Initially, network management as a practice solely revolved around overseeing network components like servers, routers, switches, and firewalls. However, as technology progressed and the utilization of cloud environments surged, there emerged a need for more sophisticated management practices. This need entails comprehensive monitoring of cloud infrastructure to accommodate the evolving landscape; eventually, businesses started incorporating cloud-aware network management practices into their strategies.
In this whitepaper, we will dig a little deeper into real-life case studies on how large enterprises moved away from conventional tools and strategies to ManageEngine OpManager Enterprise edition for a cloud-aware network management experience.
Nowadays, virtualization and the cloud have both gathered the support of CFOs, CIOs, sysadmins, vendors, and end users alike—in a way that not many other innovations have. When it comes to virtualization: CFOs understand the costs and benefits; CIOs understand the datacenter consolidations; sysadmins understand how to reduced rack and wiring problems; vendors understand that they have to sell solutions such as cloud-in-a-box, and not just bits and pieces of hardware; and end users, yes even they have to come to terms with IT as they start tasting the benefits of Amazon EC2 for some of their own requirements.
Let's unearth how these innovations gave rise to the need for a new-age, cloud-aware network monitoring software that succeeds at making large enterprise IT management easy.
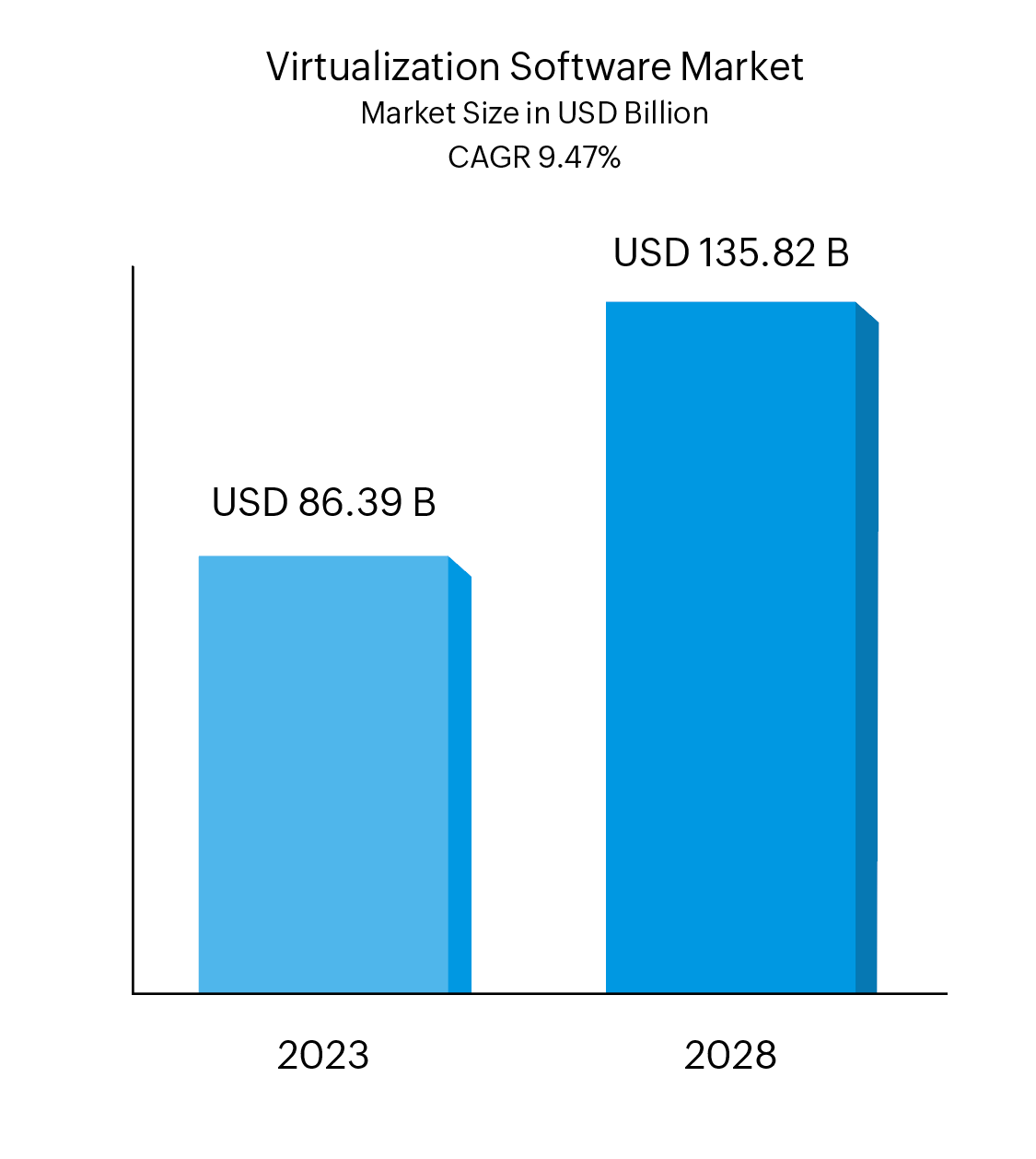
According to Mordor Intelligence, the virtualization market is anticipated to touch 135.82 billion USD by 2028, up from 86.39 billion in 2023 at a CAGR of 9.47%. Transitioning from conventional networks to virtualized networks offers businesses a range of advantages, including:
