Enterprises employ several mechanisms to optimize the performance of their networks inorder to ensure high availability. Clustering for failover (Active /Passive mode) and load-balancing (Active / Active mode) is a commonly adopted technique that supports redundancy, session or database replication, and load balancing requests across the servers in the cluster. Some networks have software or hardware load-balancers even outside the cluster to increase horizontal scalability.
Most businesses happen over the Internet and Enterprises prefer clusters or invest in load-balancers because of the fault-tolerant architecture. Critical servers and applications such as database servers, exchange servers etc are hosted in clustered environment for high availability. Further, load balancers like Big IP are plugged into the network to distribute the load on servers to address the primary need of un-interruped availability at all times. Service interruptions, planned or unplanned, are costly affairs and are unacceptable for businesses of any size. Administrators exhaust almost every resource within their means to keep their networks happy and available.
We are all huge consumers of various services the internet supports. Imagine a situation where you are accessing your bank account to transfer funds to a friend's for an emergency. And the site simply says, 'Oops! Sorry, the service is unavailable!'. The message concludes politely requesting you to try accessing after a little while. As end users, we would hate to be in this situation. That you get to call the customer service and bombard at random and look out for an ATM or a branch office is some respite. The damage caused to the bank is beyond economic repairs and the man behind the show, the administrator/network engineer gets to listen to variety music for this huge goof-up. This despite having invested in a cluster for a reliable service!
The job is only half-done by employing clustering for failover or load-balancing. Unless an administrator has a clear visibility of the good, bad, and the ugly components of his network including the ones in that critical cluster, or the important resources on the expensive load-balancers, its impossible to have an alert-free holiday!
Example 1: A two-node SQL cluster in an enterprise
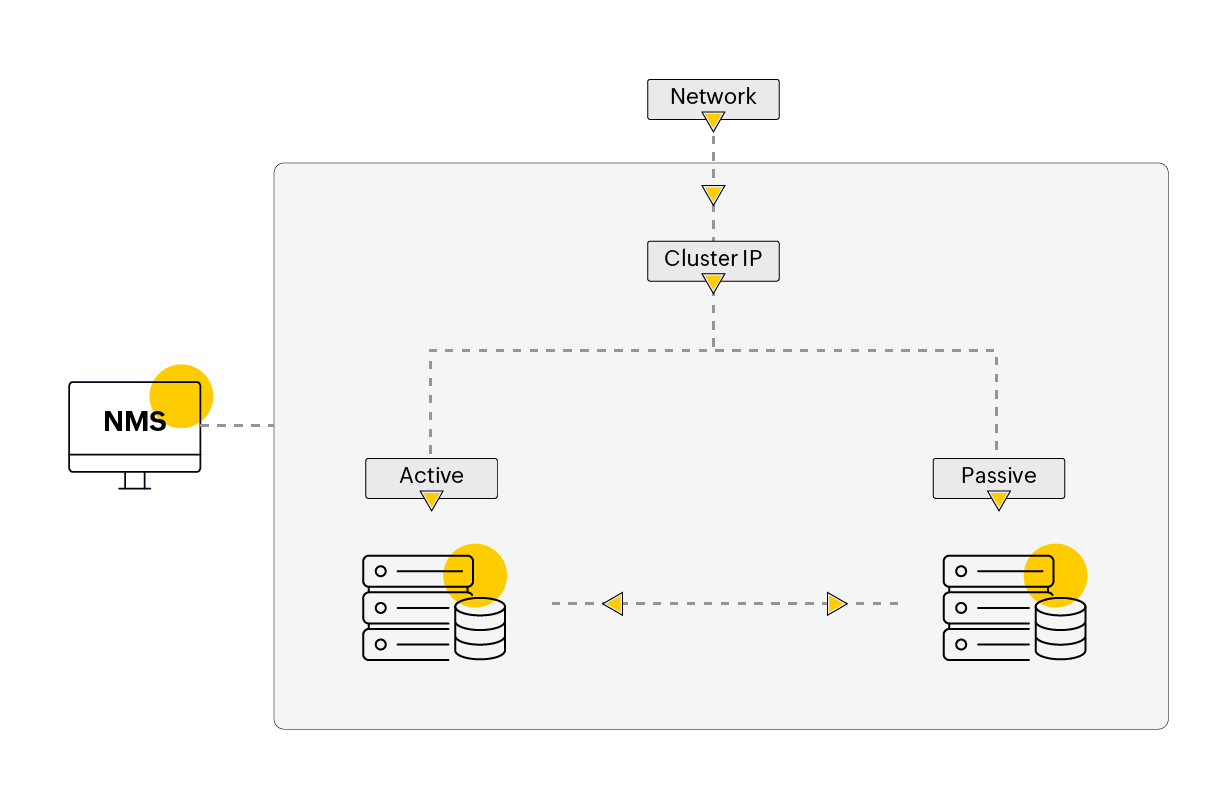
The reasons for an Active node to failover to a standby could be either a system or an application failure, or both. An administrator must have a clear visibility into the system and application performance, which is possible only when proactively monitored. In the scenario discussed above, it is possible that the clustering controller instance has failed causing the whole system to fall apart! Or, despite the Active node successfully failing-over to the Passive, the Passive too fails due to insufficient resources! This mix-up could have been avoided or identified a little earlier to reduce the damage by monitoring the basic resources on these systems.
