Organizations rely heavily on business-critical networks and their underlying infrastructure for seamless service delivery. Apart from the hardware deployed on their networks, they also have a huge array of software-defined network components at their disposal, like databases, applications, firewalls, controllers, etc.
With an increased dependence on these digital assets, it is critical that these resources be continuously available. Organizations cannot afford major failures or downtime in regard to these resources because, if they go down, the associated services remain unavailable until the failure is fixed, costing the organization heavily.
One way to remedy this is by the use of high availability systems. High availability is a concept that aims to achieve a high level of dependability or operational performance (in this case, availability) and is fault tolerant to keep the network infrastructure running without downtime.
Learn more on how to configure devices for high availability monitoring in OpManager.
Despite using highly resilient network components, no system is 100% fail-proof. Failures can occur because of any unexpected reason including overloads, power failure, network disconnections, unscheduled maintenance, etc. The goal of high availability is to ensure minimal or zero downtime so that these failures do not affect the bottom line of business operations, which would result in data and monetary losses.
IT admins utilize high availability together with fault resolution metrics like mean time to repair (MTTR) and mean time between failure (MTBF) to minimize downtime and maintain high overall network availability.
To design and build systems with continuous availability, you must consider these critical principles:
Continuously monitoring and managing business-critical network components is crucial to achieving and sustaining high availability. ManageEngine OpManager, an integrated network monitoring tool, helps you deploy and monitor high availability systems, and offers a wide range of other network monitoring features. High availability systems in OpManager can be configured with either the active-active mode or the active-passive mode.