Virtualization is a part of cloud computing, as virtualization offers a helping hand to allocate and use the resources efficiently. It helps cloud resources to reach high availability and push the performance rate to an optimal range. Virtualization within the cloud not only consolidates storage devices into a unified entity but also enhances overall capacity.

About the company: Leading Health Insurance company in the United States, with datacenters in 10 states and hundreds of branch offices. This company covers half of the enterprises in the US, providing insurance schemes for employees. This company enables agents and employees of various organizations to log into its insurance signup and renewals application to create or renew their insurance plans.
Network details: A fully virtualized VMWARE-based server environment, supported by EMC-based storage and Cisco-based networking devices.
Solution preferred: ManageEngine OpManager Enterprise edition with NCM Plugin
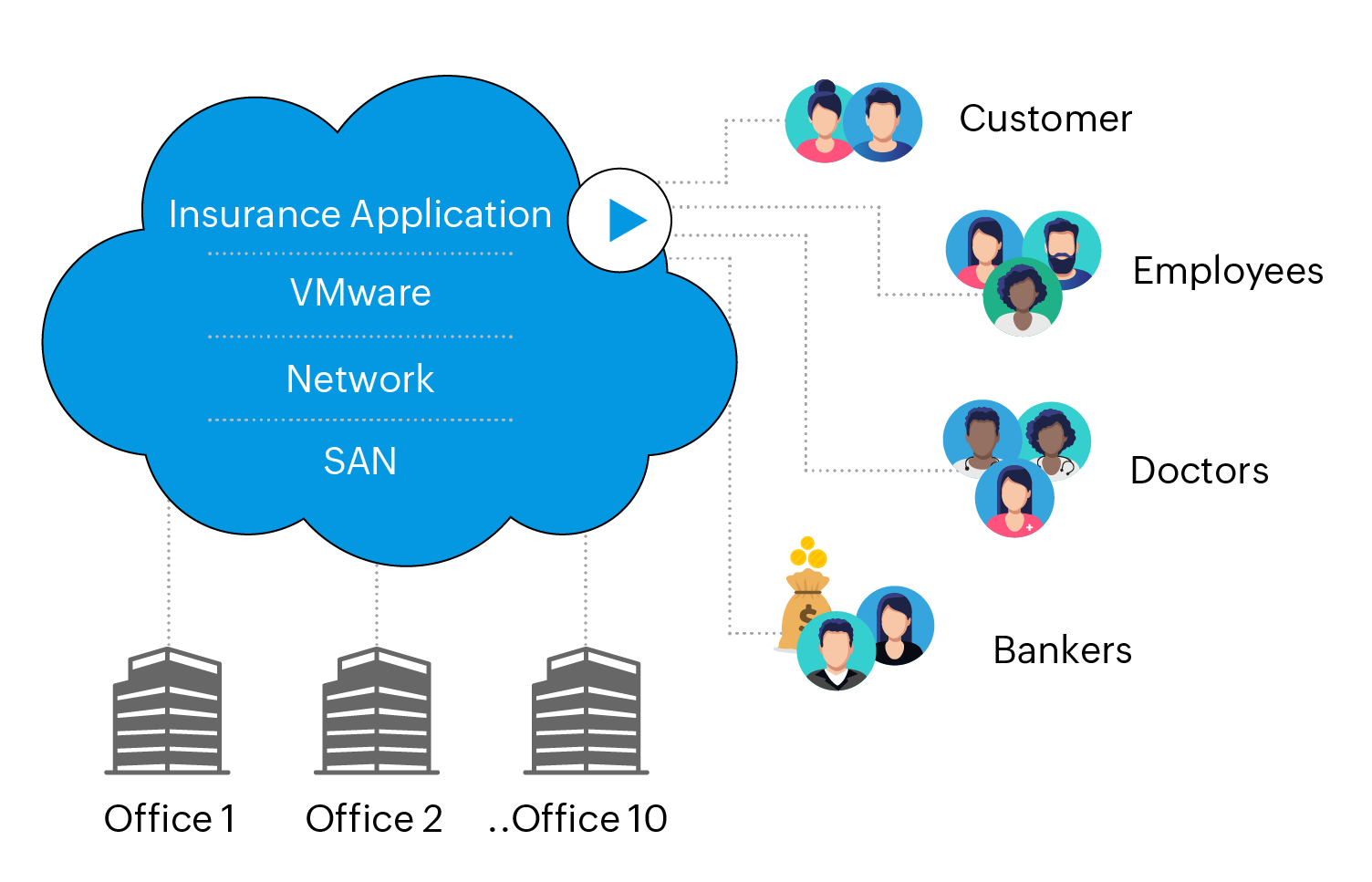
Supporting the networking and infrastructure division of such a large insurance organization can be demanding. With people accessing the corporate network (and the corresponding infrastructure) from everywhere, it would be a nightmare if the application is not available—even for a single minute. The cost of downtime often scales with the size of a business, so eventually an instance of downtime is measured in millions, rather than thousands, of dollars. When downtime exceeds tens of millions a day, it's likely going to be on the news and someone in IT might lose their job.
