Configuración de Ollama en LLM locales
Requisitos del sistema
- Al menos 8 GB de RAM (se recomiendan 16 GB para un mejor rendimiento).
- 4 GB de espacio libre en disco para la instalación base.
- Espacio adicional en disco para los modelos (Mistral normalmente requiere entre 4 GB y 5 GB).
Proceso de instalación
Para usuarios de Windows:
1. Descargue el instalador de Ollama desde https://ollama.ai/download/windows
2. Ejecute el instalador .msi descargado y siga el asistente de instalación.
Para usuarios de macOS:
1. Descargue el archivo .dmg de Ollama desde https://ollama.ai/download/mac
2. Abra el archivo .dmg descargado y arrastre Ollama a la carpeta Aplicaciones.
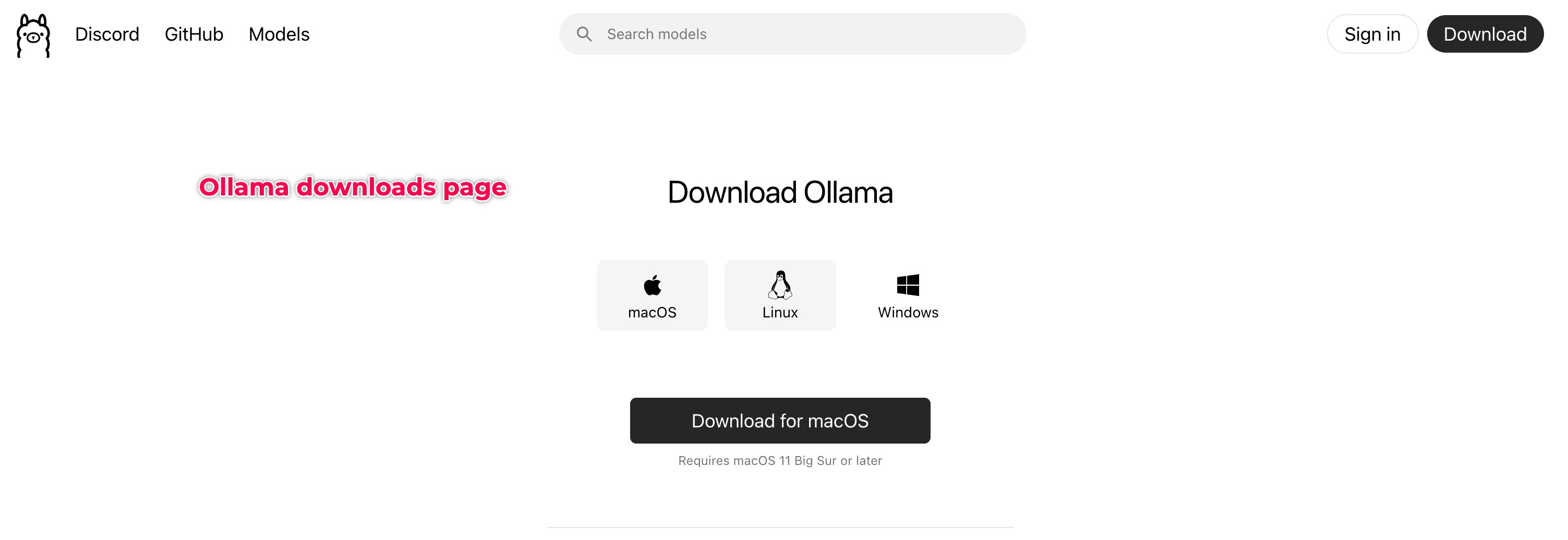
3. Para configurar Ollama,
- Abra Ollama en la carpeta Aplicaciones.
- Otorgue los permisos necesarios.
- Ahora podrá ver el ícono de Ollama  en la barra de menú de su dispositivo.
en la barra de menú de su dispositivo.