Example 2: A load-balancer distributing requests across a few servers:
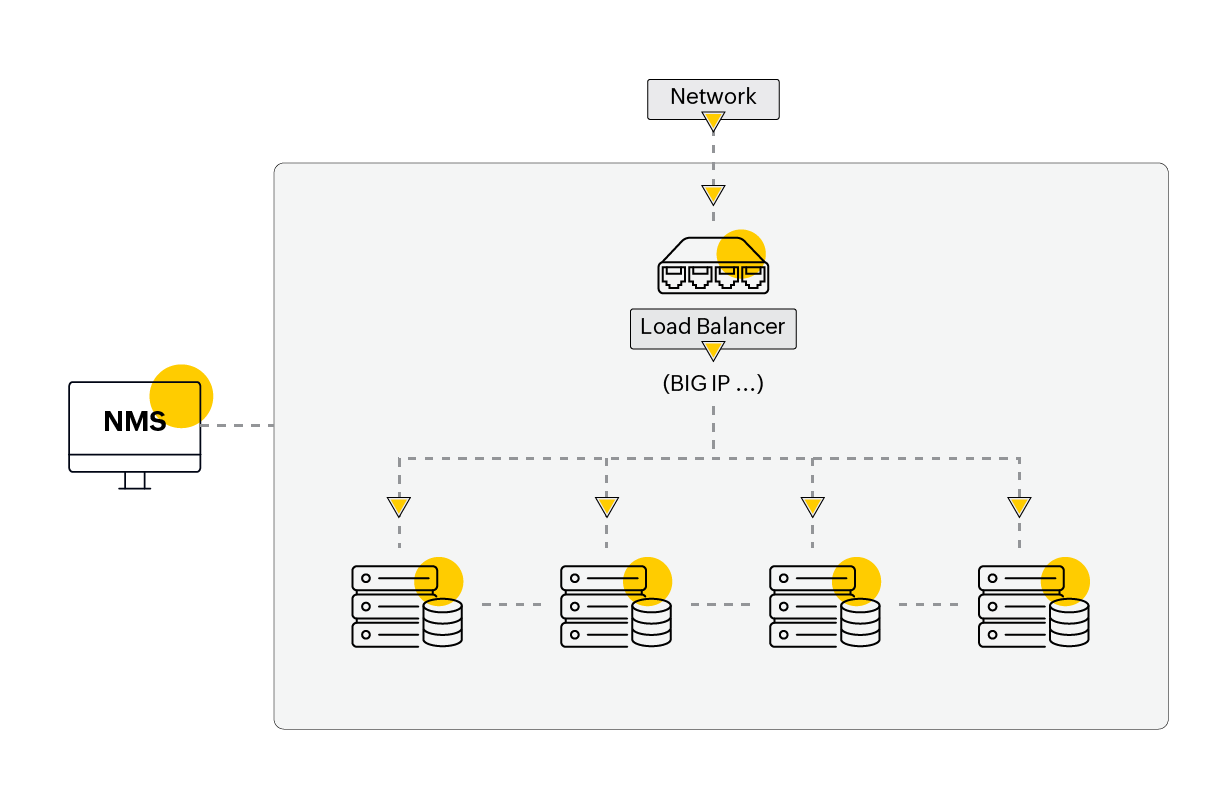
Despite reduntant servers set up for load-balancing, imagine a hardware resource failure on the load-balancer leading to the service unavailability! The user requests never make it to the server even when the service is up and running fine!
The purpose of clustering is lost if the resources are not constantly monitored. Even as the administrator tries to ensure that the end-users do not 'feel' any service failure, he must quickly identify the cause for the failover from active to the passive node, or why the load exerted on a particular server is on the high. So, all the components or resources that need to run for the clustering to work well, needs monitoring. This includes the Cluster service on the nodes, the dependent services, the system resources on the load-balancer, response time of the individual devices etc.Contant automated monitoring of key components helps reduce the damage and helps realize the goal of ensuring high availability at all times.