After moving to a completely virtualized environment, the company's IT team decided to manage that environment with just the existing tools. They thought retrofitting an old age tool to new technology might just work. But it didn’t. The tools didn’t understand the nuances of virtualization and started seeing every virtual machine as just a physical server.
The team then began looking for tools in the market they could get to simplify their job and at a price that is cost-efficient. They now know that getting rid of the existing tools could save them from a million dollar renewal—the money they could put to better use if they get an inexpensive tool.
One of the technicians evaluated OpManager and felt that the probe-central model with virtualization support might be just the right tool to manage their 10 datacenters. They started evaluating the tool and ended up purchasing it for its price, feature set, and its simple user interface.
The OpManager Enterprise edition with the NCM plugin offered them network monitoring, network automation with scheduled backups and firmware upgrades, NetFlow-based bandwidth monitoring, and VMware monitoring.
About the company: A large semiconductor manufacturing company with factories in Germany, Singapore, and New York. The company runs a 1,000 server app, which controls the different stages of the semiconductor chip production at the factory. A huge development team watches the application every second and generates alerts directly to the monitoring tool.
Network details: VMware-based virtualization, Citrix-based handheld devices, and NetApp-based storage, plus tons of networking interfaces.
Solution preferred: ManageEngine OpManager Enterprise edition with NFA, NCM, and APM modules.