Para usuarios de Linux:
1. Instale Ollama usando el script de instalación oficial.
2. Inicie el servicio de Ollama.
Ejecución del modelo Mistral
Después de instalar Ollama, siga estos pasos para descargar y ejecutar el modelo Mistral:
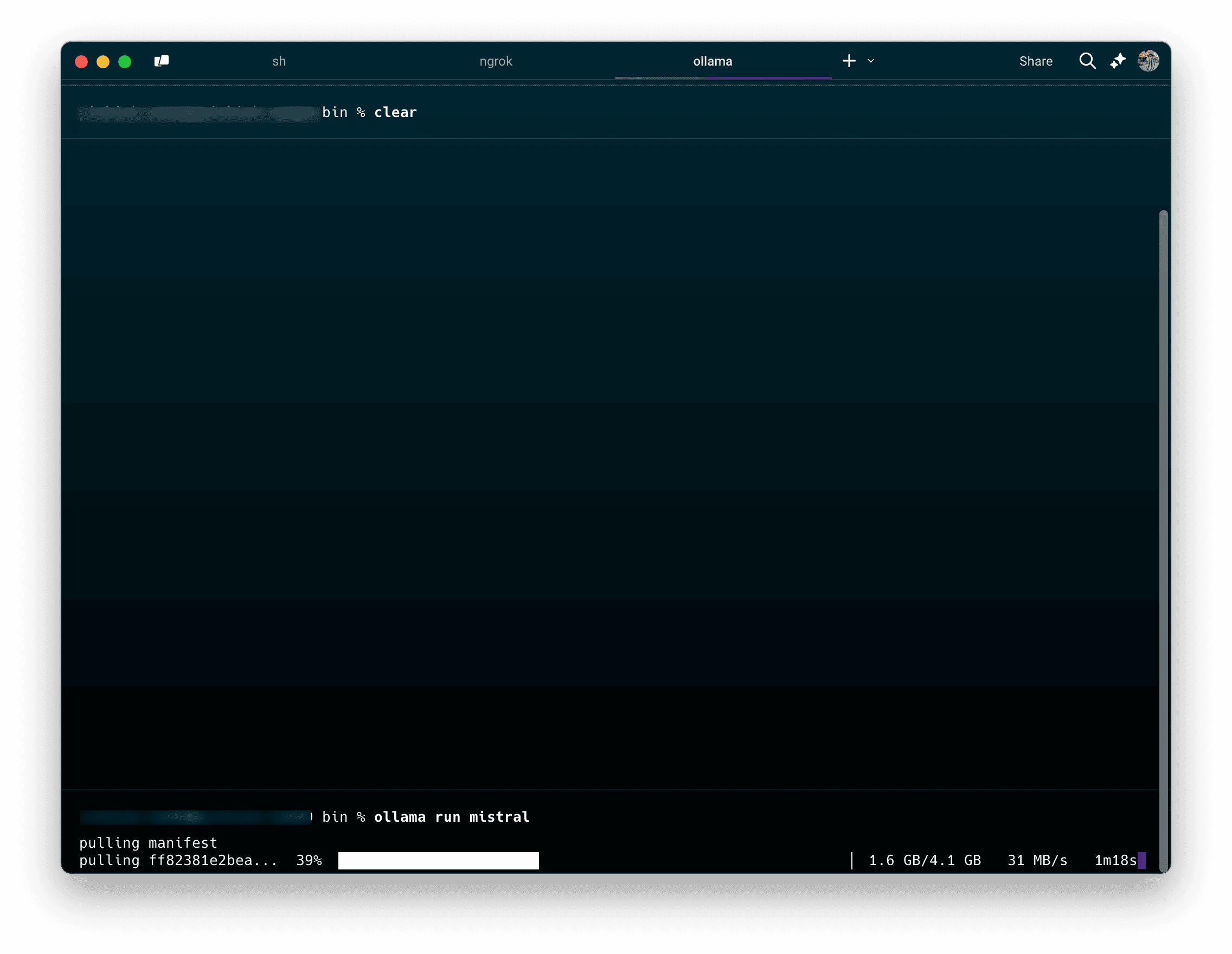
1. Abra su terminal (Símbolo del sistema o PowerShell en Windows, Terminal en macOS/Linux).
2. Descargue el modelo Mistral.
Ahora se descargarán los archivos del modelo (aproximadamente entre 4 GB y 5 GB).
