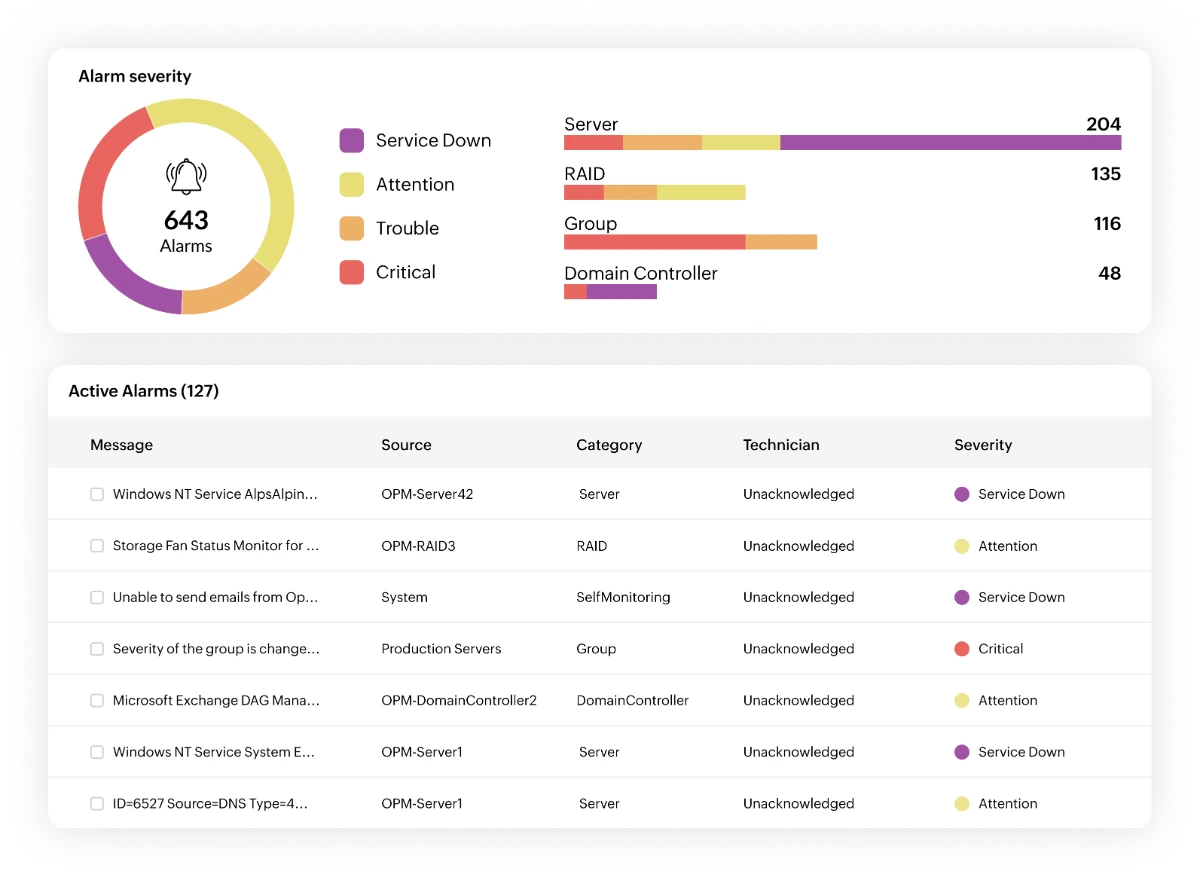
ML-powered anomaly detection for smarter alerts
Instantly identify critical incidents and eliminate alert noise across your network.