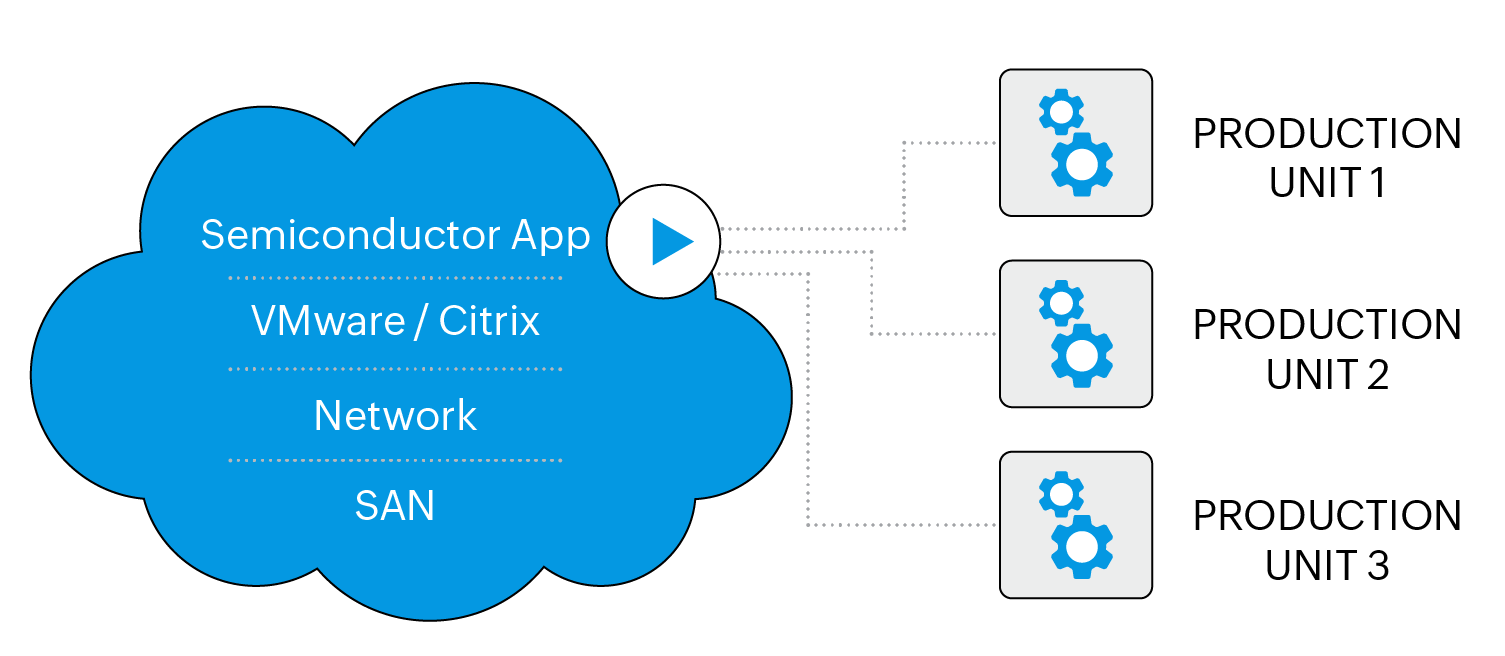
When we think of a manufacturing factory, we often think about robots and conveyor belts but tend not to see the need for IT. On the contrary, the more automated your manufacturing process is, the more IT dependent it is going to be. In the case of chip manufacturing, the company was running a fully virtualized environment over VMware and with thousands of handheld devices from Citrix.
Any outage on the central production application that controls the different stages of the chip production will cause an enormous amount of loss, as the whole set of chips would have to be trashed. The impact of this will be bad due to the size of a factory, as scrapping the raw material in such a vast facility means we are talking about millions of dollars in waste.
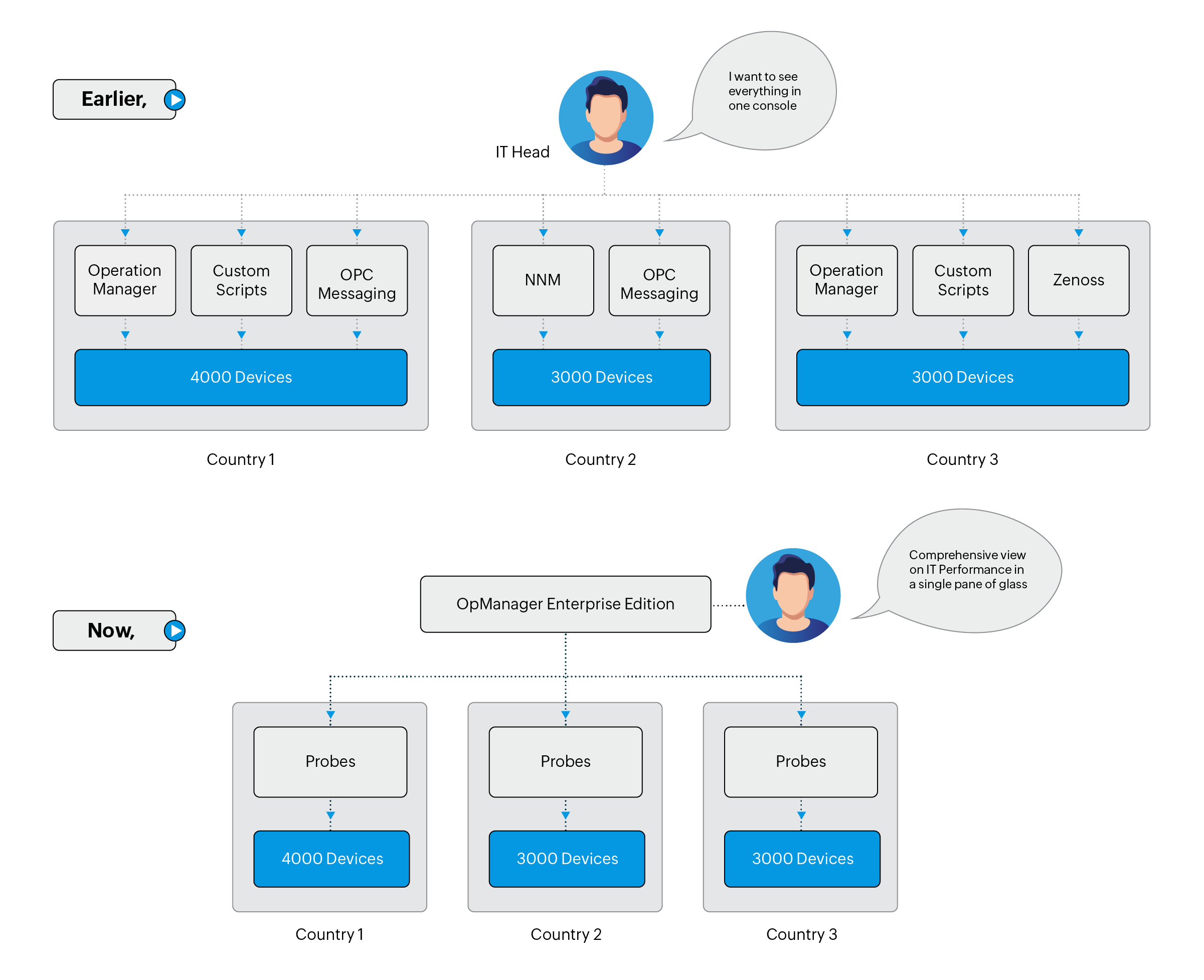
The IT team’s head had a hard time because the facility in each country had its own toolset and they wanted to have a centralized console that could show the status of all three facilities spread across the globe.
When they faced a crossroads, the IT head decided to have control on what’s going on across all branch offices. However, the regional teams wanted to hold on to their own tools.
Eventually, the IT team was convinced to try a different tool that allows global management with a regional touch. They evaluated OpManager Enterprise edition and felt it was a good fit for the global management. OpManager Enterprise offered them server monitoring, bandwidth monitoring, and network configuration management in one bundle.