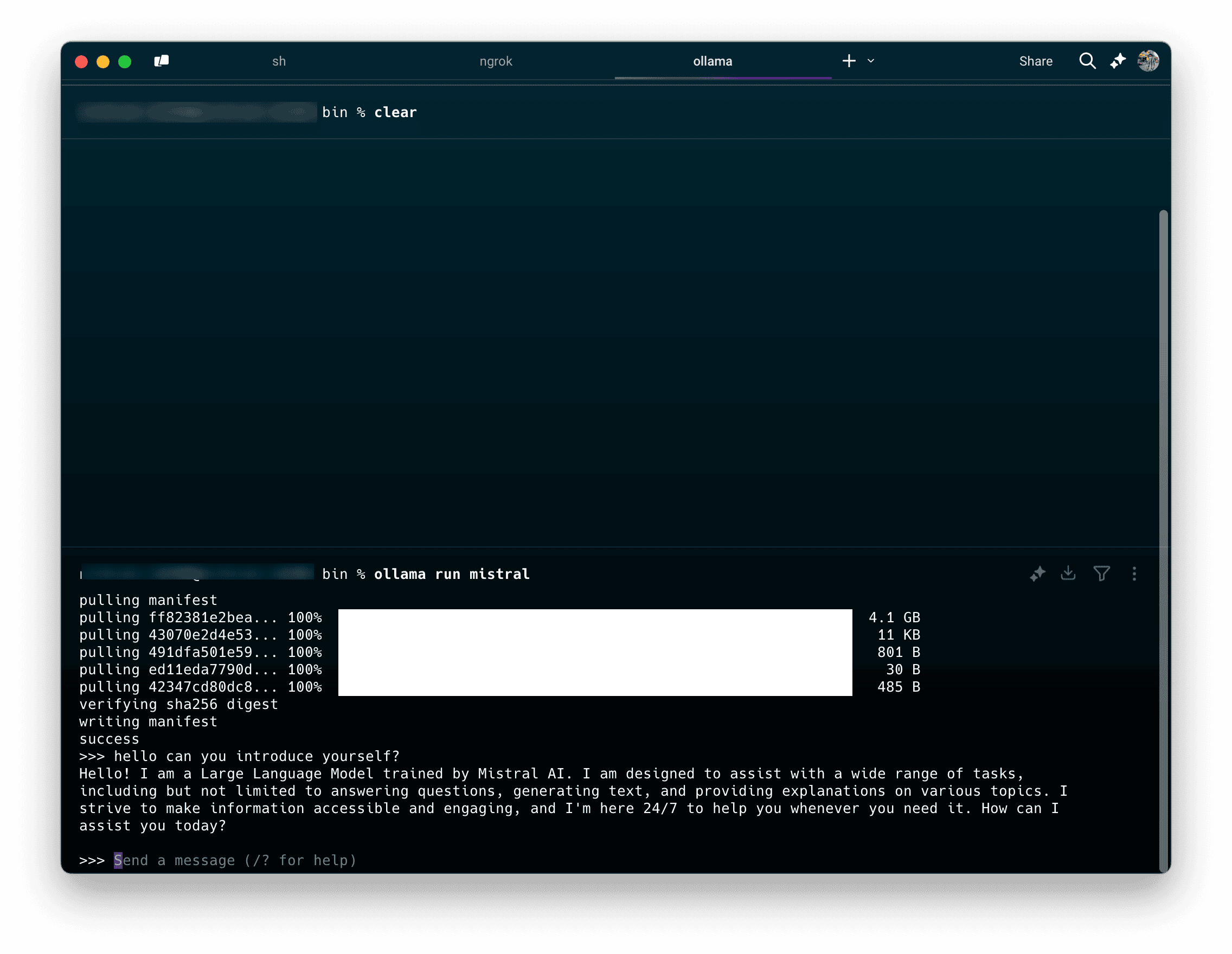
3. Pruebe el modelo con una instrucción simple para verificar la instalación.
Respuesta de ejemplo
Tamaño de la ventana de contexto en Mistral
El tamaño de la ventana de contexto en modelos de lenguaje como Mistral determina cuánto texto puede procesar y recordar el modelo durante una conversación o tarea.
