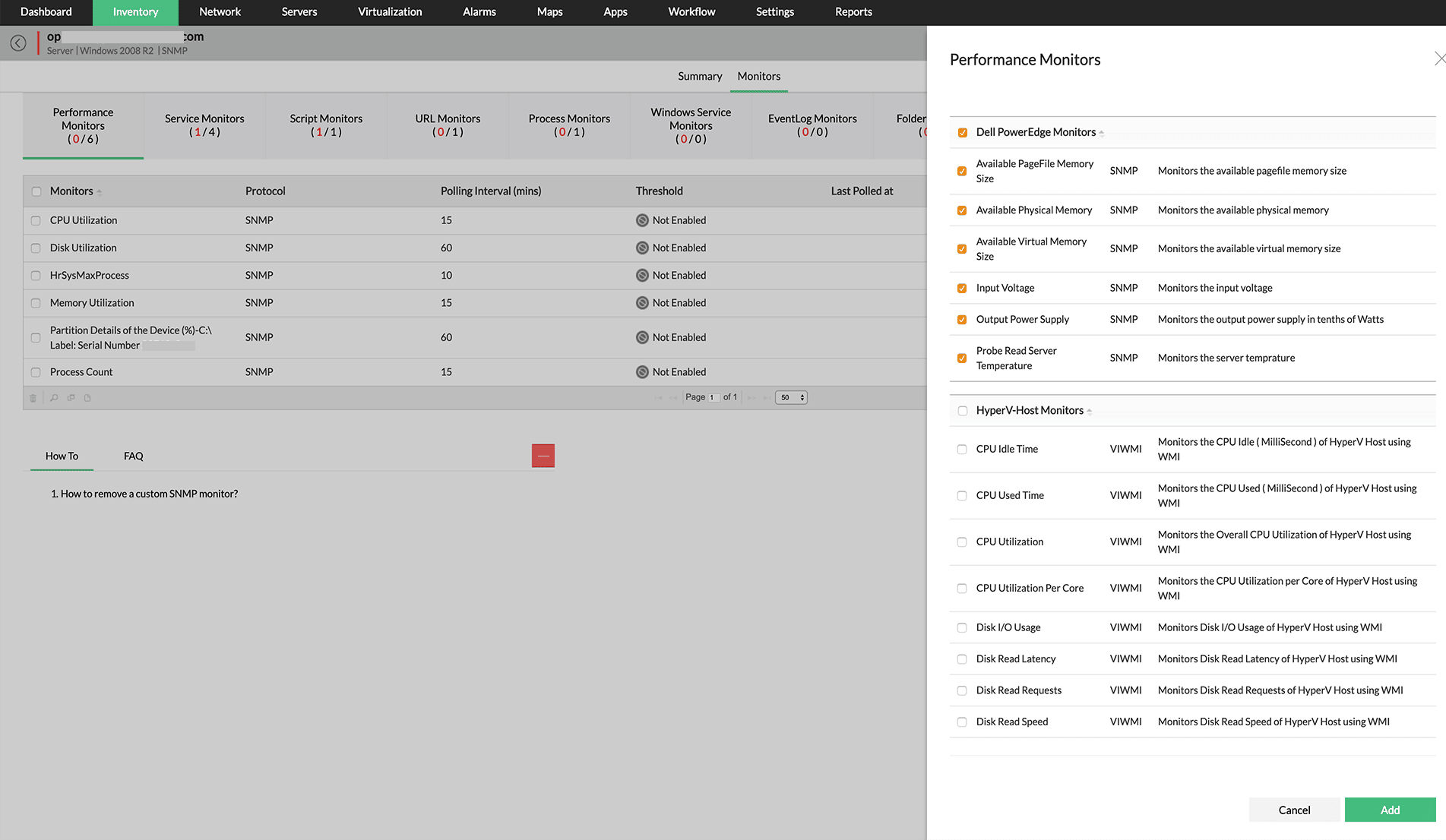
Process monitoring: Menemukan aplikasi penyebab bottleneck
Dalam banyak kasus, terdapat proses tertentu yang mengonsumsi sumber daya secara berlebihan (resource hog) dan memicu masalah performa. Kondisi ini sering muncul ketika proses backup yang berjalan di jam operasional, skrip otomatis yang tidak terjadwal, atau aplikasi yang mengalami kebocoran memori (memory leak).