With probes at each location, they now have a single console that offers the complete picture of their overall IT to the IT head and gives control back to the regional teams. In addition to the server, network, and VMware monitoring they also used the ManageEngine Applications Manager module, which monitors their applications and sends alert into OpManager for a unified console.
They got rid of the old tools with a budget that is less expensive than they previously used. This is how their new architecture looked like after they started implementing OpManager Enterprise at each location.
About the company: A large fashion house with an online store that enables millions of transactions. Its online store is running on VMware-based servers, powering purchase of apparels and other items over the web.
Network details: VMware-based virtualization and NetApp-based storage, plus tons of networking interfaces
Solution preferred: ManageEngine OpManager Enterprise edition with NFA, NCM, and APM modules for end-user experience.
This company is a large fashion house that sells fashion accessories over the web from its online store. With the online store being the only channel for sales, the IT team’s primary task was to find out if the site has any performance issues. Any degradation in customer services would impact revenue quickly and directly. Their online store was on top of their IT pyramid.
The IT team was organized into four major teams: server team, network team, SAN team, and DB team. The major problem was that each team had its own view of IT management and they brought in different tools to the table. From conventional legacy-era tools to some proprietary software for specific storage needs, there were a whole lot of tools for managing the 1,000 devices they had across the two datacenters.