The key resources include:
Availability of the nodes: A detailed availability report indicating if the node is unavailable due to a dependent device failure or if the node is pulled down for maintenance.
Response time of the nodes: Response time of the nodes at any given time, and its average response time indicating the load on it.
Services availability and response time: Availability of the cluster service and its related services on the nodes.
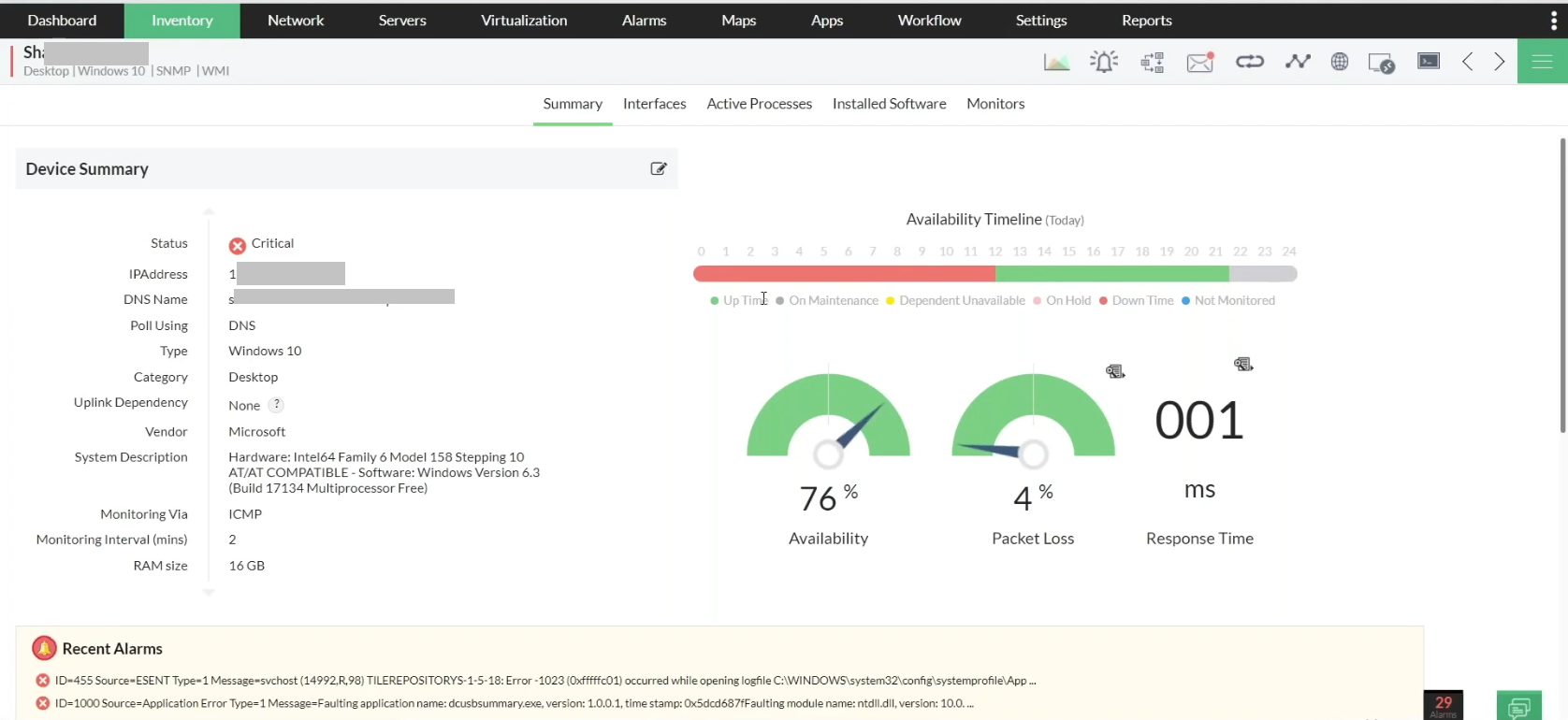
System Resource utilizations: A constant check on the performance of the hardware resources because the last thing you want is insufficient resources rendering a critical service unavailable!
Service Parameters: Critical parameters of a service that can lead to a potential failure.