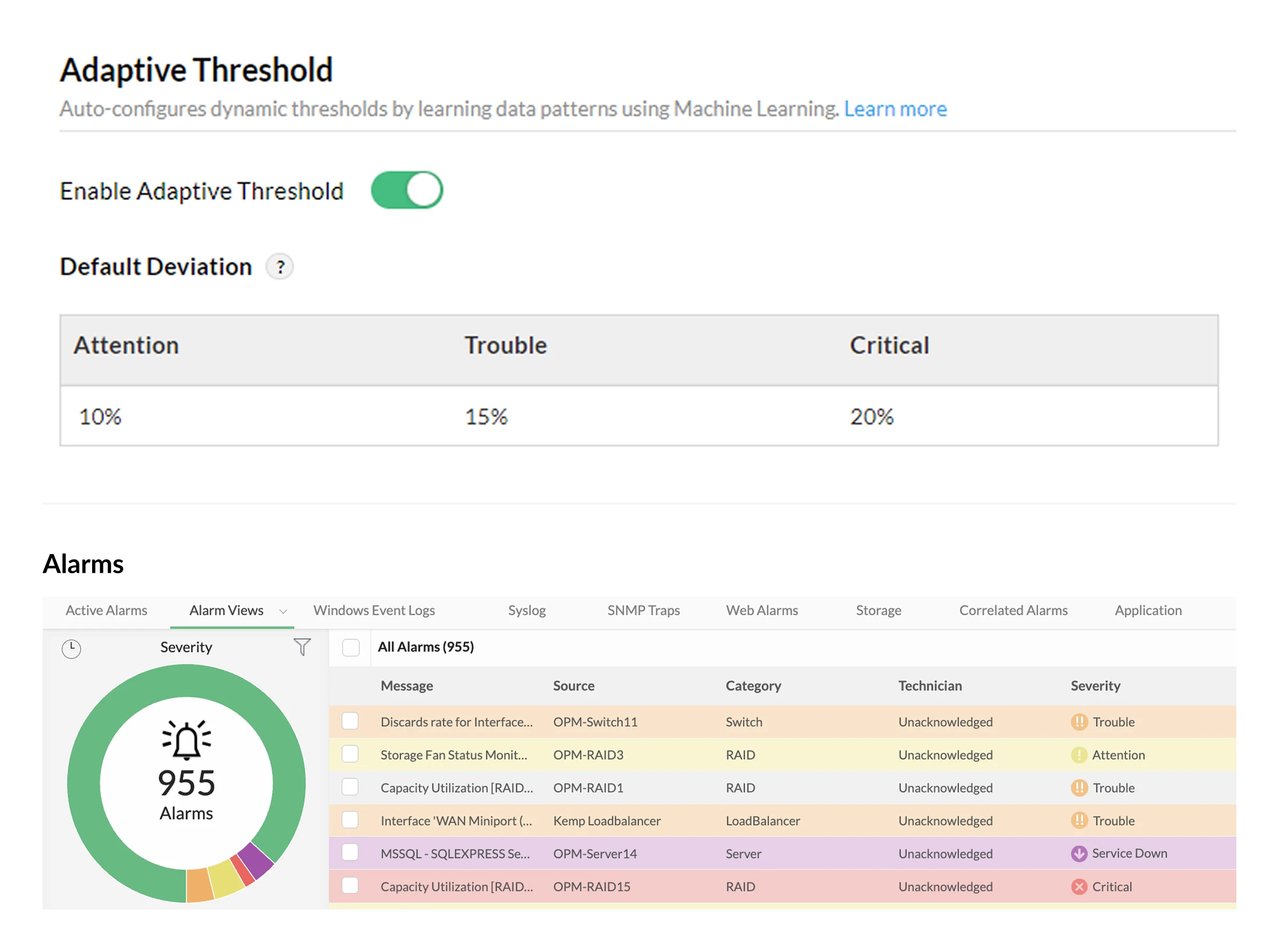
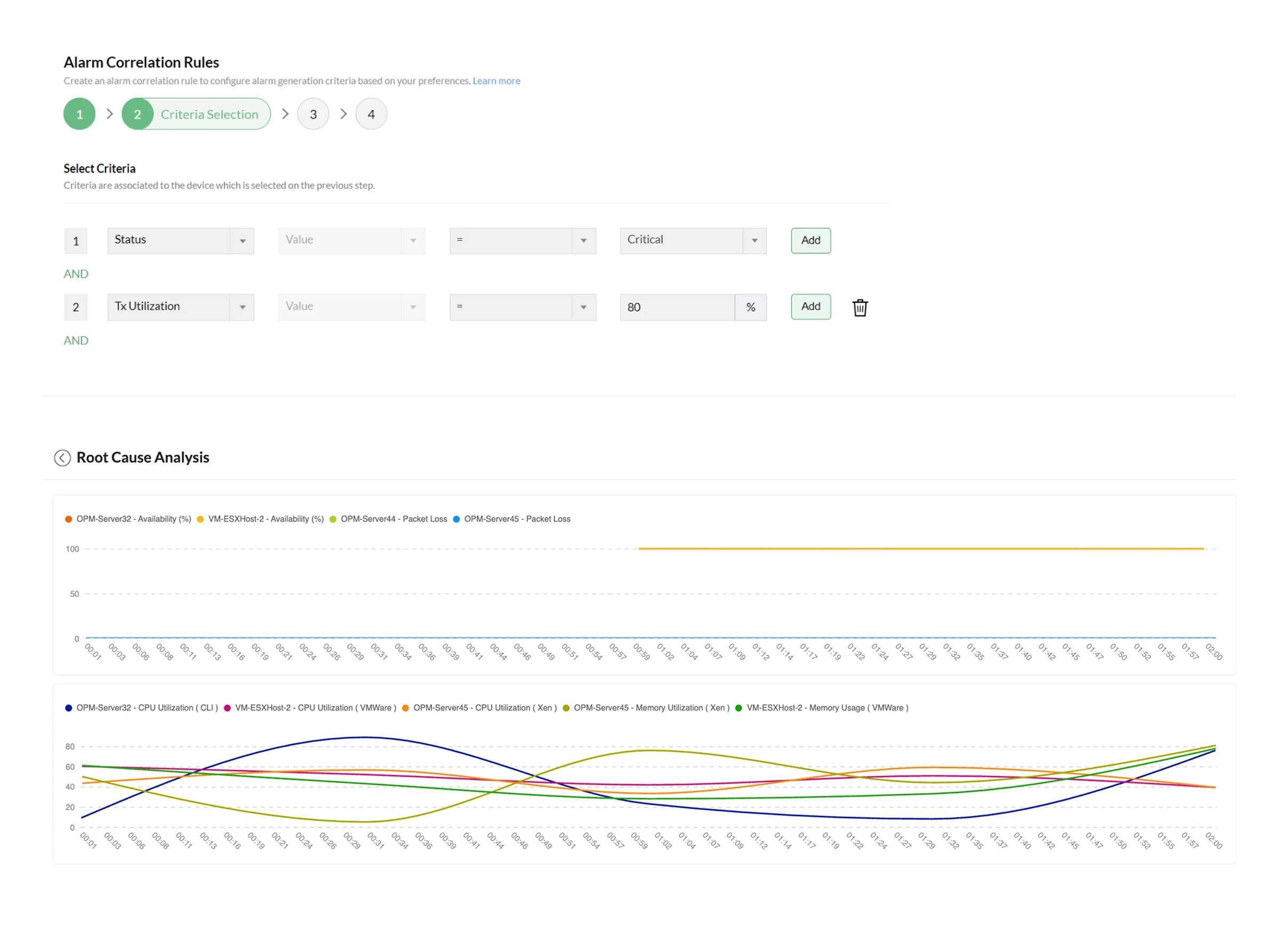
- Detect real anomalies with ML-driven alerts:Machine learning continuously learns normal network behavior and triggers network alerts only when meaningful deviations occur, helping teams prevent unexpected disruptions.
- Focus on what matters, silence what doesn't: Alerts are automatically categorized into Critical, Trouble, Attention, and Service Down, so teams instantly know what impacts revenue and customer experience. No more wasting time on low-priority noise.
- Gain full visibility with a contextual alarm console: View all alerts in a centralized console, filter them by severity, technician, or category, and use contextual alert details to quickly triage and resolve incidents.