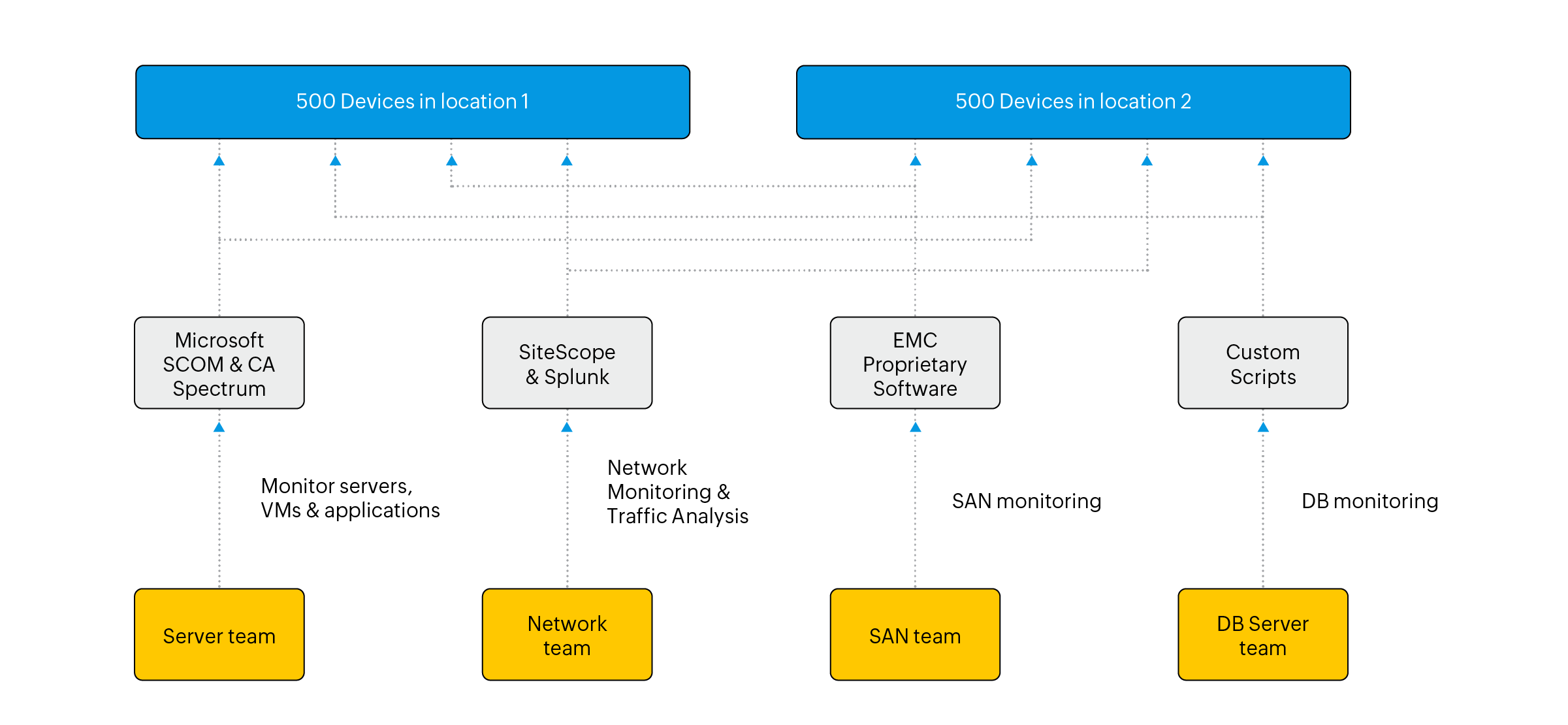
This is what their IT management strategy looked like with multiple tools. Needless to say this approach to monitoring a private cloud datacenter architecture was no good. Soon they started looking for alternatives that were flexible for every team and also offers better cost to performance.
They evaluated OpManager Enterprise edition and felt it was a good fit for all their team’s requirements. Soon those four teams started using the single and efficient tool, OpManager's enterprise console. This is how their new architecture looked like after they started implementing OpManager Enterprise edition.