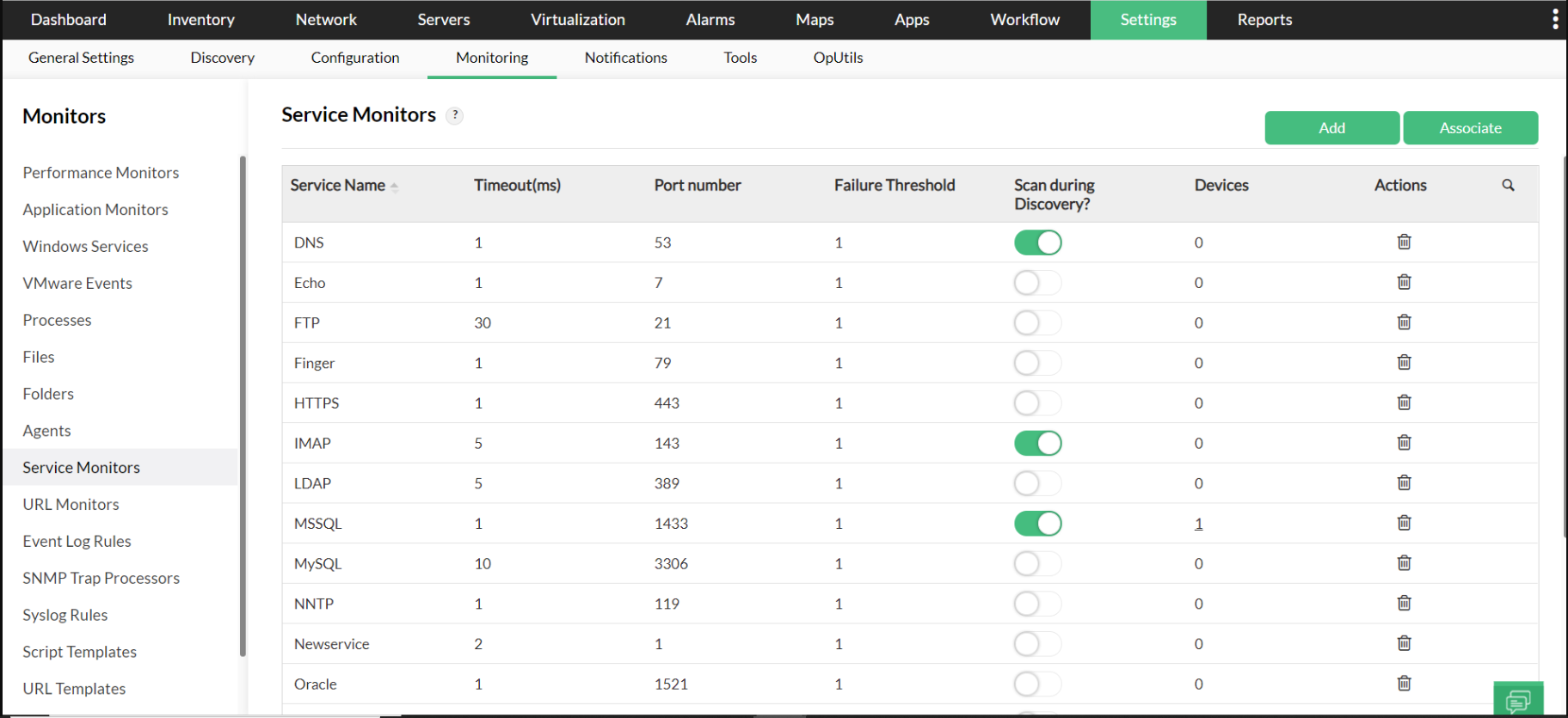
System Events pertaining to the cluster: Keeping a tab on the system events including the application events so that there are no sudden surprises and all avenues of fault are watched.
Availability and Performance of the load balancer: Ensuring the basic availability and responsiveness of the load balancer.
System resources on the load balancer: Monitoring the critical resources on the load-balancers to identify and problem indicators much ahead.
Cluster Groups (Business Views): A holistic view of the nodes in a cluster with an ability to drill down to the root cause. This provision to visualize a cluster helps to understand the health of the cluster at a glance.
ManageEngine OpManager is a network monitoring software that monitors all the resources on your LAN and WAN. The performance and fault management capability of OpManager helps identify performance bottlenecks quickly. Its ability to drill-down to the root cause of a fault and the huge custom-capability, makes OpManager a preferred solution among thousands of network administrators world-wide. A few useful plug-ins and add-ons such as NCM Plug-in, NetFlow Plug-in, VoIP add-on, and the provision to easily integrate with other applications in the ManageEngine suite such as ServiceDesk Plus, makes it a one-stop shop for all your network and IT management needs.