Piense en ello como la memoria de trabajo del modelo, es decir, la cantidad de conversaciones previas que utiliza para generar una respuesta.
Puede modificar el tamaño de la ventana de contexto al ejecutar el modelo.
Limitación
Los tamaños más grandes de ventana de contexto conllevan mayores costos computacionales. Requieren más memoria del sistema y, por lo tanto, ralentizan el tiempo de respuesta del modelo.
En sistemas con recursos limitados, como laptops o computadoras antiguas, quizá desee reducir el tamaño del contexto para mejorar el rendimiento.
Tamaños de ventana de contexto más usados
2048 tokens: Adecuado para conversaciones simples y tareas básicas. Óptimo para sistemas con RAM limitada y respuestas de alta prioridad.
4096 tokens: Una opción equilibrada para la mayoría de los casos de uso, ya que proporciona una buena retención del contexto mientras mantiene un rendimiento razonable.
8192 tokens: Ideal para tareas complejas que requieren un contexto amplio, como análisis de documentos o discusiones técnicas. Requiere más recursos del sistema.
Al elegir un tamaño de ventana de contexto, tenga en cuenta tanto las capacidades de su hardware como los requisitos de su caso de uso. Supervise el uso de memoria de su sistema y el rendimiento del modelo para encontrar el equilibrio óptimo para sus necesidades específicas.
Variables de entorno
Ollama admite varias variables de entorno que le permiten personalizar su comportamiento. Dos de las variables importantes son OLLAMA_HOST y OLLAMA_MODELS.
OLLAMA_HOST
La variable OLLAMA_HOST se define para especificar en qué puerto la API de Ollama debe escuchar conexiones desde un host.
(el número de puerto se establece en 11434 de forma predeterminada)
Esta configuración es fundamental cuando desea acceder a Ollama desde otras computadoras en su red o cuando necesita ejecutar varias instancias de Ollama en puertos diferentes.
Esto es útil en entornos de desarrollo cuando se accede a la API desde diferentes dispositivos o al ejecutar Ollama en un entorno con contenedores.
OLLAMA_MODELS
Esta configuración es fundamental cuando desea almacenar los modelos en una ubicación distinta de la predeterminada.
Es útil al mover modelos a una unidad de mayor capacidad desde la unidad local, compartirlos entre diferentes instalaciones de Ollama y mantenerlos en una ubicación específica para fines de respaldo o cumplimiento.
Solución de problemas
A continuación, se presentan los problemas comunes y sus soluciones.
1. Error "Command not found":
- Asegúrese de que Ollama esté instalado correctamente.
- Verifique si la variable de entorno PATH incluye Ollama.
- Reinicie la terminal.
2. La descarga del modelo falla:
- Verifique su conexión a Internet.
- Compruebe que tenga suficiente espacio en disco.
- Intente ejecutar el comando ollama pull mistral.
3. Alto uso de RAM:
- Ajuste el tamaño del contexto usando la opción --context.
- Cierre otras aplicaciones que consuman muchos recursos.
- Considere usar una variante de modelo más ligera.
Obtener ayuda
- Visite la documentación oficial: https://ollama.ai/docs
- Consulte el repositorio de GitHub: https://github.com/ollama/ollama
- Únase a la comunidad de Discord para obtener soporte
Buenas prácticas
Gestión de recursos
- Supervise los recursos del sistema mientras ejecuta modelos.
- Cierre el modelo cuando no esté en uso para liberar memoria.
- Use tamaños de ventana de contexto adecuados para su hardware.
Consideraciones de seguridad y optimización del rendimiento
- Mantenga Ollama actualizado a la versión más reciente.
- Use aceleración por GPU si está disponible.
- Considere usar modelos cuantizados para obtener un mejor rendimiento.