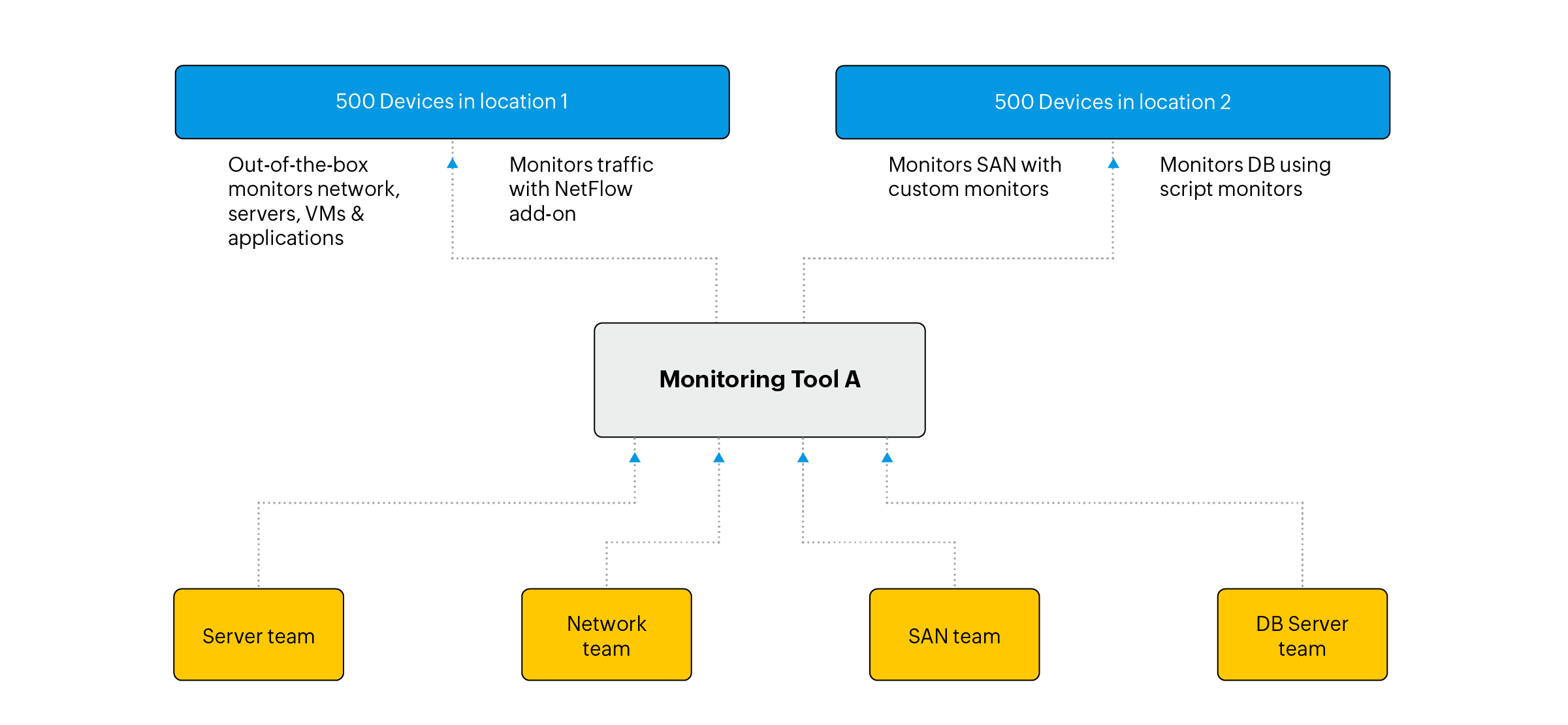
Most large enterprises today are perplexed about retrofitting their conventional tools for private cloud environments or wait until pure-play virtualization tools to evolve and cater to all their cloud management needs. Fortunately there is a better alternative today that offers private cloud monitoring capabilities without compromising on infrastructure and network management, ManageEngine OpManager Enterprise Edition.
From the switch port to the end-user-experience on the application, OpManager can handle everything that’s important for you at all the three levels – Infrastructure, Virtualization, and IT service level. By default around 11,000 device types are supported. VMWare and Hyper-V are supported at the virtualization level. Java/.Net apps, Oracle/Cassandra, URLs and End-user-experience monitoring supported at the App level.
Extendable modules that offer in-depth functionality in areas that you need. Netflow based bandwidth monitoring, Router backup and configuration manager, IP address manager, and End-user experience plus applications manager.
Out-of-the box support for VMWare and Hyper-V hypervisors. OpManager have several monitors and in-built reports that make virtualization monitoring a breeze.
Truly distributed monitoring with a secure probe-central model that offers both alerts as well as reports on the central console with inbuilt high availability options that doesn’t cost you additional burden on budget.