With the latest version of OpManager, you can effortlessly configure, monitor, and manage the following categories of devices with high availability:
OpManager uses availability monitoring protocols to check for the availability of network components and devices configured for high availability as well. The devices are polled using ICMP, and on the basis of the response received, OpManager keeps track of the uptime of these devices. For an active-active configuration, both devices are polled separately and monitored for availability and performance independent of each other. In an active-passive case, however, the secondary device is monitored only for availability since it is on standby.
Being able to identify failures as they occur is critical for IT admins. This helps them take necessary steps to rectify failures before substantial damage is dealt. OpManager's alert-based fault indication gives you insights into the availability of the devices configured with high availability by raising an alarm whenever any device goes down. The architecture of alarm generation varies based on the configuration mode used for to set up the devices.
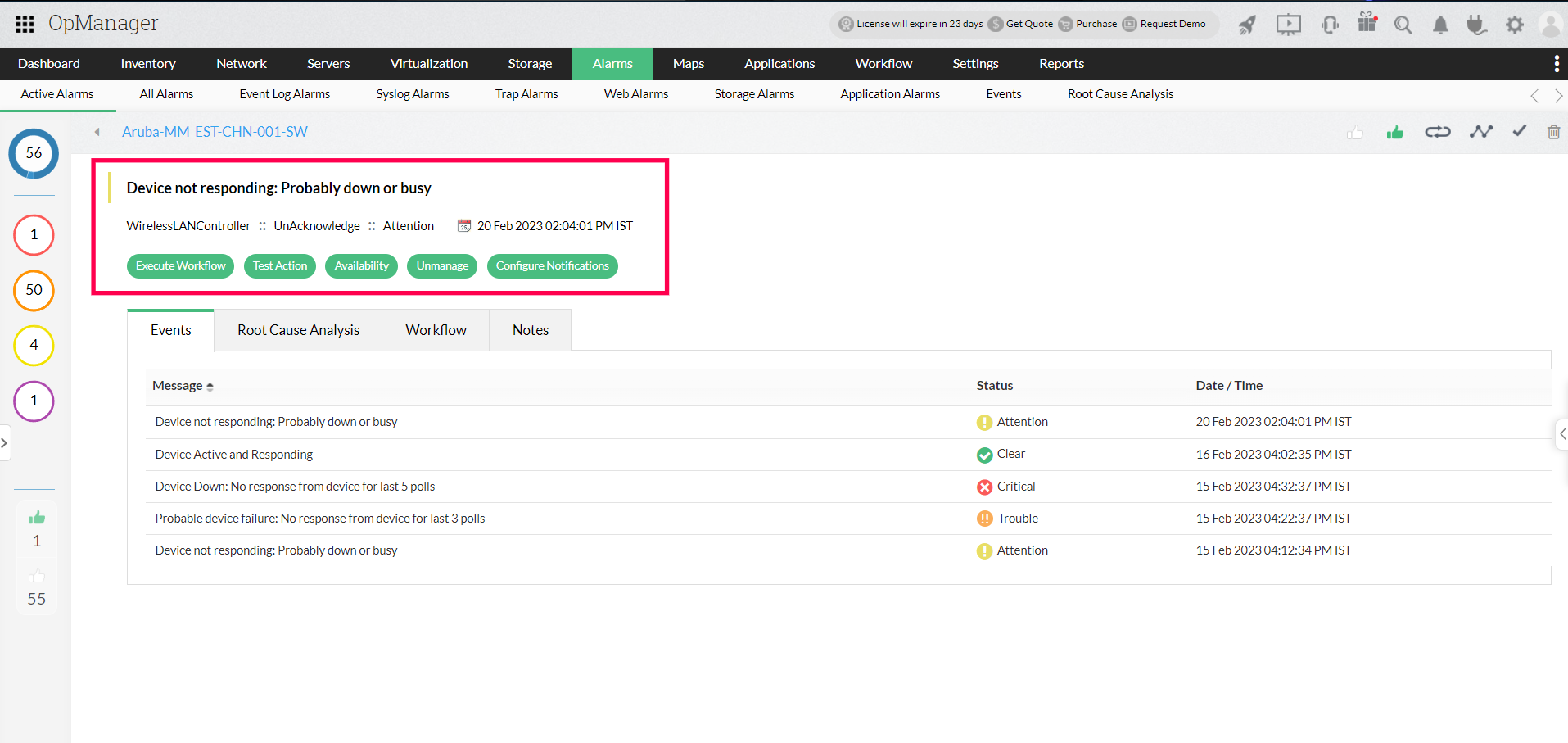
Alarms in an active-active setup
In an active-active configuration, both the devices are polled for availability, and an alarm is raised if either of the devices fail to respond to a ping. With each consequent failed ping, another alarm is raised with increasing severity, notifying the administrator of the unavailability of the corresponding device.
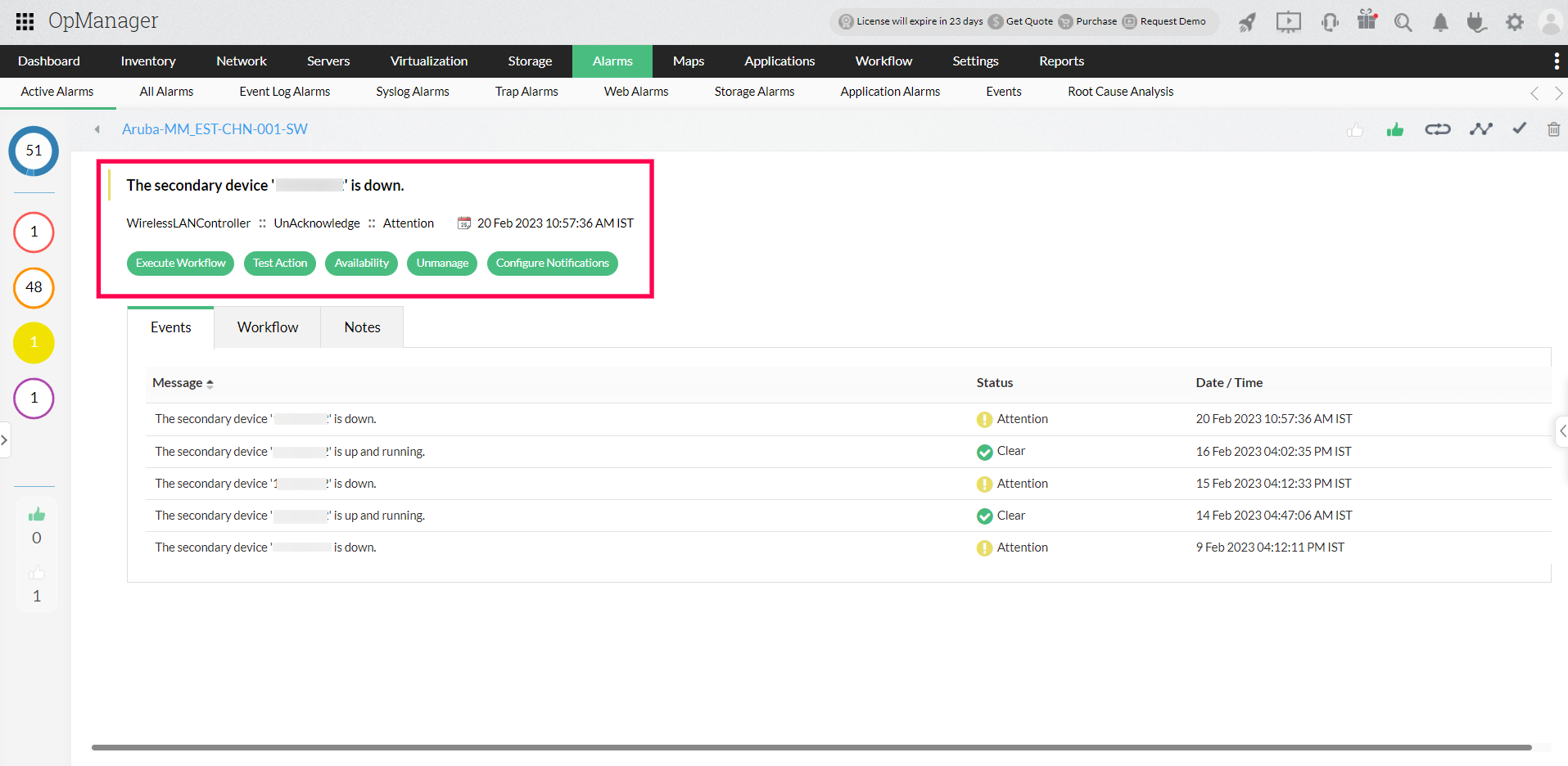
Alarms in an active-passive setup
Contrary to an active-active configuration, in an active passive setup, one node is always active while the secondary node is always on standby. In this case, if the secondary node goes down, the primary node will be left with no backup; so an alarm will be raised for the primary device to notify the administrator about the unavailability of the secondary device.