Di sinilah pentingnya proses monitoring yang membantu tim IT untuk melihat secara detail aplikasi atau layanan apa saja yang sedang berjalan serta konsumsi sumber daya masing-masing proses. Tanpa pemantauan di level proses, tim IT hanya melihat lonjakan penggunaan sumber daya secara keseluruhan tanpa mengetahui aplikasi mana yang bertanggung jawab atas inefisiensi tersebut. Sedangkan, dengan melakukan process monitoring tim IT dapat:
Mendeteksi resource hog secara real-time: Menemukan aplikasi yang menggunakan persentase CPU secara tidak wajar.
Memitigasi memory leak: Mengidentifikasi aplikasi yang terus mengonsumsi memori tanpa melepaskannya kembali, sehingga mencegah kegagalan sistem total
Mengawasi keamanan infrastruktur: Memantau adanya proses anomali yang bisa menjadi indikasi adanya aktivitas siber mencurigakan.
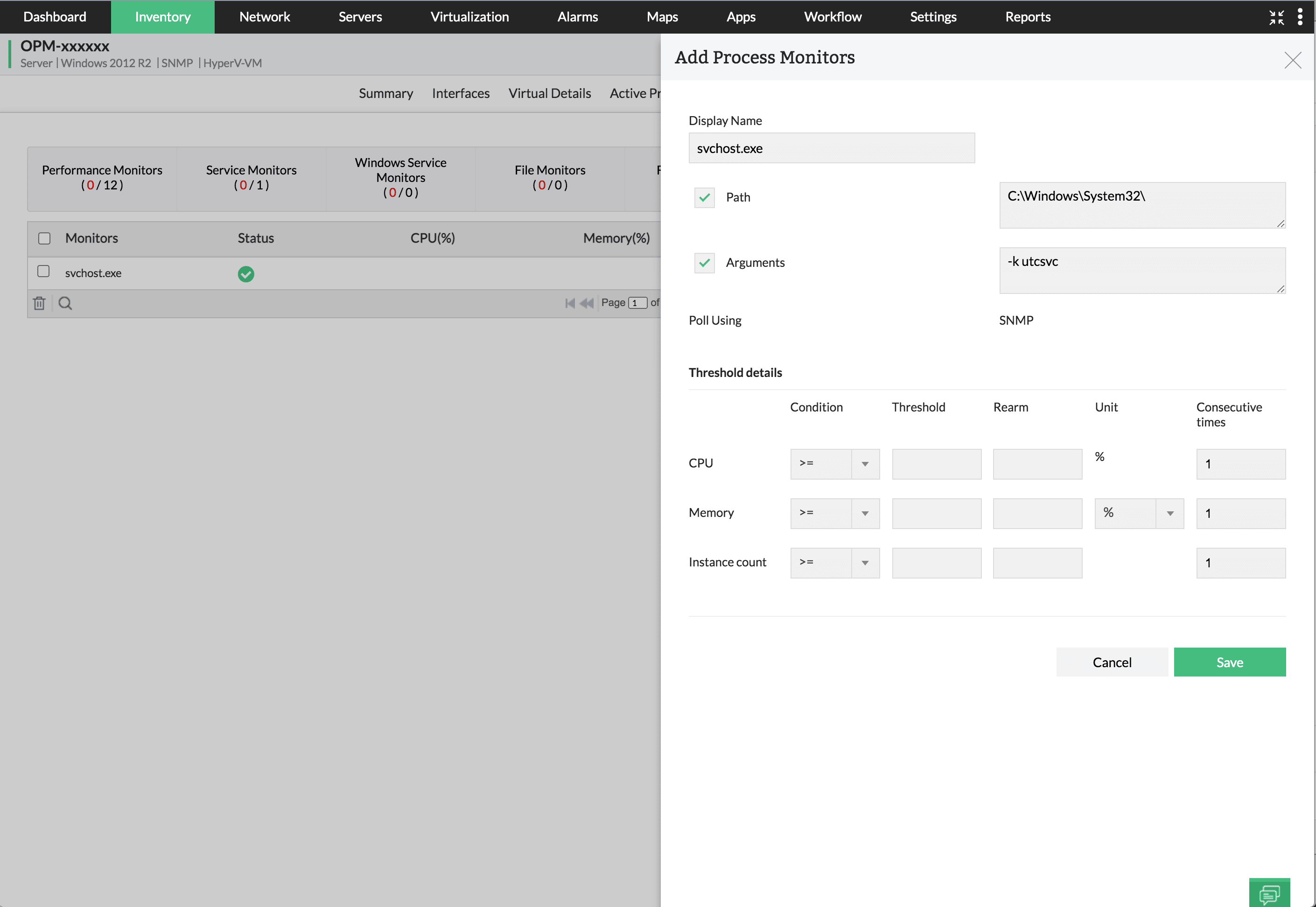
Dengan server monitoring yang fokus pada aktivitas proses, tim operasional IT mengambil langkah proaktif untuk menghentikan atau mengoptimalkan proses bermasalah. Langkah ini membantu tim IT menjaga stabilitas seluruh ekosistem sistem.