Likewise, if the primary goes down, an alert is raised, notifying the admin of the device's unavailability, and polling is resumed through the configured secondary IP. If, however, both the primary and the secondary devices are down, alerts are raised with increasing severity until one of them is available for service.
With the latest update to OpManager, you can configure notification profiles to help with high availability monitoring. Notification profiles are an advanced class of alarm systems that let you choose the type of alarm raised and predefine the action to be performed in the event of a Notification Profile trigger. With this feature, high availability clusters can be integrated with an email and SMS-based notification system that alerts the user in case of a failure. This helps you maintain true high availability and minimal downtime.
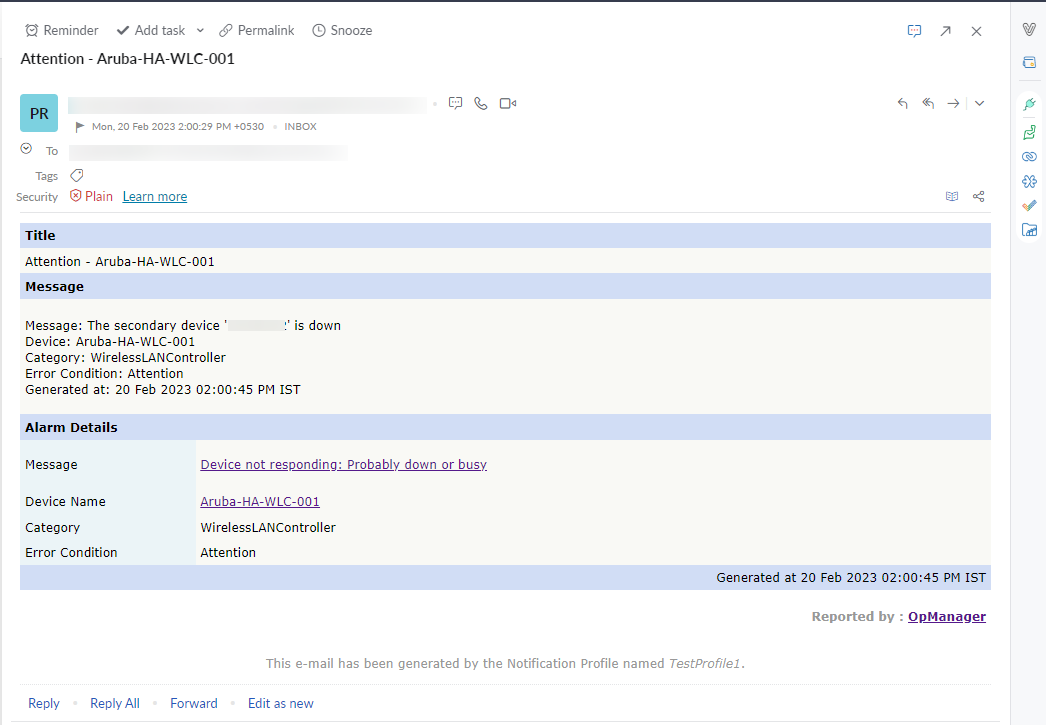
Note: During the configuration of a notification profile, you must add both the primary and secondary devices to monitor an active-active setup. For an active-passive setup, adding just the primary device is enough.
Try OpManager's demo to check out its high availability monitoring capabilities yourself, or download a 30-day, free trial to explore other features of this top-of-the-line network monitoring software.