Network Latency Monitoring: Saat jaringan menjadi penghambat
Meskipun sumber daya server terlihat dalam kondisi optimal, pengguna tetap merasakan aplikasi berjalan lambat akibat latensi jaringan. Latensi jaringan mengacu pada waktu tempuh yang dibutuhkan oleh paket data dari sumber ke tujuan. Dengan network latency monitoring secara proaktif, membantu tim IT untuk:
Menjaga pengalaman pengguna dan produktivitas: Kenaikan latensi sekecil 0,1 detik langsung memperburuk pengalaman pengguna dan menurunkan efisiensi kerja.
Mengoptimalkan transmisi data: Latensi rendah sangat krusial untuk menjamin kualitas konektivitas dan kecepatan pengiriman data yang stabil di seluruh infrastruktur.
Meningkatkan efisiensi jalur komunikasi: Monitoring proaktif memastikan jalur komunikasi data, baik pada jaringan lokal maupun WAN, selalu beroperasi pada performa terbaiknya.
Memastikan kualitas layanan VoIP dan video: Mencegah terjadinya gangguan suara (jitter) dan panggilan terputus (dropped calls) yang dapat mengganggu koordinasi bisnis pada platform komunikasi.
Mempercepat identifikasi masalah: Membantu tim IT membedakan secara cepat apakah kelambatan sistem bersumber dari proses internal server atau kendala pada infrastruktur jaringan.
Dengan visibilitas terhadap latency, tim IT dapat mengambil langkah lebih cepat sebelum gangguan jaringan berdampak luas pada produktivitas dan layanan bisnis.
Monitoring terintegrasi untuk Root Cause Analysis
Dalam praktiknya, tim IT tidak dapat menyelesaikan masalah performa secara efektif jika memonitor setiap komponen secara terpisah. Tim IT hanya dapat melakukan root cause analysis secara cepat dan akurat jika memiliki visibilitas menyeluruh. Dengan mengintegrasikan monitoring CPU, proses aplikasi, dan latensi jaringan ke dalam satu dasbor, tim IT memahami korelasi antar data dengan lebih jelas.
Pendekatan yang terstruktur membantu tim IT bekerja lebih efektif saat melakukan troubleshooting.
Penurunan MTTD (Mean Time to Detect): Tim IT dapat mengurangi waktu deteksi masalah secara signifikan dengan melihat korelasi antara beban server dan trafik jaringan dalam satu tampilan.
Insight untuk optimasi berkelanjutan: Tim IT tidak hanya sekadar mengumpulkan metrik mentah, tetapi mendapatkan insight mendalam untuk melakukan penyesuaian infrastruktur secara proaktif.
Efisiensi manajemen sumber daya: Tim IT dapat memastikan setiap komponen hardware bekerja pada kapasitas optimal tanpa risiko beban berlebih yang tidak terdeteksi.
Dengan strategi server performance management, tim IT dapat berpindah dari pola troubleshooting reaktif ke pendekatan yang lebih terstruktur dan proaktif dalam menjaga stabilitas layanan.
Kesimpulan
Pada akhirnya, stabilitas infrastruktur IT sangat bergantung pada kemampuan tim dalam memantau hambatan jaringan dan limitasi hardware secara objektif. Tanpa visibilitas menyeluruh terhadap metrik kritis seperti disk I/O, threshold CPU, hingga trafik VoIP, proses troubleshooting hanya akan menjadi perkiraan yang membuang waktu dan biaya operasional.
Melalui strategi manajemen performa server yang terpusat, organisasi dapat mempercepat root cause analysis dan mengoptimalkan kapasitas hardware secara tepat sasaran. Implementasi solusi monitoring yang komprehensif bukan lagi sebuah pilihan, melainkan keharusan. Anda bisa mencoba OpManager untuk melihat langsung bagaimana solusi ini membantu memastikan pengalaman pengguna yang optimal sekaligus menjaga keunggulan kompetitif bisnis.